
揭晓高速公路场景下计算机视觉与交通的秘密
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
高速公路场景基于计算机视觉的车辆检测和流量统计

1、文章信息

2、摘要
3、简介
4、创新点
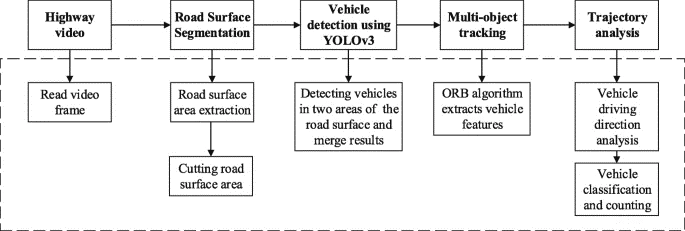
数据集:建立了高速公路车辆的大规模高清数据集,该数据集可以提供许多不同的车辆目标,这些目标在高速公路监控摄像机捕获的各种场景下进行了完全标注。在处理车辆尺寸变化时,该数据集可用于评估许多车辆检测算法的性能。 目标检测:为了提高车辆检测的准确性,提出了一种在高速公路场景下检测小目标的方法。提取公路表面区域,分为远端区域和近端区域,并分别放入卷积网络进行车辆检测。 目标跟踪:提出了一种针对高速公路场景的多目标跟踪与轨迹分析方法。通过ORB算法提取并匹配检测目标特征点,并确定道路检测线以确定车辆的移动方向和统计交通流量。
5、主体内容
车辆数据集
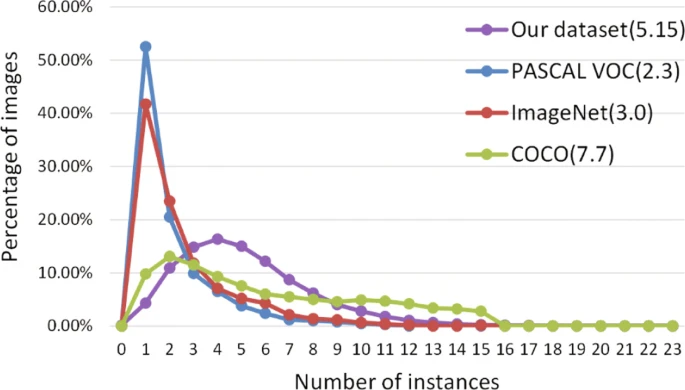
文中是整理了前人的6类车辆数据集,分别为the KITTI benchmark dataset(http://www.cvlibs.net/datasets/kitti/ ) 、the Tsinghua-Tencent Traffic-Sign Dataset(http://cg.cs.tsinghua.edu.cn/traffic-sign/ )、the Stanford Car Dataset(http://ai.stanford.edu/~jkrause/cars/car_dataset.html )、the Comprehensive Cars Dataset(http://mmlab.ie.cuhk.edu.hk/datasets/comp_cars/index.html )、the BIT-Vehicle Dataset(http://iitlab.bit.edu.cn/mcislab/vehicledb )、the Traffic and Congestions (TRANCOS) dataset(http://agamenon.tsc.uah.es/Personales/rlopez/data/trancos/ )。虽然以往已经公开了大量数据集,但是针对中国车辆、中国高速公路交通场景以及提供大量完整的标注的高质量的数据集几乎没有。所以作者提出了他的高速公路监控视频数据集(http://drive.google.com/open?id=1li858elZvUgss8rC_yDsb5bDfiRyhdrX 谷歌云盘下载),数据集图片来自中国杭州的高速公路监控视频。这些图像覆盖了公路的远处,包含了比例发生巨大变化的车辆。数据集图像是从23个不同场景、不同时间和不同照明条件的监控摄像机中捕获的。该数据集将车辆分为三类:小汽车(42.17%)、公共汽车(7.74%)和卡车(50.09%),以及其他具体情况如下图。最后作者为了展示自己数据集的优势,将数据集中的注释实例数与PASCAL VOC,ImageNet和COCO数据集进行了对比,如下图所示。

目标检测
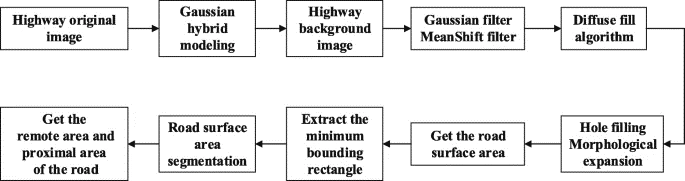
 检测图像预处理-道路表面提取和分割
检测图像预处理-道路表面提取和分割



车辆检测-yolov3

目标跟踪
多目标跟踪-ORB
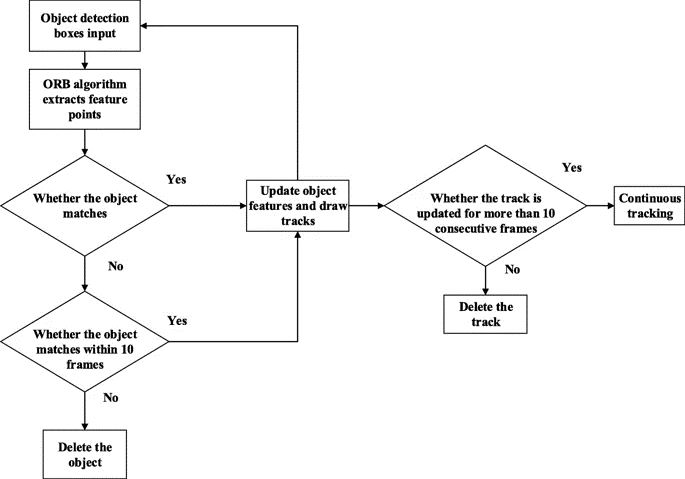
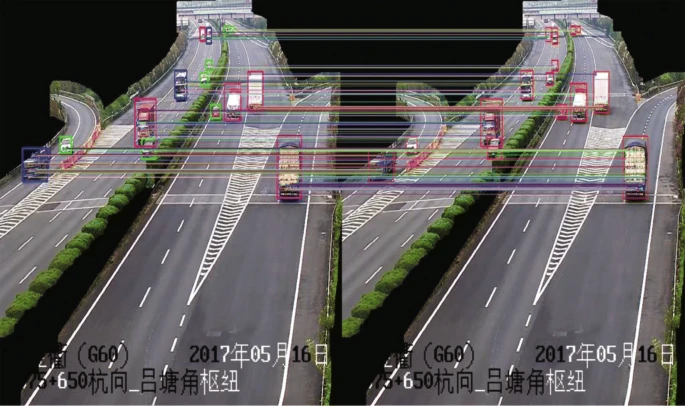
6、结果和分析
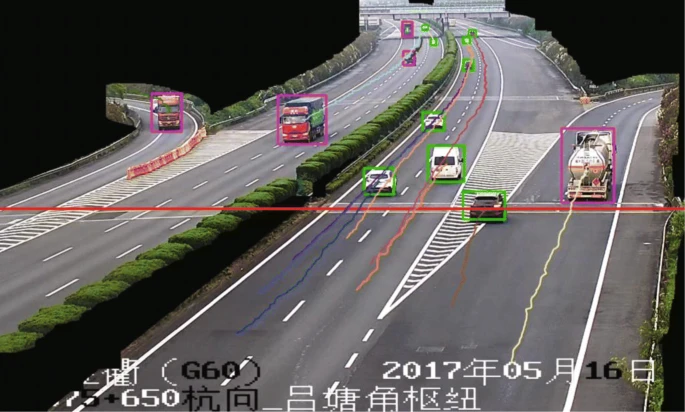
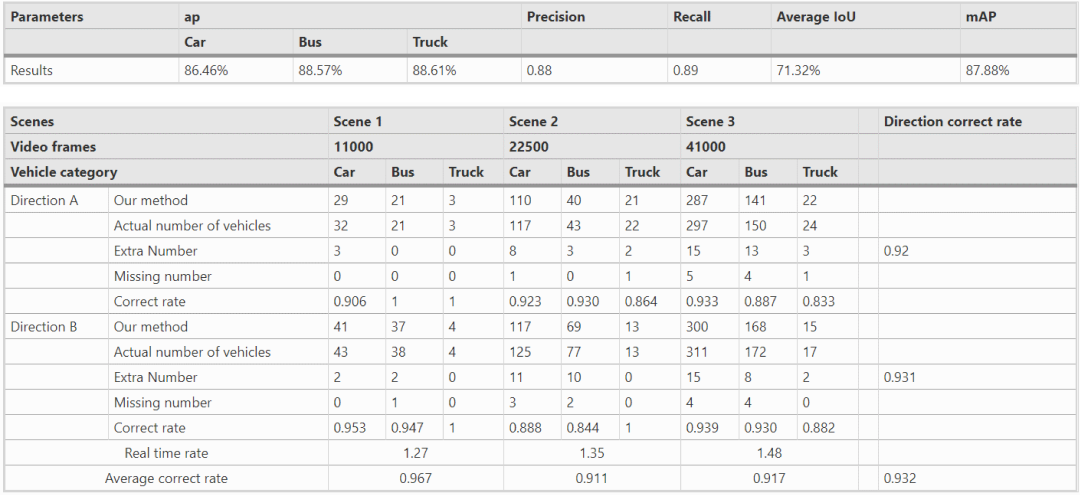
本期编辑:大连理工大学 龚云海
邮箱:gongyunhai@mail.dlut.edu.cn
下载1:OpenCV黑魔法
在「AI算法与图像处理」公众号后台回复:OpenCV黑魔法,即可下载小编精心编写整理的计算机视觉趣味实战教程
下载2 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

觉得有趣就点亮在看吧
