
Pandas用到今天,没成想竟忽略了这个函数
导读
Pandas曾经一度是我数据分析的主力工具,甚至在当下也是很多情况下的首选。作为Python数分三剑客之一,Pandas素以API丰富著称,个人也是常常沉醉于其中的各种骚操作而不能自拔(好吧,有些言重了)。近日,发现了一个前期一直忽略了的函数,仔细探索之下,发现竟然还有一些好用的功能,这个函数就是——transform。

transform是Pandas中的一个函数,既可组用于Series和DataFrame,也可与groupby联用作用于DataFrameGroupBy对象,所以本文主要介绍transform的两个主要功能:
元素级的函数变换
与groupby配套统计(维度无reduce,可参考窗口函数)
首先来看下transform的官方文档介绍:
def transform(obj: FrameOrSeries, func: AggFuncType, axis: Axis, *args, **kwargs-> FrameOrSeriesUnion:"""Transform a DataFrame or SeriesParameters----------obj : DataFrame or SeriesObject to compute the transform on.func : string, function, list, or dictionaryto compute the transform with.axis : {0 or 'index', 1 or 'columns'}Axis along which the function is applied:0 or 'index': apply function to each column.1 or 'columns': apply function to each row.Returns-------DataFrame or SeriesResult of applying ``func`` along the given axis of theSeries or DataFrame.
从函数签名可以看出,transform主要包括2个指定参数func和axis,其中func即为接收的处理函数,可以是函数对象、函数名字符串、函数列表以及字典函数等;axis即为作用的轴向;另有*args和**kwargs用于接收func函数的可变长参数及字典参数。
在前期推文Pandas中的这3个函数,没想到竟成了我数据处理的主力一文中,重点介绍了apply、map以及applymap共3个函数的常用用法,那么transform的第一个功能颇有些map+applymap的味道:其中,map是只能用于Series对象的元素级变换,applymap则是只能用于DataFrame对象的元素级变换,但却要求必须所有函数都只能做相同函数处理,这又多少有些受限。
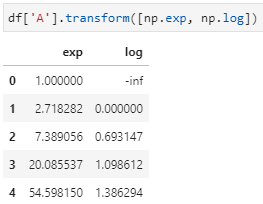
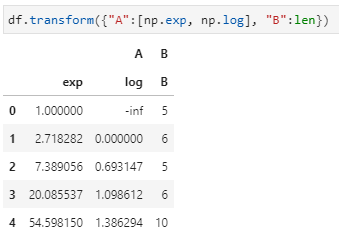
上述例子中未声明axis参数,此时默认axis=0,即传递的函数是按列起作用。下面我们再举个例子,尝试一下axis=1的效果:
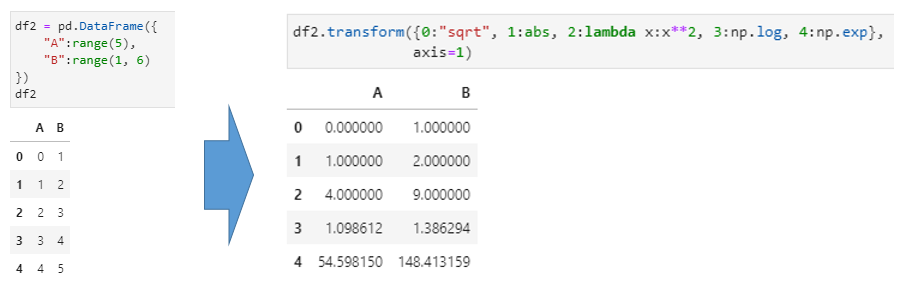
在这个例子中,通过传入axis=1这一参数,实现了对不同行调用不同函数的处理效果,且这里的函数包括传递字符串形式、函数对象以及lambda表达式等3种形式。
以上,其实transform实现的又何尝不是map或者applymap的效果呢?但又远比二者功能更具定制化。
transform可用于groupby对象,这是我最初学习transform的作用,在Pandas中groupby的这些用法你都知道吗?一文中其实也有所介绍,所以此处就简单提及。
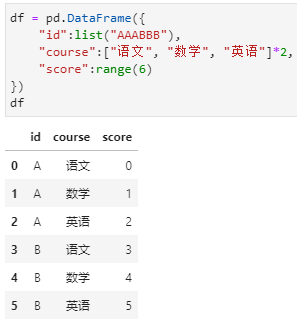
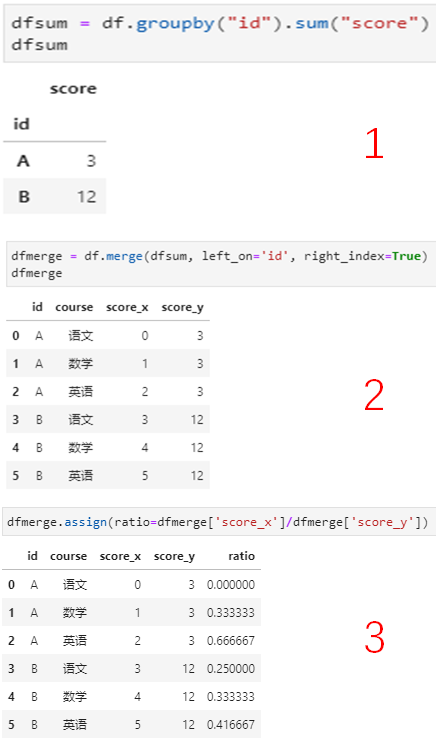
需要统计每个id各门课成绩的占比,如果用常规的聚合统计的思路需要用3步实现:
df.groupby("id").sum("score"),得到每个id的成绩总和
df与上述结果按照id进行merge,得到关联后的score和总成绩
score列与总成绩相除,得到占比
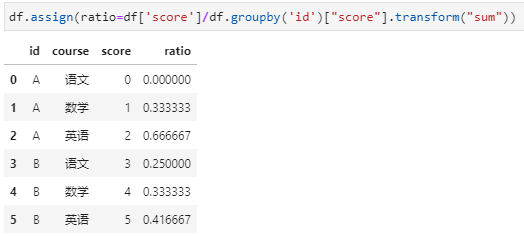
这个实现起来就很爽了,对吧!
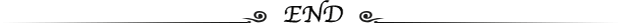
相关阅读: