
独家 | 浅谈Python/Pandas中管道的用法

作者:Gregor Scheithauer博士 翻译:王闯(Chuck)
校对:欧阳锦
本文约2000字,建议阅读5分钟
本文介绍了如何在Python/Pandas中运用管道的概念,以使代码更高效易读。

简介
什么是管道?
使数据处理的顺序结构化为从左到右(而不是从内到外);
避免嵌套函数的调用;
最大限度地减少对局部变量和函数定义的需求;
可以轻松地在数据处理序列中的任何位置添加步骤。
foo_foo_1 <- hop(foo_foo, through = forest)foo_foo_2 <- scoop(foo_foo_1, up = field_mice)foo_foo_3 <- bop(foo_foo_2, on = head)
foo_foo %>%hop(through = forest) %>%scoop(up = field_mice) %>%bop(on = head)
bop(scoop(hop(foo_foo, through = forest),up = field_mice ),on = head)
foo_foo_1 = hop(foo_foo, through = forest)foo_foo_2 = scoop(foo_foo_1, up = field_mice)foo_foo_3 = bop(foo_foo_2, on = head)
foo_foo.hop(through = forest).scoop(up = field_mice).bop(on = head)(foo_foo .hop(through = forest).scoop(up = field_mice).bop(on = head))
https://r4ds.had.co.nz/pipes.html?q=pipe#pipes
Python中的无缝管道(即方法链)
读取数据集并导入相关包
# import libsimport pandas as pd# read datamelb = pd.read_csv("../01-data/melb_data.csv")# Have a quick look at the data(melb .head())
图片来自作者
筛选,分组并生成新变量
(melb.query("Distance < 2") # query equals filter in Pandas.filter(["Type", "Price"]) # select the columns Type and Price.groupby("Type") .agg("mean").reset_index().set_axis(["Type", "averagePrice"], axis = 1, inplace = False))
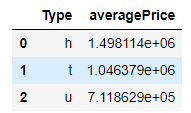
图片来自作者
(melb.query("Distance < 2 & Rooms > 2").filter(["Type", "Price"]).groupby("Type").agg(["mean", "count"]).reset_index().set_axis(["Type", "averagePrice", "numberOfHouses"],axis = 1, inplace = False) .assign(averagePriceRounded = lambda x: x["averagePrice"].round(1)))
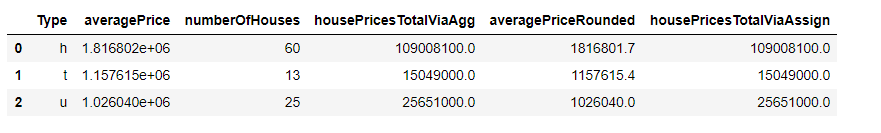
图片来自作者
排序
(melb .query('Regionname.str.startswith("South")', engine = 'python').filter(["Type", "Regionname","Distance"]).groupby(["Regionname", "Type"]).agg(["mean"]).reset_index() .set_axis(["Regionname", "Type", "averageDistance"], axis = 1, inplace = False).sort_values(by = ['averageDistance'], ascending = False))

图片来自作者
为不同区域的平均距离绘制条形图
(melb#.query('Regionname.str.startswith("South")', engine = 'python').filter(["Regionname", "Distance"]).groupby(["Regionname"]).agg(["mean"]).reset_index().set_axis(["Regionname", "averageDistance"],axis = 1, inplace = False).set_index("Regionname").sort_values(by = ['averageDistance'], ascending = False).plot(kind = "bar"))
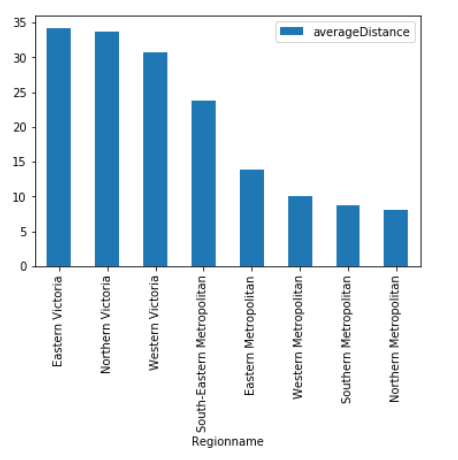
图片来自作者
使用直方图绘制价格分布
(melb.Price # getting one specific variable.hist())
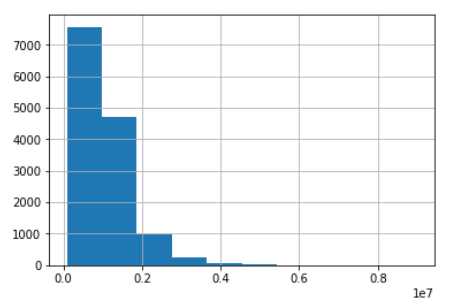
图片来自作者
结语
参考资料
Melbourne Housing Snapshot | Kaggle:https://www.kaggle.com/dansbecker/melbourne-housing-snapshot
Tidyverse:https://www.tidyverse.org/
The Flawless Pipes of Tidyverse. Exploratory data analysis made easy | by Soner Yıldırım | Mar, 2021 | Towards Data Science:ttps://towardsdatascience.com/the-flawless-pipes-of-tidyverse-bb2ab3c5399f
Welcome | R for Data Science (had.co.nz):https://r4ds.had.co.nz/
18 Pipes | R for Data Science (had.co.nz):https://r4ds.had.co.nz/pipes.html?q=pipe#pipes
Data visualization in Python like in R’s ggplot2 | by Dr. Gregor Scheithauer | Medium:https://gscheithauer.medium.com/data-visualization-in-python-like-in-rs-ggplot2-bc62f8debbf5
译者简介

王闯(Chuck),台湾清华大学资讯工程硕士。曾任奥浦诺管理咨询公司数据分析主管,现任尼尔森市场研究公司数据科学经理。很荣幸有机会通过数据派THU微信公众平台和各位老师、同学以及同行前辈们交流学习。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”拥抱组织