
【Python】Pandas中的宝藏函数-transform()
Pandas具有很多强大的功能,transform就是其中之一,利用它可以高效地汇总数据且不改变数据行数,transform是一种什么数据操作?如果熟悉SQL的窗口函数,就非常容易理解了,该函数的核心功能是,既计算了统计值,又保留了明细数据。为了更好地理解transform和agg的不同,下面从实际的应用场景出发进行对比。
aggregation会返回数据的缩减版本,而transformation能返回完整数据的某一变换版本供我们重组。这样的transformation,输出的形状和输入一致。一个常见的例子是通过减去分组平均值来居中数据。
#数据构造data = pd.DataFrame({"company":['百度', '阿里', '百度', '阿里', '百度', '腾讯', '腾讯', '阿里', '腾讯', '阿里'],"salary":[43000, 24000, 40000, 39000, 8000, 47000, 25000, 16000, 21000, 38000],"age":[25, 34, 49, 42, 28, 23, 45, 21, 34, 29]})datacompany salary age0 百度 43000 251 阿里 24000 342 百度 40000 493 阿里 39000 424 百度 8000 285 腾讯 47000 236 腾讯 25000 457 阿里 16000 218 腾讯 21000 349 阿里 38000 29
1、transform作用于Series
1)单个变换函数
当transform作用于单列Series时较为简单 ,对salary列进行transform变换我们可以传入任意的非聚合类函数,比如对工资列对数化
import pandas as pdimport numpy as np# 对工资对数化data['salary'].transform(np.log)0 10.6689551 10.0858092 10.5966353 10.5713174 8.9871975 10.7579036 10.1266317 9.6803448 9.9522789 10.545341Name: salary, dtype: float64
除了内置函数,还可以传入lambda函数
# lambda函数data['salary'].transform(lambda s: s+1)0 430011 240012 400013 390014 80015 470016 250017 160018 210019 38001Name: salary, dtype: int64
2)多个变换函数
也可以传入包含多个变换函数的列表来一口气计算出多列结果:
data['salary'].transform([np.log, lambda s: s+1, np.sqrt])log <lambda> sqrt0 10.668955 43001 207.3644141 10.085809 24001 154.9193342 10.596635 40001 200.0000003 10.571317 39001 197.4841774 8.987197 8001 89.4427195 10.757903 47001 216.7948346 10.126631 25001 158.1138837 9.680344 16001 126.4911068 9.952278 21001 144.9137679 10.545341 38001 194.935887
而又因为transform传入的函数,在执行运算时接收的输入参数是对应的整列数据,所以我们可以利用这个特点实现诸如数据标准化、归一化等需要依赖样本整体统计特征的变换过程:
# 利用transform进行数据标准化data['salary'].transform(lambda s: (s - s.mean()) / s.std())0 0.9910381 -0.4686302 0.7605643 0.6837394 -1.6978255 1.2983376 -0.3918067 -1.0832288 -0.6991049 0.606915Name: salary, dtype: float64
2、 transform作用于DataFrame
当transform作用于整个DataFrame时,实际上就是将传入的所有变换函数作用到每一列中:
data.loc[:,'salary':'age'].transform(lambda s:(s-s.mean()) /s.std())salary age0 0.991038 -0.8320501 -0.468630 0.1040062 0.760564 1.6641013 0.683739 0.9360574 -1.697825 -0.5200315 1.298337 -1.0400636 -0.391806 1.2480757 -1.083228 -1.2480758 -0.699104 0.1040069 0.606915 -0.416025
而当传入多个变换函数时,对应的返回结果格式类似agg中的机制,会生成MultiIndex格式的字段名
data.loc[:, 'salary': 'age'].transform([np.log, lambda s: s+1])salary agelog <lambda> log <lambda>0 10.668955 43001 3.218876 261 10.085809 24001 3.526361 352 10.596635 40001 3.891820 503 10.571317 39001 3.737670 434 8.987197 8001 3.332205 295 10.757903 47001 3.135494 246 10.126631 25001 3.806662 467 9.680344 16001 3.044522 228 9.952278 21001 3.526361 359 10.545341 38001 3.367296 30
而且由于作用的是DataFrame,还可以利用字典以键值对的形式,一口气为每一列配置单个或多个变换函数:
(data.loc[:, 'salary': 'age'].transform({'age': lambda s: (s - s.mean()) / s.std(),'salary': [np.log, np.sqrt]}))age salary<lambda> log sqrt0 -0.832050 10.668955 207.3644141 0.104006 10.085809 154.9193342 1.664101 10.596635 200.0000003 0.936057 10.571317 197.4841774 -0.520031 8.987197 89.4427195 -1.040063 10.757903 216.7948346 1.248075 10.126631 158.1138837 -1.248075 9.680344 126.4911068 0.104006 9.952278 144.9137679 -0.416025 10.545341 194.935887
3、transform作用于groupby分组后
在原来的数据中,我们知道了如何求不同公司的平均薪水,假如需要在原数据集中新增一列salary_mean,代表该公司的平均薪水,该怎么实现呢?
data['salary_mean'] = data.groupby('company')[['salary']].transform('mean')datacompany salary age salary_mean0 百度 43000 25 30333.3333331 阿里 24000 34 29250.0000002 百度 40000 49 30333.3333333 阿里 39000 42 29250.0000004 百度 8000 28 30333.3333335 腾讯 47000 23 31000.0000006 腾讯 25000 45 31000.0000007 阿里 16000 21 29250.0000008 腾讯 21000 34 31000.0000009 阿里 38000 29 29250.000000
通过上面的数据可以看出,利用transform输出,既得到了统计数据,形状也没有变化。
当然,也可对多个数据列进行计算
data.groupby('company')[['salary', 'age']].transform('mean')salary age0 30333.333333 34.01 29250.000000 31.52 30333.333333 34.03 29250.000000 31.54 30333.333333 34.05 31000.000000 34.06 31000.000000 34.07 29250.000000 31.58 31000.000000 34.09 29250.000000 31.5
我们也可以用map函数实现类似的功能,但是稍微复杂点,但是有助于我们理解transform的含义。
avg_dict = data.groupby('company')['salary'].mean().to_dict()avg_dict#得到了一个平均工资的字典{'百度': 30333.333333333332, '腾讯': 31000.0, '阿里': 29250.0}#利用map函数,将得到的字典映射到对应的列data['salary_mean'] = data['company'].map(avg_dict)datacompany salary age salary_mean0 百度 43000 25 30333.3333331 阿里 24000 34 29250.0000002 百度 40000 49 30333.3333333 阿里 39000 42 29250.0000004 百度 8000 28 30333.3333335 腾讯 47000 23 31000.0000006 腾讯 25000 45 31000.0000007 阿里 16000 21 29250.0000008 腾讯 21000 34 31000.0000009 阿里 38000 29 29250.000000
以图解的方式来看看进行groupby后transform的实现过程(公司列包含ABC,salary列为每个员工的工资明细):
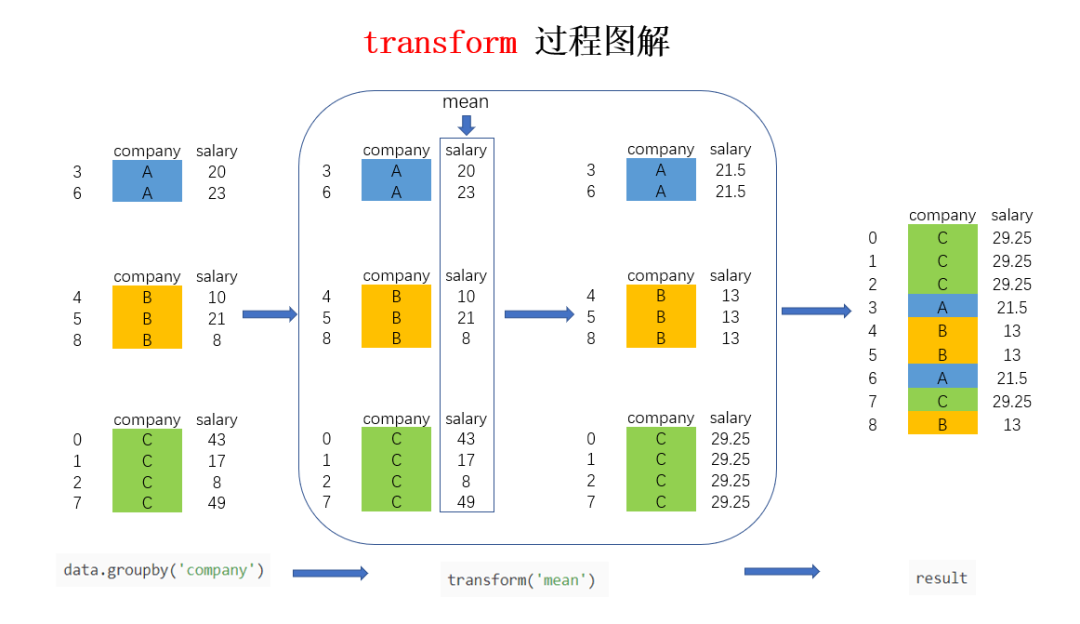
上图中的大方框是transform和agg 所不一样的地方,对agg而言,会计算并聚合得到 A,B,C 公司对应的均值并直接返回,每个公司一条数据,但对transform而言,则会对每一条数据求得相应的结果,同一组内的样本会有相同的值,组内求完均值后会按照原索引的顺序返回结果
往期精彩回顾 本站qq群851320808,加入微信群请扫码: