
Pandas tricks 之 transform的用法
点击上方“超哥的杂货铺”,轻松关注
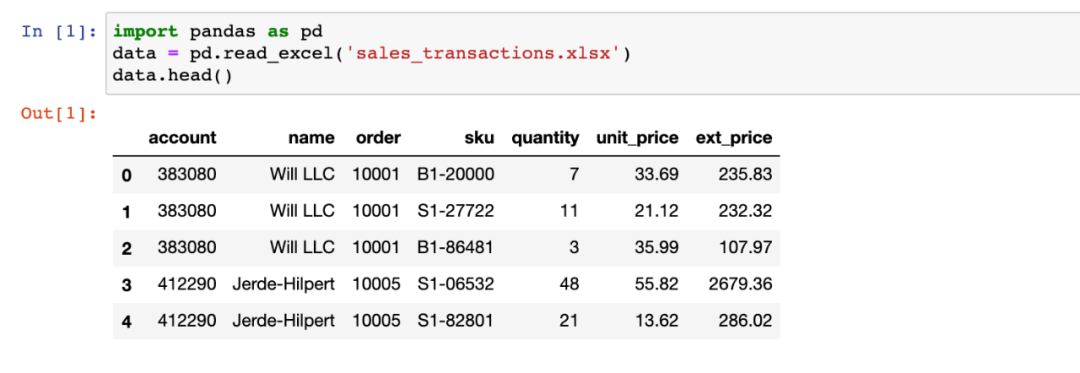
先来看一个实例问题。
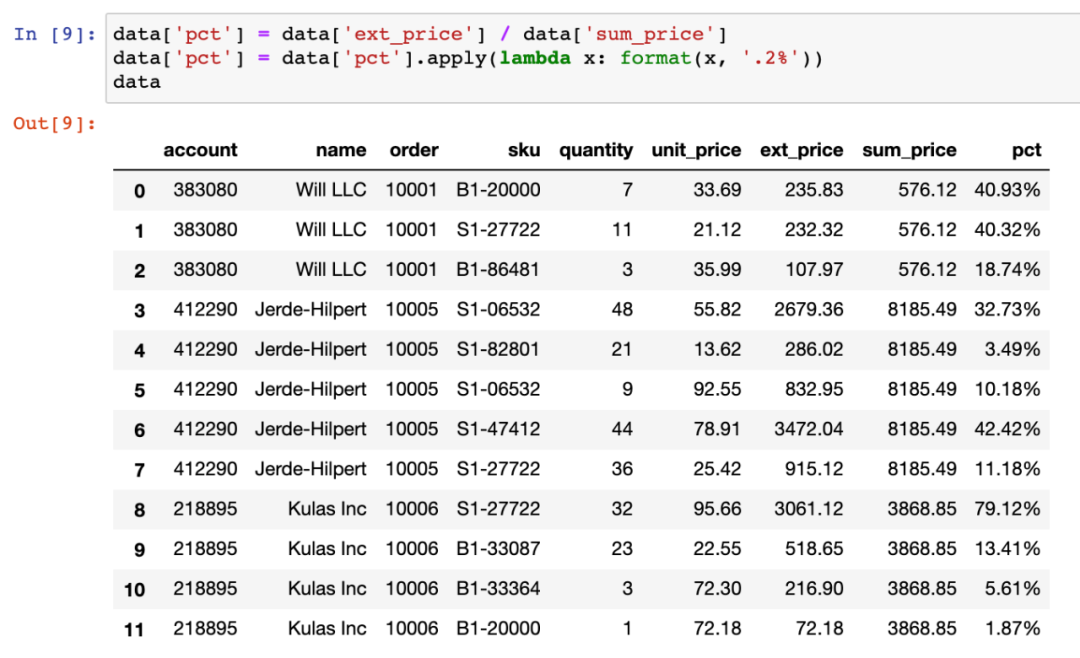
如下销售数据中展现了三笔订单,每笔订单买了多种商品,求每种商品销售额占该笔订单总金额的比例。例如第一条数据的最终结果为:235.83 / (235.83+232.32+107.97) = 40.93%。
 后台回复“transform”获取本文全部代码和pdf版本。
后台回复“transform”获取本文全部代码和pdf版本。
思路一:
常规的解法是,先用对订单id分组,求出每笔订单的总金额,再将源数据和得到的总金额进行“关联”。最后把相应的两列相除即可。相应的代码如下:
1.对订单id分组,求每笔订单总额。由于有三个order,因此最终会产生三条记录表示三个总金额。

2.数据关联合并
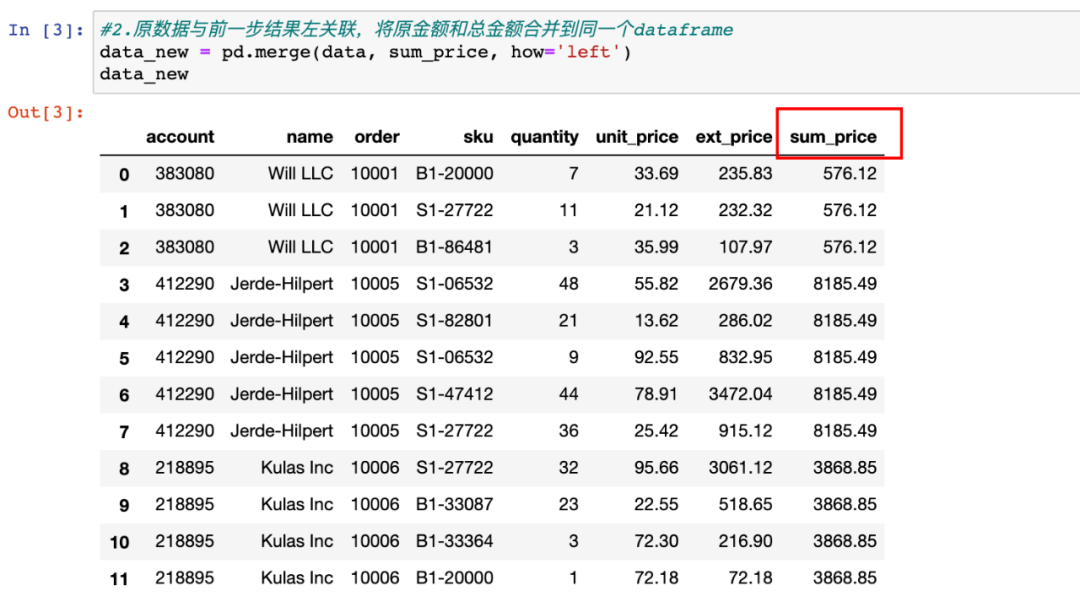
为了使每行都出现相应order的总金额,需要使用“左关联”。我们使用源数据在左,聚合后的总金额数据在右(反过来也可)。不指定连接key,则会自动查找相应的关联字段。由于是多行对一行的关联,关联上的就会将总金额重复显示多次,刚好符合我们后面计算的需要。结果如上图所示。
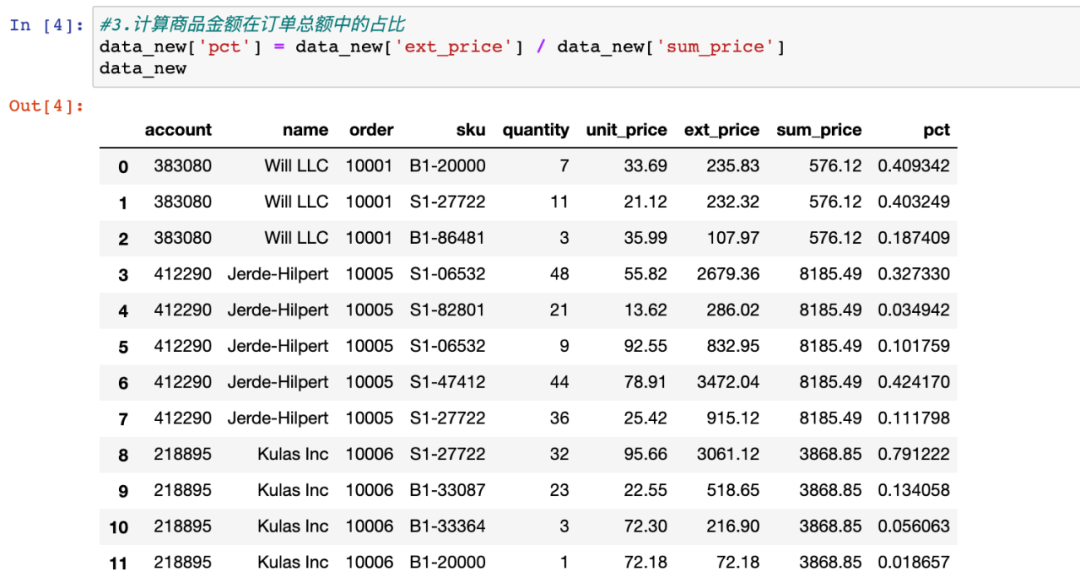
3.计算占比
有了前面的基础,就可以进行最终计算了:直接用商品金额ext_price除以订单总额sum_price。并赋值给新的列pct即可。
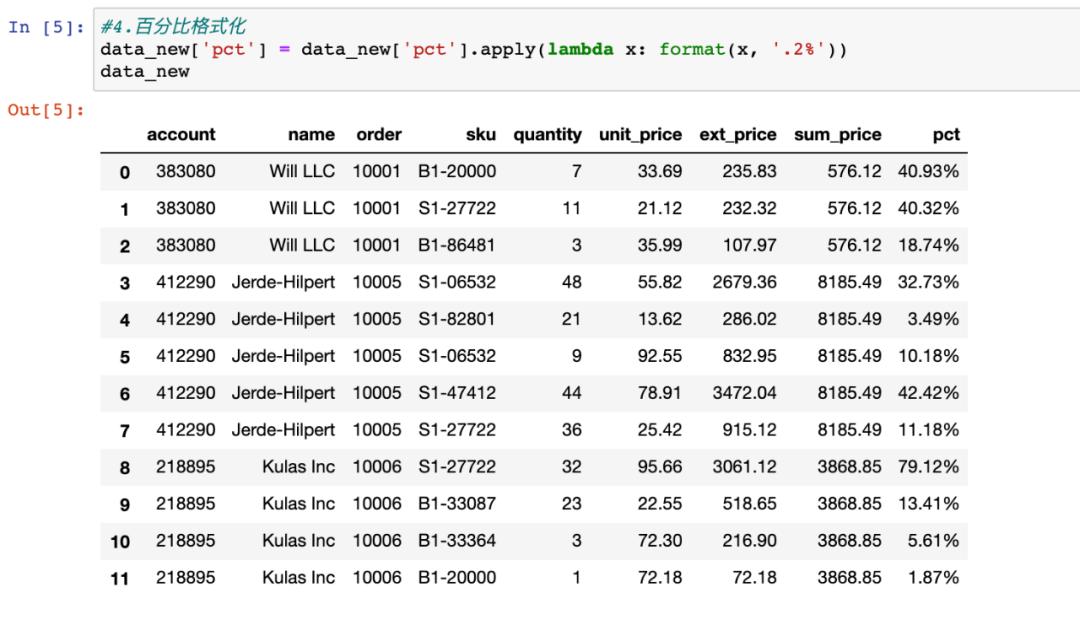
4.格式调整
为了美观,可以将小数形式转换为百分比形式,自定义函数即可实现。
思路二:
对于上面的过程,pandas中的transform函数提供了更简洁的实现方式,如下所示:
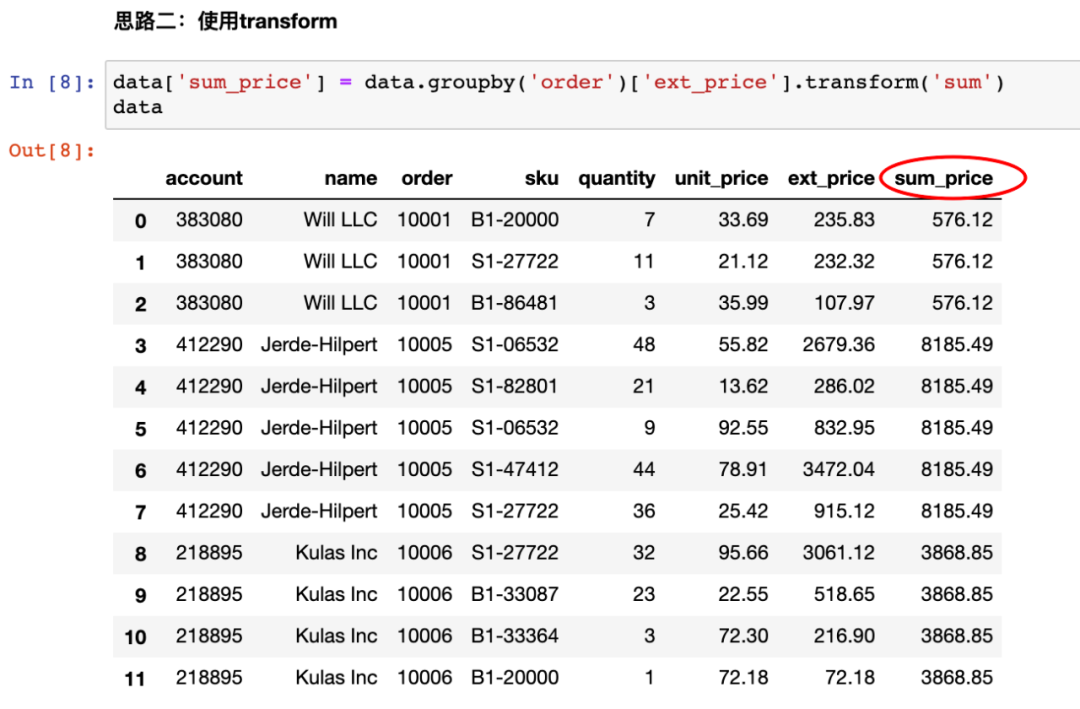
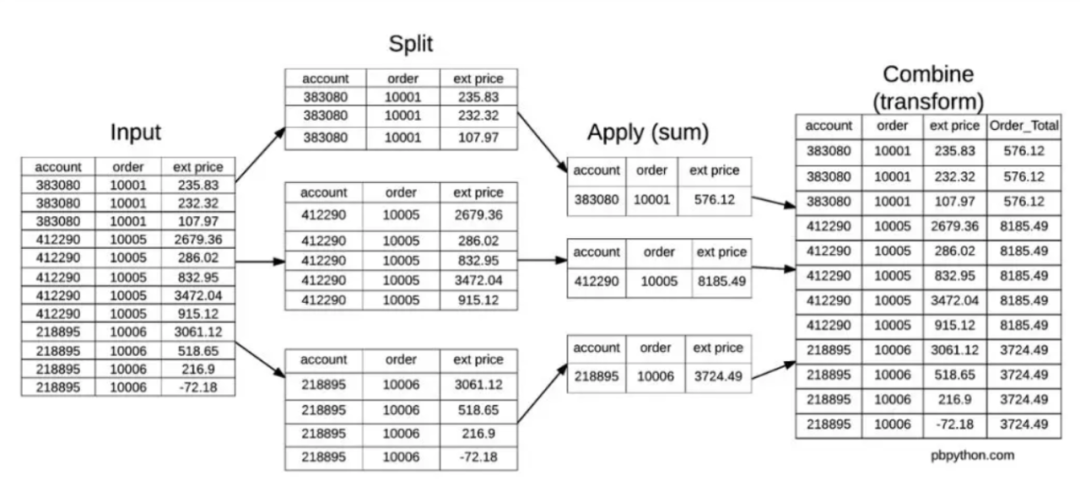
可以看到,这种方法把前面的第一步和第二步合成了一步,直接得到了sum_price列。这就是transform的核心:作用于groupby之后的每个组的所有数据。可以参考下面的示意图帮助理解:
后面的步骤和前面一致。
这种方法在需要对多列分组的时候同样适用。
多列分组使用transform
为演示效果,我们虚构了如下数据,id,name,cls为维度列。
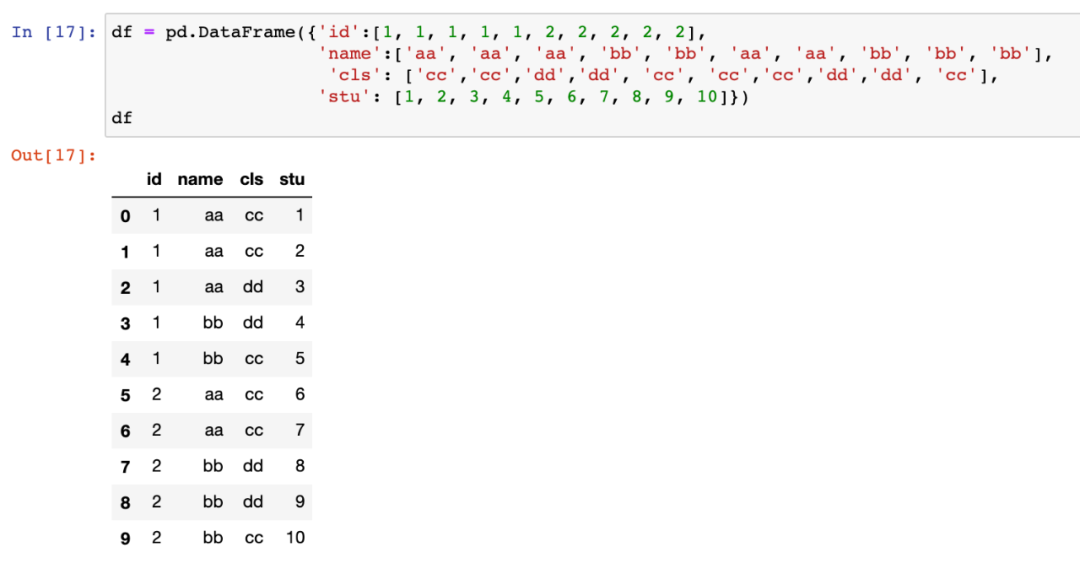
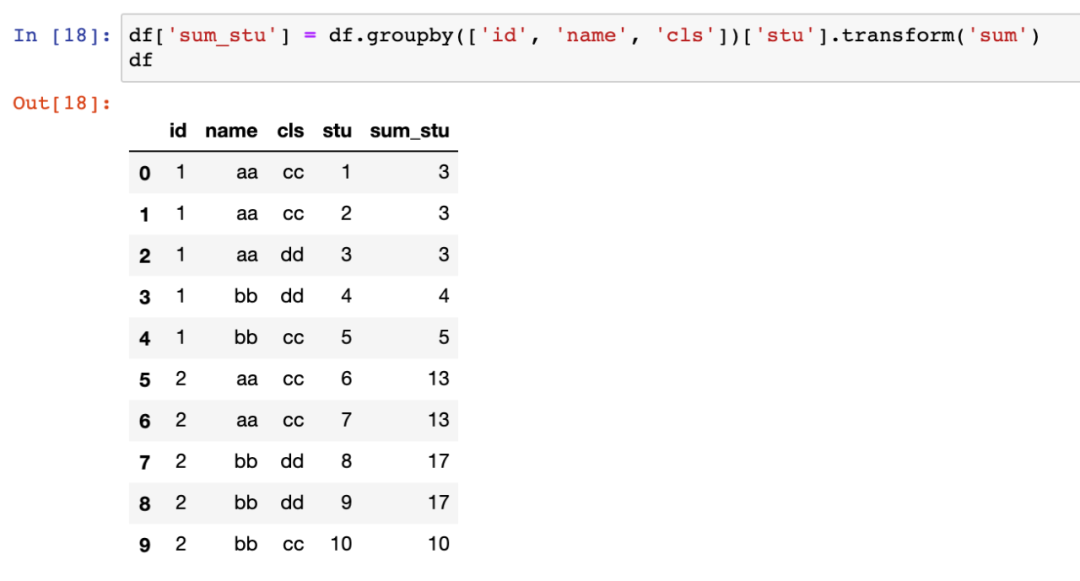
我们想求:以(id,name,cls)为分组,每组stu的数量占各组总stu的比例。使用transform处理如下:
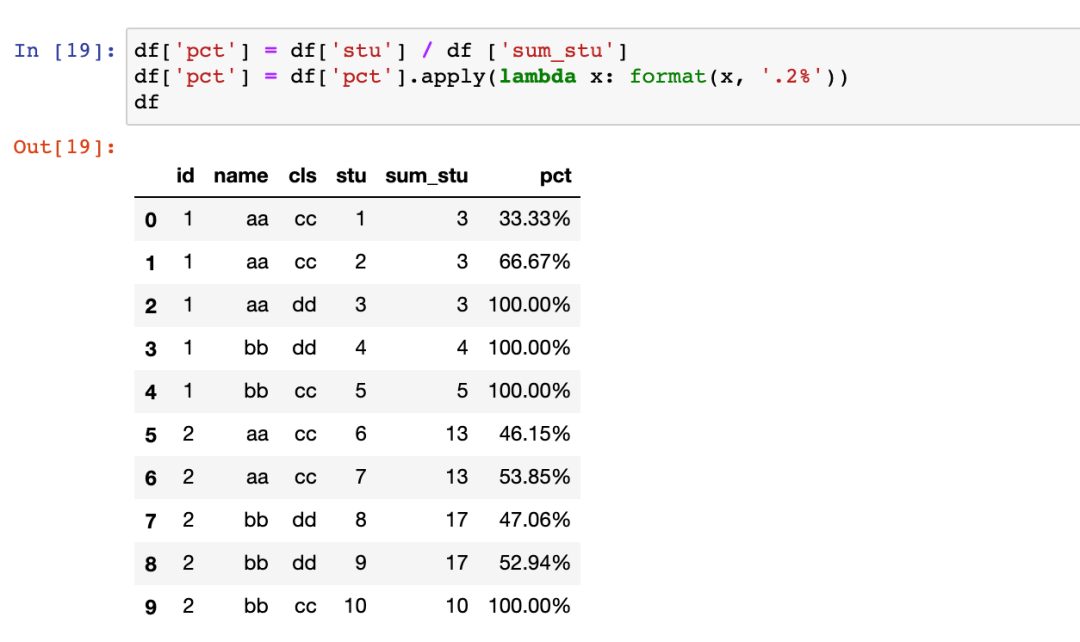
同样再次计算占比和格式化,得到最终结果:
总结transform的用法
transform函数的官方文档签名为:DataFrame.transform(func,axis=0,*args,**kwargs),表示调用func函数进行转换,返回转换后的值,且返回值与原来的数据在相同的轴上具有相同的长度。func可以是函数,字符串,列表或字典。具体可以参考官方文档:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.transform.html#pandas.DataFrame.transform。
transform既可以和groupby一起使用,也可以单独使用。
1.单独使用
此时,在某些情况下可以实现和apply函数类似的结果。
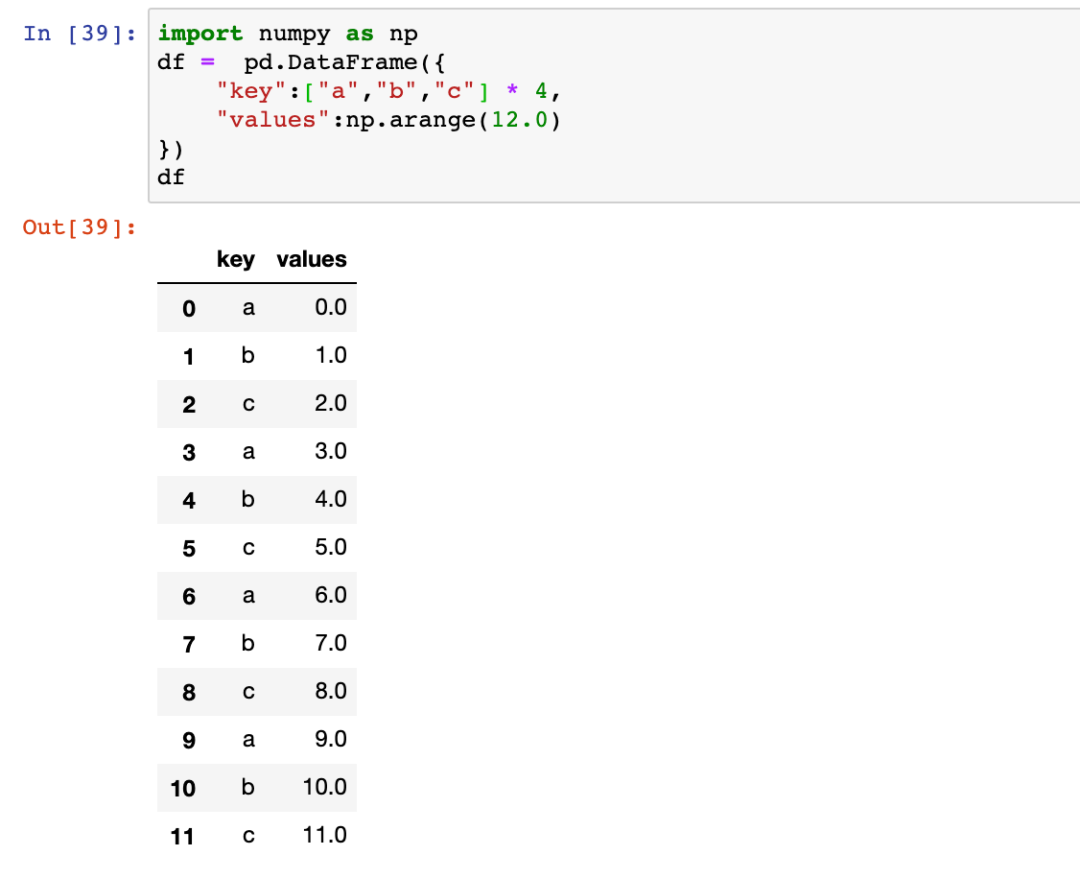
2.与groupby一起使用
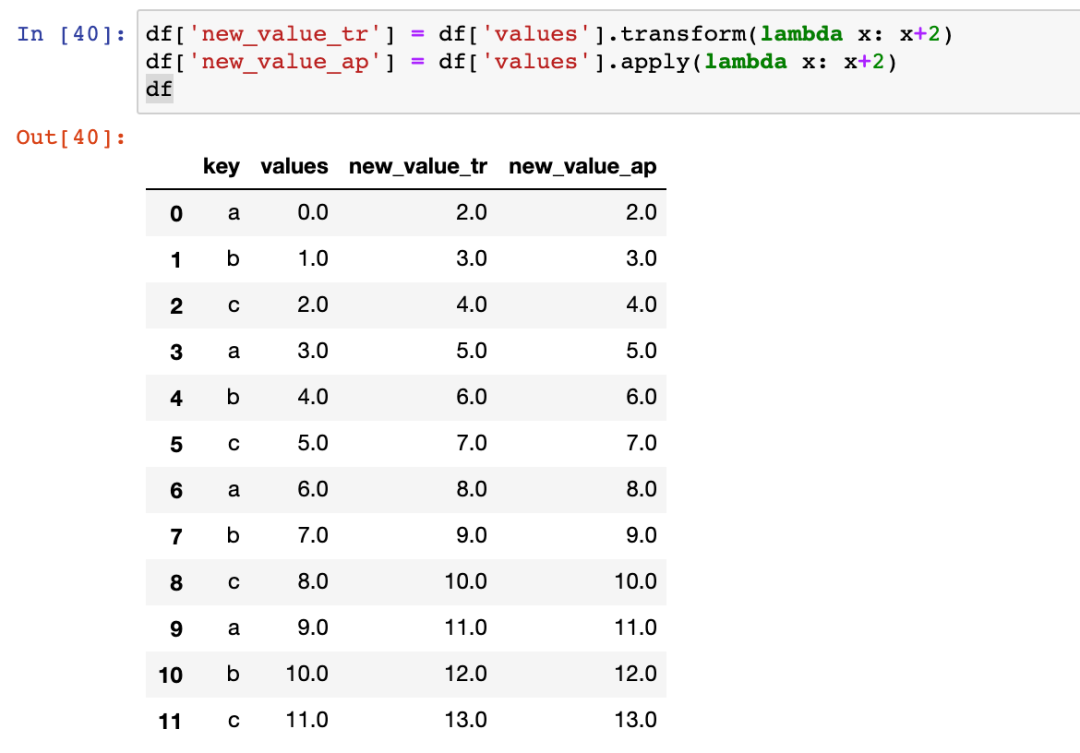
此时,transform函数返回与原数据一样数量的行,并将函数的结果分配回原始的dataframe。也就是说返回的shape是(len(df),1)。本文开头的例子就是这样。而apply函数返回聚合后的行数。例如:
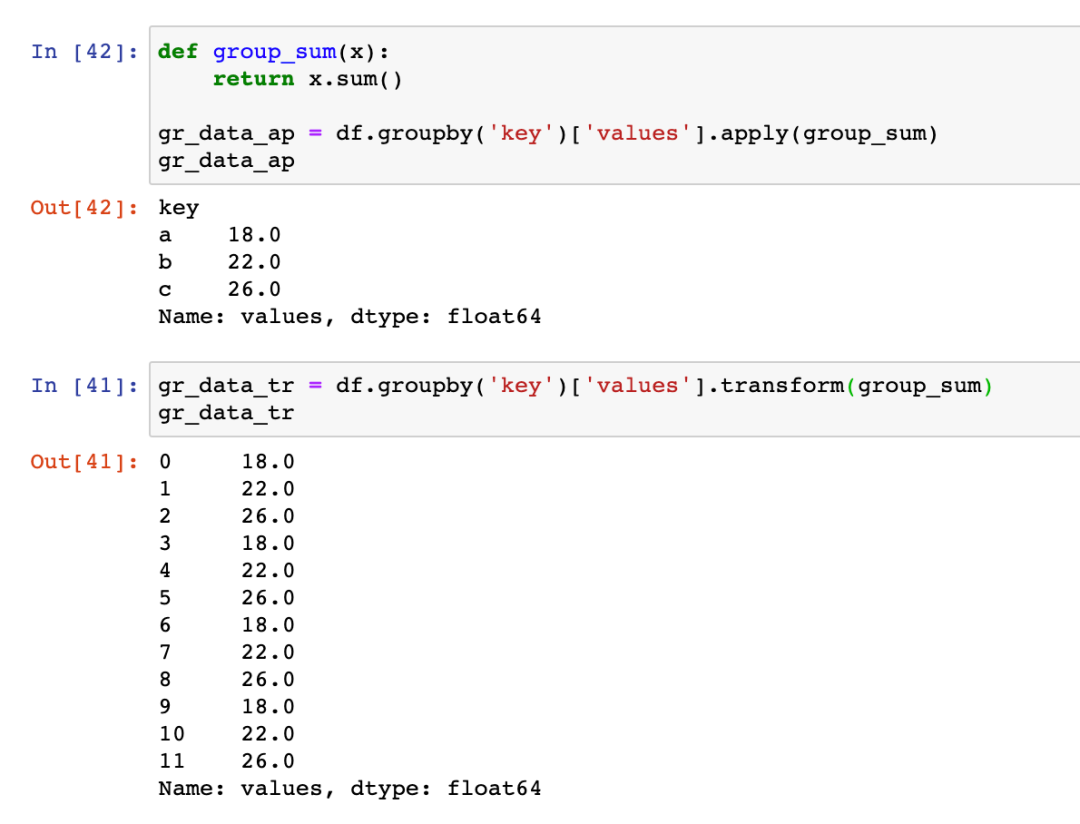
transform和apply的另一个区别是,apply函数可以同时作用于多列,而transform不可以。下面用例子说明:

上图中的例子,定义了处理两列差的函数,在groupby之后分别调用apply和transform,transform并不能执行。如果不采用groupby,直接调用,也会有问题,参见下面的第二种调用方式。
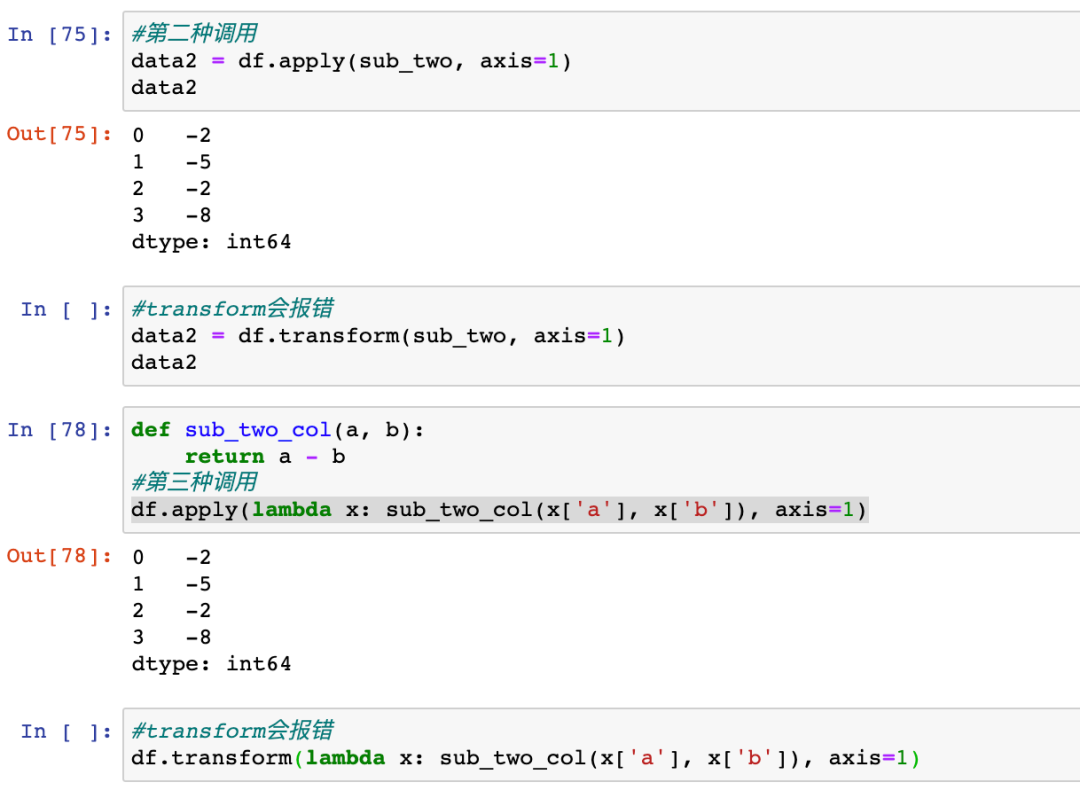
第三种调用调用方式修改了函数,transform依然不能执行。以上三种调用apply的方式处理两列的差,换成transform都会报错。
利用transform填充缺失值
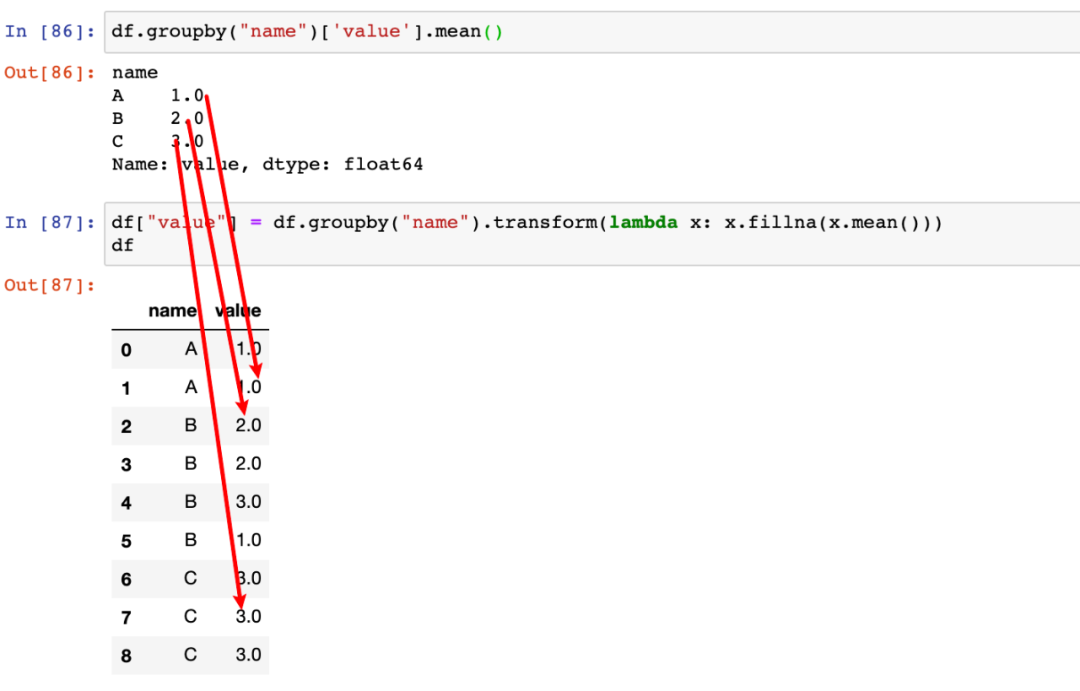
transform另一个比较突出的作用是用于填充缺失值。举例如下:

在上面的示例数据中,按照name可以分为三组,每组都有缺失值。用平均值填充是一种处理缺失值常见的方式。此处我们可以使用transform对每一组按照组内的平均值填充缺失值。
小结:
transform函数经常与groupby一起使用,并将返回的数据重新分配到每个组去。利用这一点可以方便求占比和填充缺失值。但需要注意,相比于apply,它的局限在于只能处理单列的数据。
后台回复“transform”获取本文全部代码和pdf版本。
Reference:
https://www.codenong.com/19966018/
https://www.cnblogs.com/junge-mike/p/12761227.html
https://blog.csdn.net/qq_40587575/article/details/81204514
https://pbpython.com/pandas_transform.html
以清净心看世界;
用欢喜心过生活。
超哥的杂货铺,你值得拥有~
长按二维码关注我们
推荐阅读
不再纠结,一文详解pandas中的map、apply、applymap、groupby、agg...