
还在苦恼特征工程?不妨试试这个库
导读
从事机器学习相关岗位的同学都知道这样一句话:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。在数据确定的情况下,那么特征工程就成了唯一可供发挥的关键步骤。广义来讲,特征工程包括特征提取、特征衍生以及特征选择等等,今天本文就来分享Python中的一个特征工程相关的库——featuretools,可自动化快速实现特征提取和特征衍生的工作,对加速机器学习建模和保证特征工程效果都非常有帮助。

featuretools是一个python的开源库(https://www.featuretools.com/),从其名字就可看出,这是一个用于特征相关的工具,是由featurelab团队最早提出设计(featurelab是美国的一家初创公司,目前已被Alteryx收购),发表于论文《Deep Feature Synthesis: Towards Automating Data Science Endeavors》中,想要详细了解其设计思想和算法原理的可参考这篇文章。今天,本文主要是介绍下它的应用和测试效果。
featuretools的安装和基本使用
featuretools的安装过程非常简单,和其他python库可直接使用pip工具完成安装一样,featuretools也可以这样安装。
pip install featuretools安装完成后,调包的过程一般只需要如下一句,这就像import numpy as np一样,而后续的所有操作都是基于ft这个主入口的:
import featuretools as ft当然,在具体使用之前,这里还是要先简单介绍下featuretools的基本设计和原理。简单来说,featuretools是用于从若干原始数据表中自动化提取特征的一个工具,以论文中的电商订单的例子为例:需要统计对各客户构建特征,所使用的数据表有两张,一个是客户基本信息表,例如年龄、性别、工资收入等;另一个是订单信息表,其中包含了每笔订单的金额、产生订单的客户等。显然,这里客户信息表和订单信息表之间的关联关系是客户ID,且一个客户ID可对应多笔订单。
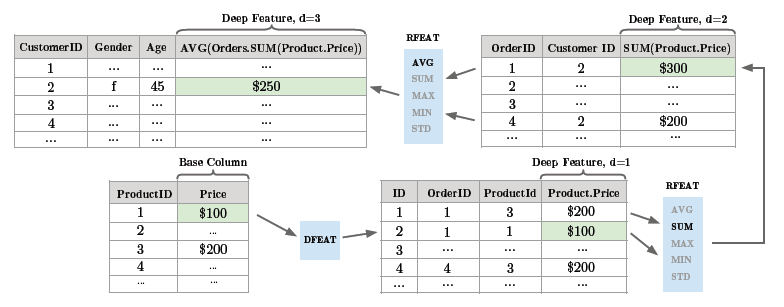
同样的特征构建思想,featuretools罗列了这期间的所有可能需要的特征构建算子,并设置了迭代构建的深度:max_depth。
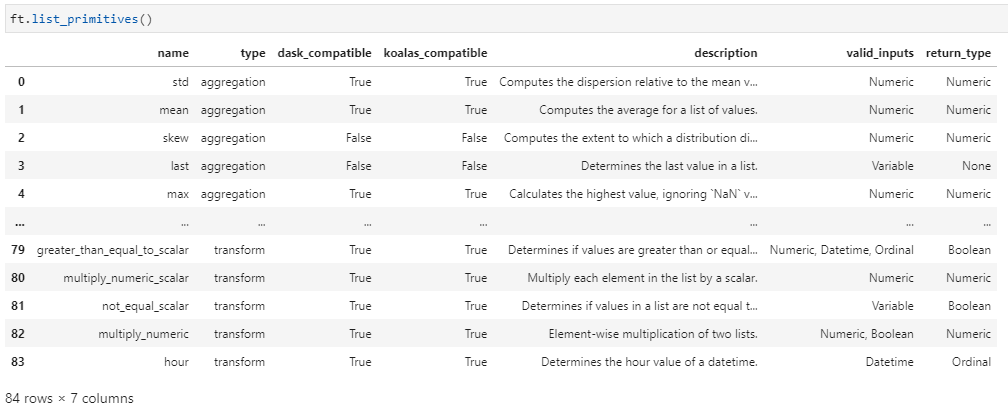
特征构建算子在featuretools中称作primitive——基于
其次介绍特征构建深度的问题:max_depth。例如对于客户基本信息表中有A、B、C、D四个特征,那么A+B和C-D都是depth=1的衍生特征,而(A+B)*(C-D)则是depth=2的衍生特征,以此类推。正因如此,featuretools中的特征构建算法叫做Deep Feature Synthesis,即深度特征合成。
如上就是一些关于featuretools的基本设计的简要介绍,更为详尽的理论和使用还需查阅论文或其他资料。下面给出一个简单的demo,同时测试其效果情况,这里以sklearn中的breast_cancer数据集为例:
1.导入数据,构建DataFrame格式的数据集
dataset = load_breast_cancer()X = dataset.datay = dataset.targetfeature_names = dataset.feature_namesdf = pd.DataFrame(X, columns=feature_names)
2.调用featuretools,构建数据集实体,并设置特征构建基元,调用dfs方法(深度特征合成):
es = ft.EntitySet(id='breast_cancer') # 用id标识实体集# 增加一个数据框,命名为irises.entity_from_dataframe(entity_id='breast_cancer',dataframe=df,index='idx',make_index=True)trans_primitives=['add_numeric', 'multiply_numeric'] # 取任意两列组合的相加和相乘,衍生新的特征XNew, new_names = ft.dfs(entityset=es,target_entity='breast_cancer',max_depth=1, # max_depth=1,只在原特征上进行运算产生新特征verbose=1,trans_primitives=trans_primitives)
X_train, X_test, XNew_train, XNew_test, y_train, y_test = train_test_split(X, XNew, y)np.mean([DecisionTreeClassifier().fit(X_train, y_train).score(X_test, y_test) for _ in range(10)])# 0.9342657342657343np.mean([DecisionTreeClassifier().fit(XNew_train, y_train).score(XNew_test, y_test) for _ in range(10)])# 0.9468531468531468
相关阅读: