腾讯微博即将退出舞台,爬取近十年腾讯微博数据,发现转折点竟在这一年!

前言
你用过腾讯微博吗?9月4日,腾讯微博团队突然发布公告称,将于9月28日停止服务和运营,此条消息一出,新浪微博立马安排了一条热搜并引发网友热议!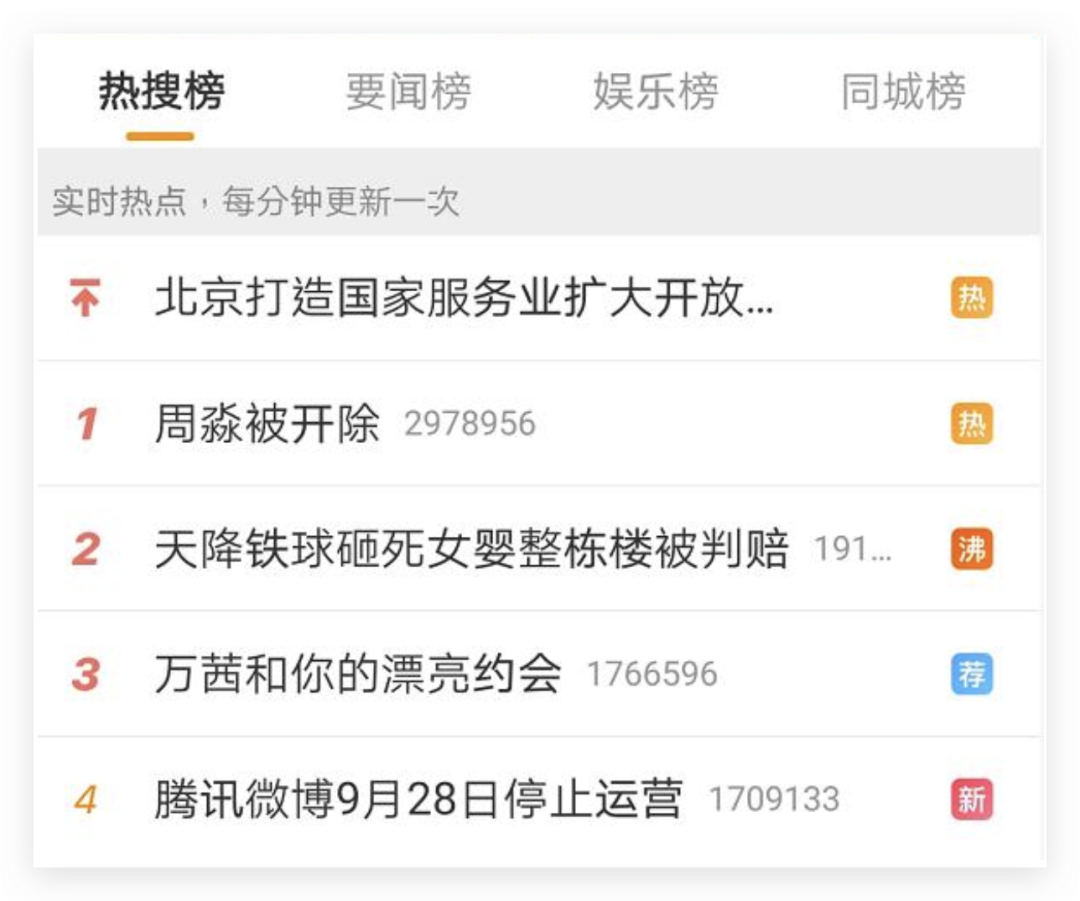 部分用户很震惊腾讯微博居然关了,也有些用户很震惊腾讯微博居然还活着,还有部分用户甚至不知道腾讯微博的存在,腾讯微博已经被淹没在互联网的长流中,但互联网是有记忆的,本文就将通过Python爬取历史数据,尝试探索背靠数亿流量的腾讯微博是如何一步步退出舞台。
部分用户很震惊腾讯微博居然关了,也有些用户很震惊腾讯微博居然还活着,还有部分用户甚至不知道腾讯微博的存在,腾讯微博已经被淹没在互联网的长流中,但互联网是有记忆的,本文就将通过Python爬取历史数据,尝试探索背靠数亿流量的腾讯微博是如何一步步退出舞台。
为了研究腾讯微博的历史数据,很自然的就想到从网页入手,但是让人遗憾的是,虽然官方公告说9月28日正式停止运营,实际上大概在去年就几乎打不开了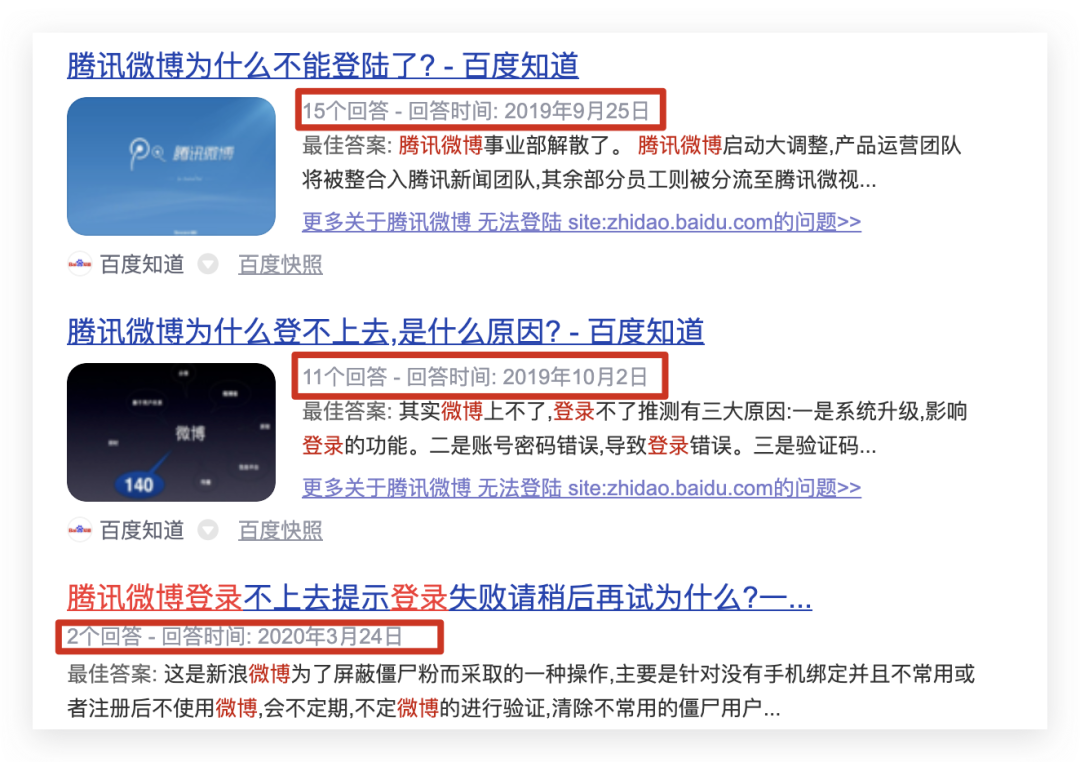 而就算经过不断尝试成功打开页面,你会发现除了报错代码后什么内容都没有,也无法登陆,那既然官方网站这条路走不通,要怎样才能找到腾讯微博的历史数据呢?
而就算经过不断尝试成功打开页面,你会发现除了报错代码后什么内容都没有,也无法登陆,那既然官方网站这条路走不通,要怎样才能找到腾讯微博的历史数据呢?
我们都知道搜索引擎在收录网页时,会对网页进行备份,以网页快照的形式存在自己的服务器缓存里,这样我们就可以通过点击网页快照来查看网站的历史状态。除了搜索引擎,还有一些网站会对互联网做备份,比如Wayback Machine
https://web.archive.org/
自从1996年以来,Wayback Machine就在给整个互联网做备份,现在已经保存了3300亿网页,所以现在让我们搭乘网页时光机回到十年前吧!
时光机
首先打开上述网站(国内暂时无法直接访问,请自行探索解决办法)并在地址栏输入t.qq.com 按下回车之后就会显示该网站收录的腾讯微博全部历史网页
按下回车之后就会显示该网站收录的腾讯微博全部历史网页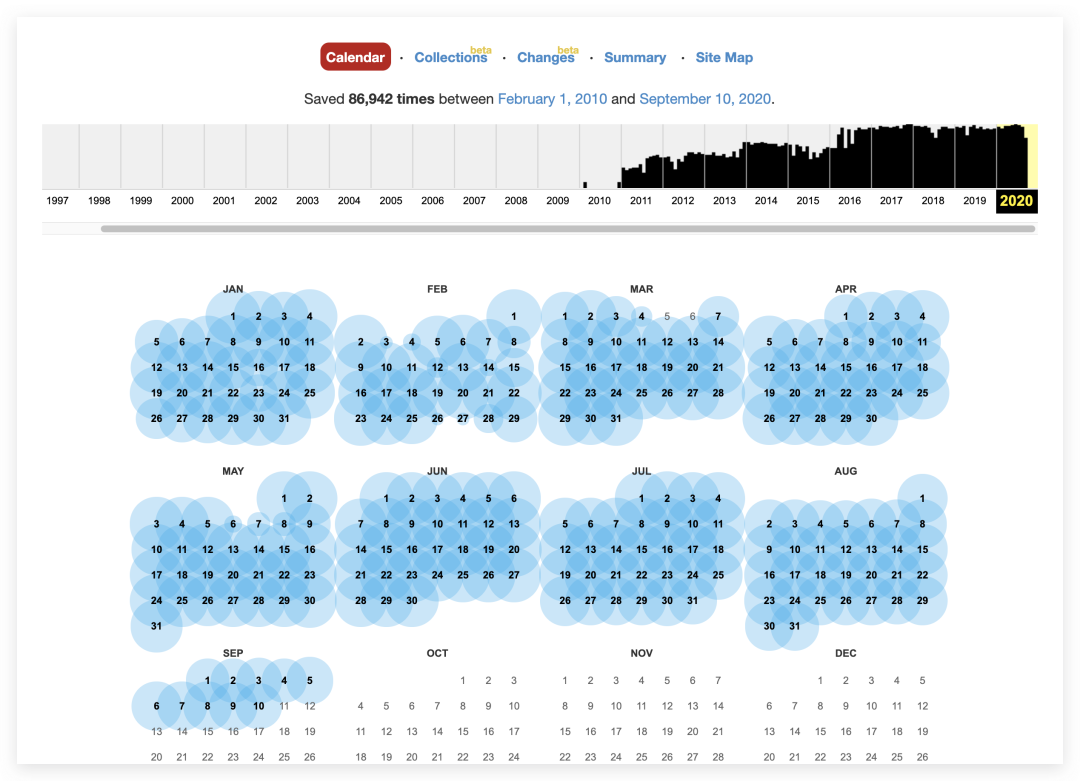 并且自2010年2月1日以来,共采集了86942条历史快照,打开2012年的某一条微博?
并且自2010年2月1日以来,共采集了86942条历史快照,打开2012年的某一条微博?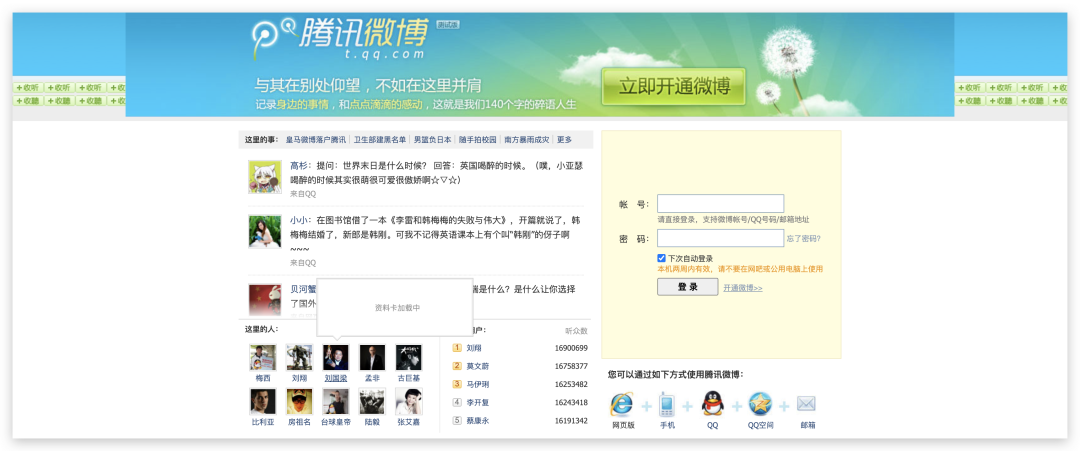 除了满满的年代感就是对青春的回忆,并且可以看到该网站对于腾讯微博最新的记录是2020.9.10,可能这条关停通知就是腾讯微博最终的画面?
除了满满的年代感就是对青春的回忆,并且可以看到该网站对于腾讯微博最新的记录是2020.9.10,可能这条关停通知就是腾讯微博最终的画面?
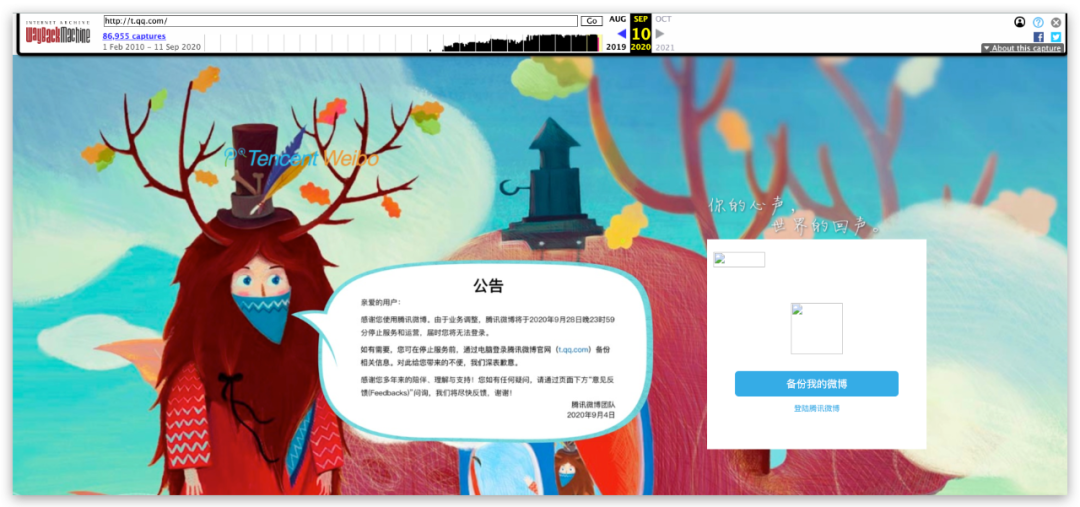
但是互联网的记忆不会被时间磨灭,现在我们将使用Python爬取Wayback Machine网站数据并进行分析,本节将不会对爬取过程做过多说明,详细的技术解析会在下一节进行讲解。
历史快照总量对比
如果一个网站热度越高,那么被收录的次数就越多,首先来看对新浪微博与腾讯微博历史快照的总量进行分析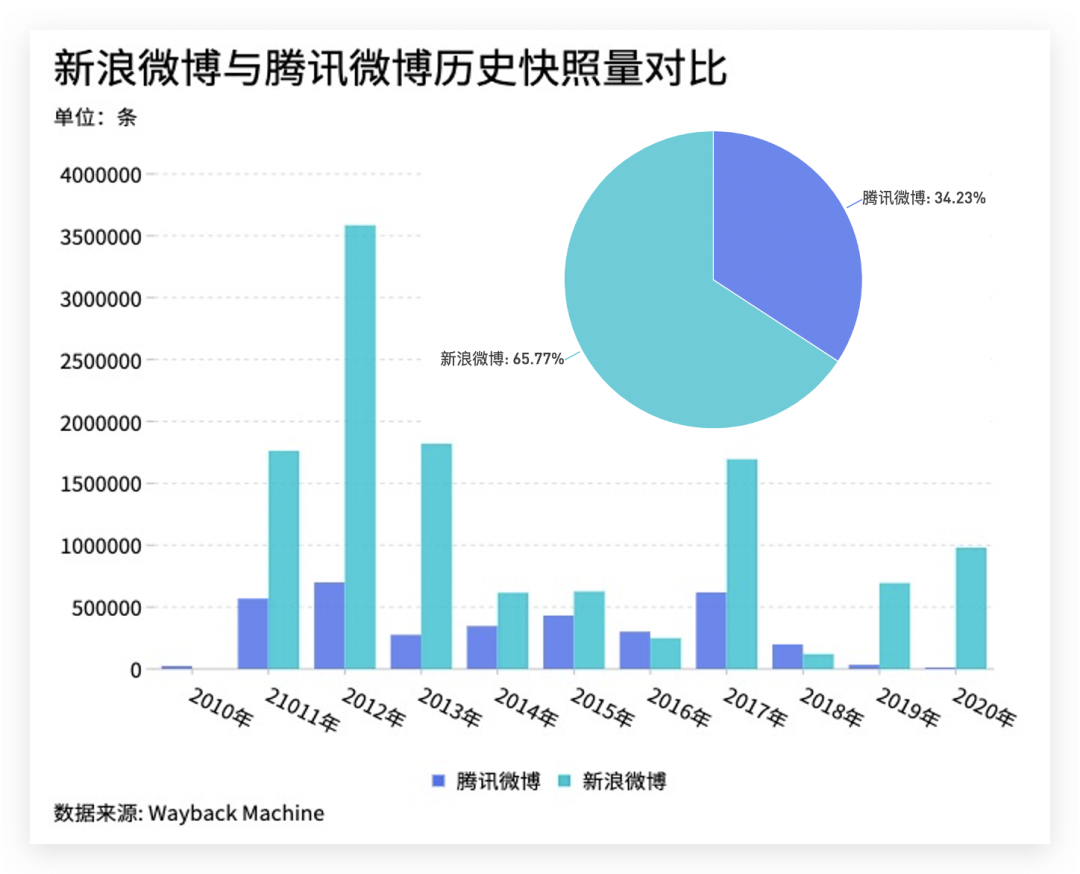 我们可以看到,在这10年间新浪微博的历史快照是腾讯微博的近2倍,而将数据单独拆开来看的话,从2010年两个微博网站被收录以来,新浪微博就以碾压的姿势超越腾讯微博,在2012年两者的新增快照数量均达到最高值,然后趋于稳定。
我们可以看到,在这10年间新浪微博的历史快照是腾讯微博的近2倍,而将数据单独拆开来看的话,从2010年两个微博网站被收录以来,新浪微博就以碾压的姿势超越腾讯微博,在2012年两者的新增快照数量均达到最高值,然后趋于稳定。
快照内容拆解分析
除了对比历史快照数总量,所有的快照都是由一个个HTML文件组成,现在我们将所有的快照内容进行拆解分析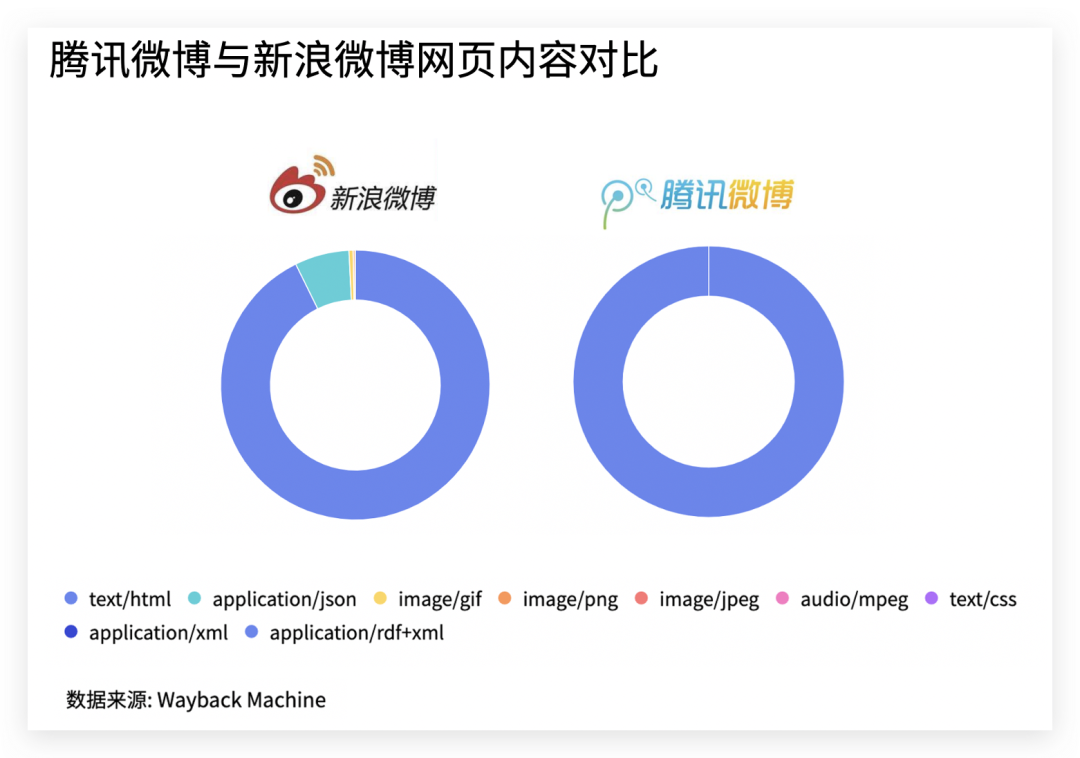 可以看到,每一个快照文件中,新浪微博除了html文本,还有一部分为应用、图片、音视频等多样化内容,而腾讯微博基本上就是html文本组成,是不是和和QQ空间有种同样的感觉,而微博却应该给用户提供一个不一样的发声平台,这可能也是腾讯微博不敌新浪微博的一点因素。
可以看到,每一个快照文件中,新浪微博除了html文本,还有一部分为应用、图片、音视频等多样化内容,而腾讯微博基本上就是html文本组成,是不是和和QQ空间有种同样的感觉,而微博却应该给用户提供一个不一样的发声平台,这可能也是腾讯微博不敌新浪微博的一点因素。
粉丝活跃度分析
为了研究背靠庞大QQ流量的腾讯微博是在哪一年开始下滑,本小节将基于主持人何炅的腾讯微博历史数据(头部大V、2012年腾讯微博热门第一名,有较多的历史数据)进行分析,使用Python爬取该网站收录的何炅的全部历史微博 一共采集到1506条微博,每条微博分别有5条字段:
一共采集到1506条微博,每条微博分别有5条字段:
年份 发博日期 内容 粉丝量 粉丝互动量(转发与评论)
先对何炅的粉丝量变化进行可视化

可以看到何炅粉丝主要增长集中在2012年间,但增势放缓也发生在2012年末,因此2012年对于腾讯微博来说是非常关键的一年,在大量吸收粉丝后却没能留住粉丝。我们接着通过粉丝互动率来分析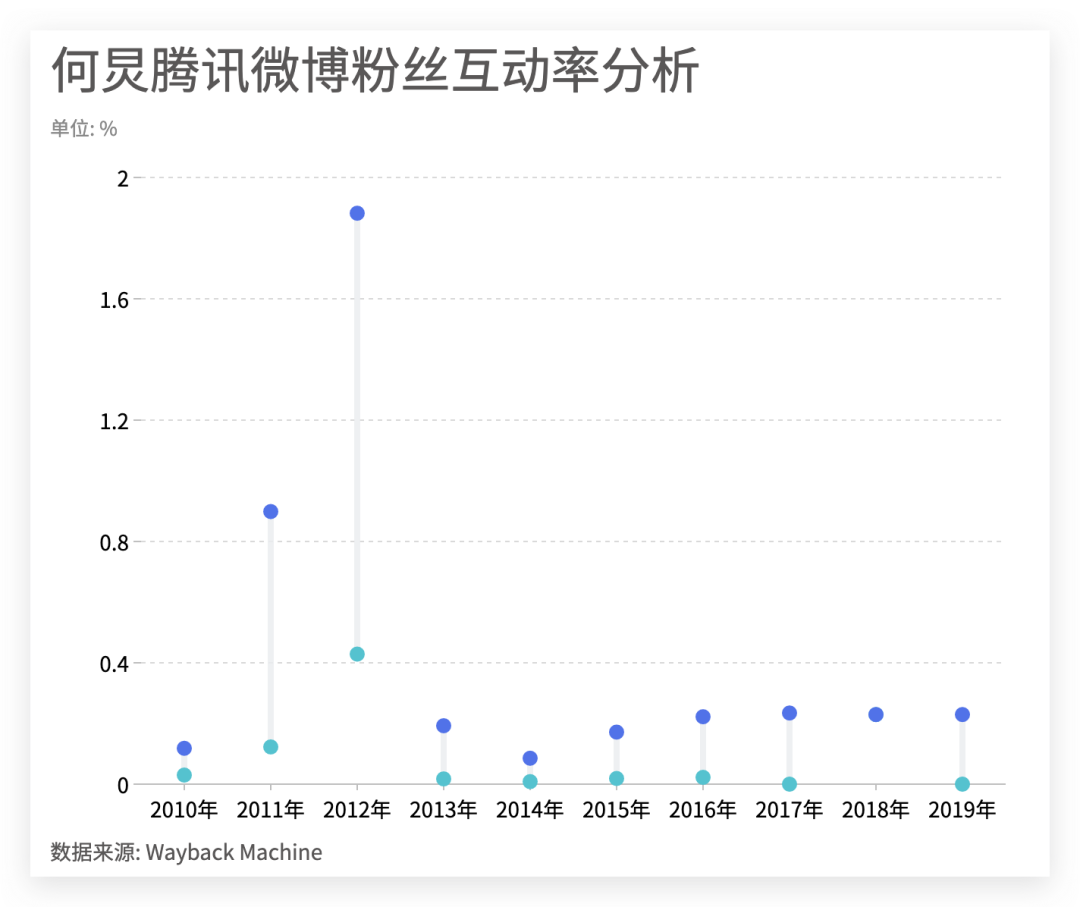 通过对近十年粉丝的转发回复数量进行计算得到粉丝互动率,可以发现2012年依旧是腾讯微博最辉煌的一年,单条微博的互动率最高达到近2%,而后在2013年迅速下滑至0.19%,降低了10倍之多。
通过对近十年粉丝的转发回复数量进行计算得到粉丝互动率,可以发现2012年依旧是腾讯微博最辉煌的一年,单条微博的互动率最高达到近2%,而后在2013年迅速下滑至0.19%,降低了10倍之多。
技术解析
本节我们将用Python示例如何爬取何炅的历史微博,使用到的库有:
requests pandas bs4 waybackpack
首先打开https://web.archive.org/并搜索t.qq.com/hejiong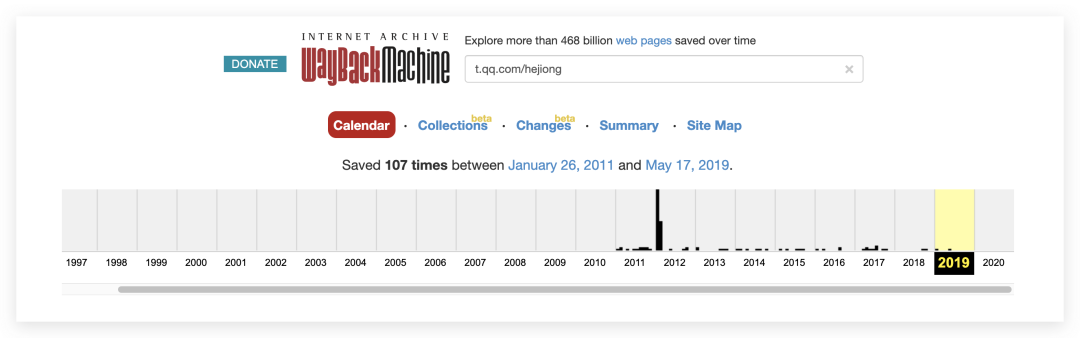 如上图所示,一共收录了何炅的107条腾讯微博历史数据,很自然的就想到如何把这些URL提取出来,此时我们只需要使用pip安装
如上图所示,一共收录了何炅的107条腾讯微博历史数据,很自然的就想到如何把这些URL提取出来,此时我们只需要使用pip安装waybackpack库,并在Jupyter notebook中执行
! waybackpack t.qq.com/hejiong --list
该命令就会返回全部的URL,注意执行该命令依旧需要自行解决国内无法访问的问题 现在我们打开第一个网站并F12,按照下图的指示找到存储微博数据的数据包
现在我们打开第一个网站并F12,按照下图的指示找到存储微博数据的数据包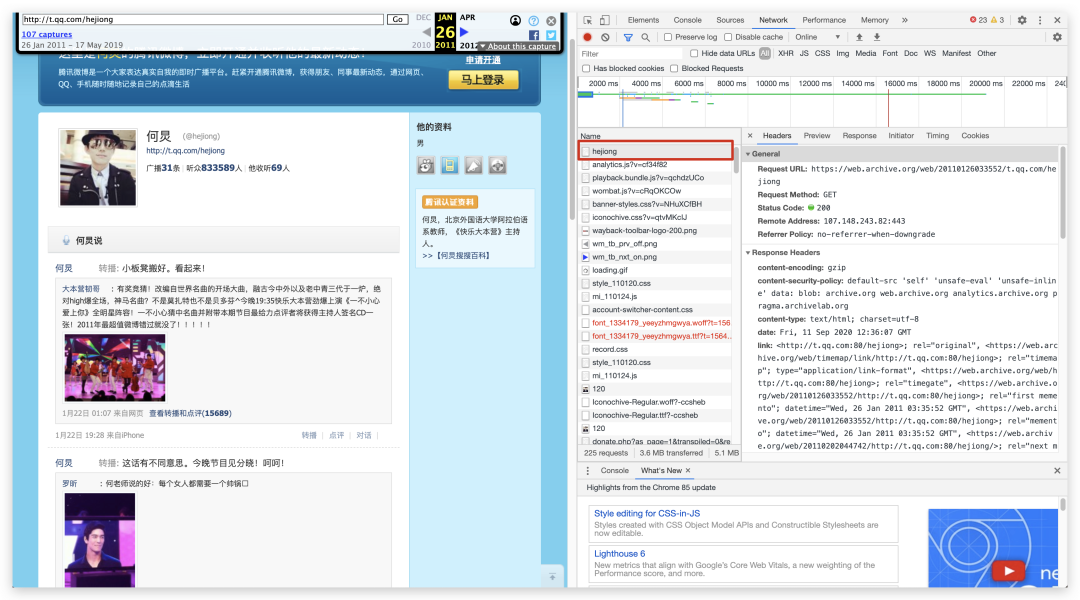 接下来就是遍历每一个url,使用
接下来就是遍历每一个url,使用requests构造请求,接着使用bs4解析数据,再使用pandas清洗存储数据即可
weibo_hejiong = pd.DataFrame(columns=['年份','日期','内容','粉丝量','粉丝互动量'])
for i in range(len(url_hejiong)):
url = url_hejiong[i]
res = requests.get(url=url,headers = headers)
soup = BeautifulSoup(res.text)
followNum = soup.find_all('strong',class_ = "followNum")[0].text #粉丝数
year = url[28:32] #年份
wb_time = soup.find_all('a',class_ = 'time')[::-1] #发博时间
wb_text = soup.find_all('div',class_="msgCnt")[::-1] #博客内容
wb_relayNum = soup.find_all('b',class_="relayNum")[::-1] #互动量
[wb_time.remove(k) for k in wb_time if 'rel' in str(k)]
[wb_text.remove(k) for k in wb_text if 'strong' in str(k)]
for j in range(len(wb_time)):
wb_time_t = wb_time[j].text
wb_text_t = wb_text[j].text
wb_relayNum_t = wb_relayNum[j].text
data = pd.Series([year,wb_time_t, wb_text_t, followNum, wb_relayNum_t], index = weibo_hejiong.columns)
weibo_hejiong = weibo_hejiong.append(data,ignore_index=True)
这部分代码并没有涉及到高级的操作,构造好网站池拿走就能用。因此不做过多讲解,唯一需要注意的是腾讯微博分别在2013年和2017年升级了前端代码,主要影响到粉丝数量及互动量的解析,所以需要将URL分段爬取,并做好异常处理即可。
当然如果你想偷懒,在GitHub上有写好的轮子可以直接提取该网站数据也有针对新浪微博的数据分析库,可以让你少写几行代码,感兴趣的可以自行研究。
小结
通过分析上面的种种数据都可以发现2012年注定是不平凡的一年,而当年究竟发生了什么使得腾讯微博迅速滑下神坛现在已经很难找到答案。近期有关腾讯微博关停分析的文章也有非常多,站在上帝视角的我们可以说是定位错误或是产品运营策略失误还是其他,但我还是希望腾讯可以认真总结经验,不要让QQ空间等装着记忆的产品成为下一个腾讯微博。

本文为公众号「早起Python」原创,任何未经授权的转载皆视为侵权!如需转载,请后台联系!