
全球最大最干净的人脸公开训练集!格灵深瞳发布Glint360K

极市导读
本文介绍了一份规模超大的人脸公开训练集——Glint360,并分析了大规模数据训练的方法。>>加入极市CV技术交流群,走在计算机视觉的最前沿
已经开源,先贴地址~
代码和数据地址:
https://github.com/deepinsight/insightface/tree/master/recognition/partial_fc#glint360k
论文地址:
Partial FC: Training 10 Million Identities on a Single Machine
https://arxiv.org/abs/2010.05222
1 数据集的表现
学术界的测评比如IJB-C和megaface,利用该数据集很容易刷到SOTA,大家具体可以看论文,这里展示一下IFRT的结果,IFRT又称国产FRVT, IFRT测试集主要有不同肤色的素人构成,相比起IJB-C和megaface更具有模型的区分度。
InsightFace Recognition Test (国产FRVT):
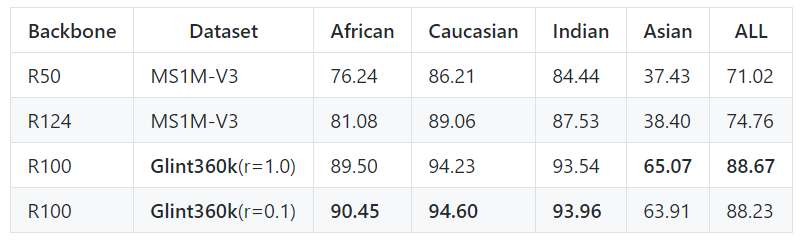
相比起目前最好的训练集MS1MV3,Glint360K有十个点的提升。
2 数据集的规模
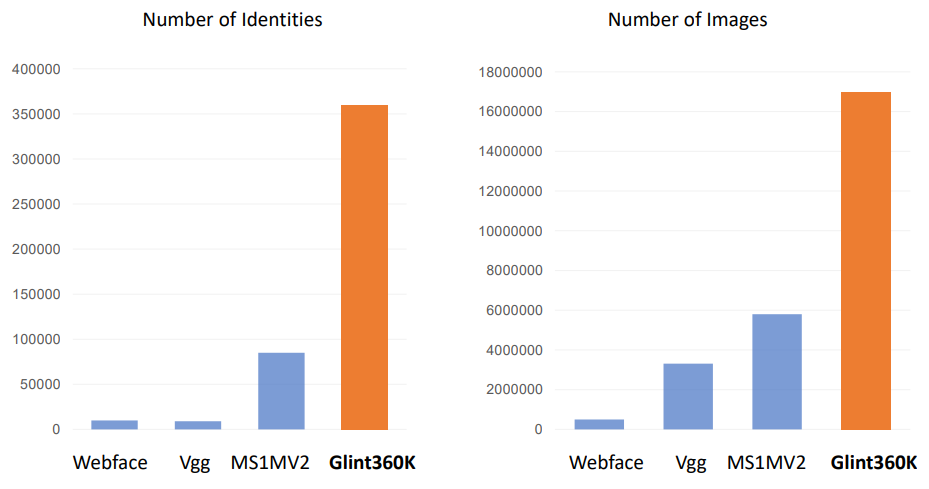
类别数目和图片数目比主流训练集加起来还要多。
Glint360K具有36w类别,和1700w张图片,不论在类别数还是图片数目,相比起MS1MV2都是大幅度的提升。
3 如何训练大规模的数据
人脸识别任务特点就是数据多,类别大,几百万几千万类别的数据集在大公司非常常见,例如2015年的时候,Google声称他们有800w类别的人脸训练集。训如此规模的数据时,很直接的方法就是混合并行,即backbone使用数据并行,分类层使用模型并行, ( 线性变换矩阵)分卡存储,这样优点有两个:1. 缓解了 的存储压力。2. 将 梯度的通信转换成了所有GPU的特征 与 局部分母的通信,大大降低了由于数据并行的带了的通信开销。
这种方法看似可以训练无限的类别(增加GPU的个数就好了),感觉很完美,但是实际上大家在尝试更大规模,更多机器的时候,突然发现,怎么显存不够用了,好像增加类别数的同时增加机器,单个GPU的显存还在增长? 其实我们忽略了另外一个占据显存的张量: 。
首先定义 ,其中 为存储在每张GPU上的子矩阵, 为经过集合通信 收集到全局的特征, 为特征的维度大小, 为总的类别数, 为GPU的个数,其中每块GPU中 占用的显存为:
通过这个公式我们发现,更多的类别数,只要增加GPU的个数,就可以维持 占用的显存不变,我们再看看 ,设每张卡上的批次大小为 ,则对于分类层的总批次大小为 ,每块GPU中 占用的显存为:
我们发现,即使类别数和GPU的个数同时增长之后, 占用的显存与总的批次大小 相关,随着GPU个数的增加, 占用的显存是持续增加的,设100w类别需要用一台8卡RTX2080Ti就够了,则1000w类别需要10台8卡RTX2080Ti,设特征维度为512,每张GPU的批次大小为64,则在训练1000w类别的任务时,每个GPU 占用的显存为 的十倍,在这个例子中,混合并行解决了 占用的显存,却增加了 占用的显存。
4. Partial-FC
在人脸识别中, 的作用为拉近特征与其相应"正类中心"的距离,对其他的"负类中心"则保持距离。这点其实和最近很火热的自监督表征学习非常类似,Moco通过队列保存更多的历史负样本,SimCLR则使用多机多卡,超大的batchsize来增加负样本的个数,我们发现SimCLR再很大batchsize的时候提升有限了,而再人脸识别中的大规模分类,每个特征的负类中心是所有的类中心,把这些负类中心减少一些是不是也能取到到一样的效果?
答案是肯定的,具体实现方式还是要结合混合并行一起做,我们的做法很简单,"正类必采,负类随机",再采样类中心的时候,我们要保证正类中心一定是要必须采到的,所以首先会把正类中心都拿出来,其次会随机的采样一些负类中心,补齐到约定的采样率即可。再混合并行的实现中,数据会随机的出现再不同的GPU上,而它的"正类中心"则实现会根据其类别的按照顺序存放在一个固定的GPU上,则会出现样本和"正类中心"不再同一张GPU上的问题。这个解决方案其实也很简单:在我们实现混合并行的时候,不仅同步了每张卡的特征,同时也同步了每张卡标签,每张卡都有所有卡完整的特征和标签,假设总的批次大小为 ,则至多会有 个正类中心随机分布再所有的GPU中,我们让每个正类中心所属的GPU将该正类采样出来即可,每张GPU正类采出来后,再随机用负类补齐到约定的采样率,这样是的每张GPU采样的到的类中心都是一样多的,实现负载均衡。后续的过程就就是分类层的模型并行部分了,需要注意的是,只有采样出来的类中心的权重和动量会更新。
5. 实验表现
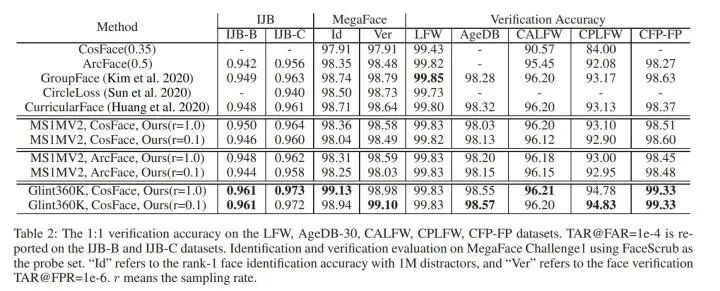
性能方面:
我们在内部的业务和FRVT竞赛上都验证了这个方法,再学术界的测试集IJBC和Megaface上,使用Glint360K的Full softmax和10%采样会有着相当的结果。
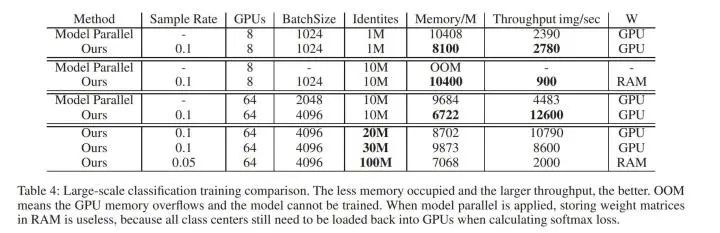
效率方面:
在64块2080Ti,类别数1000w的实验条件下,Partial FC 的速度会是混合并行的3倍,占用的显存也会更低,并且最大支持的类别数也有了一个数量级的飞跃,成功训练起来了一亿id的分类任务。
推荐阅读
ACCV 2020国际细粒度网络图像识别竞赛正式开赛!
