
写了个爬虫把B站弹幕分析了一通。。。
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达


1
2
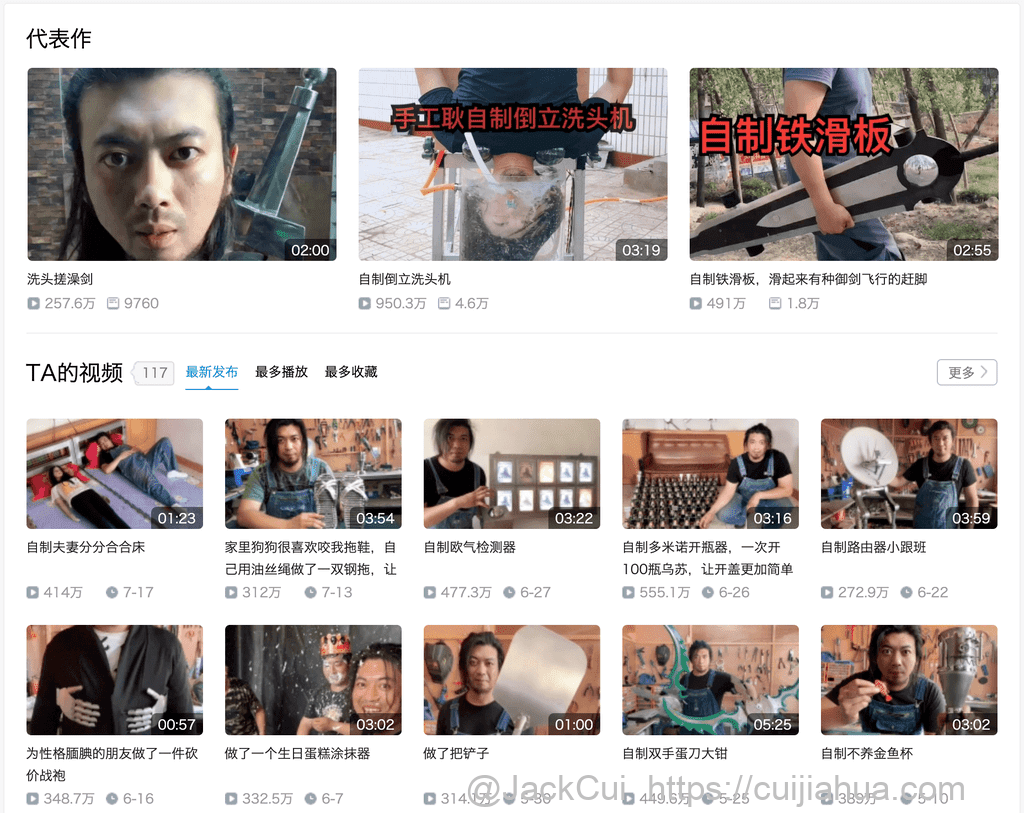
3

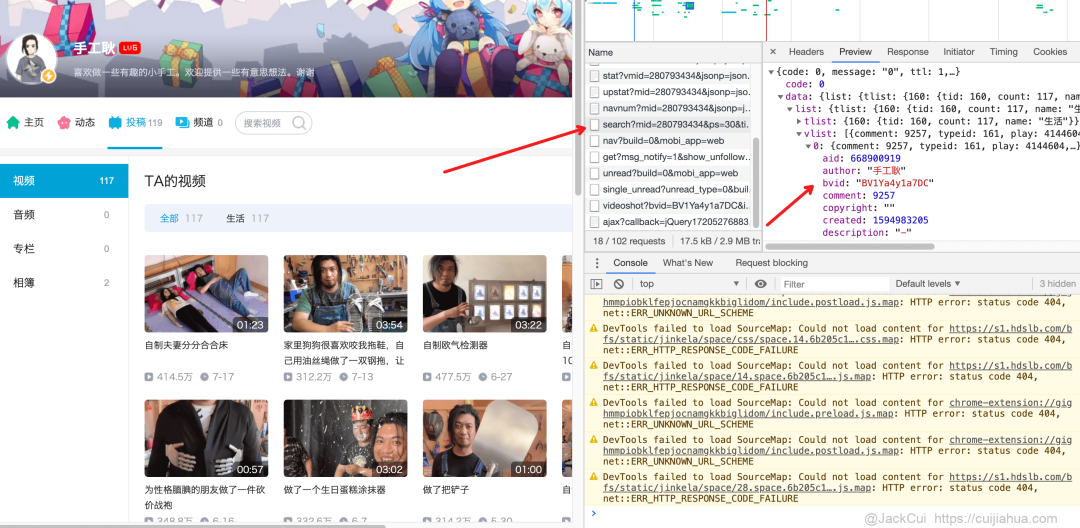
https://api.bilibili.com/x/space/arc/search?mid=280793434&ps=30&tid=0&pn=1&keyword=&order=pubdate&jsonp=jsonphttps://api.bilibili.com/x/space/arc/search?mid=280793434&ps=30&tid=0&pn=1https://space.bilibili.com/280793434# -*-coding:utf-8 -*-# Website: https://cuijiahua.com# Author: Jack Cui# Date: 2020.07.22import requestsimport jsonimport mathspace_url = 'https://space.bilibili.com/280793434'search_url = 'https://api.bilibili.com/x/space/arc/search'mid = space_url.split('/')[-1]sess = requests.Session()search_headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36','Accept-Language': 'zh-CN,zh;q=0.9','Accept-Encoding': 'gzip, deflate, br','Accept': 'application/json, text/plain, */*'}# 获取视频个数ps = 1pn = 1search_params = {'mid': mid,'ps': ps,'tid': 0,'pn': pn}req = sess.get(url=search_url, headers=search_headers, params=search_params, verify=False)info = json.loads(req.text)video_count = info['data']['page']['count']ps = 10page = math.ceil(video_count/ps)videos_list = []for pn in range(1, page+1):search_params = {'mid': mid,'ps': ps,'tid': 0,'pn': pn}req = sess.get(url=search_url, headers=search_headers, params=search_params, verify=False)info = json.loads(req.text)vlist = info['data']['list']['vlist']for video in vlist:title = video['title']bvid = video['bvid']vurl = 'https://www.bilibili.com/video/' + bvidvideos_list.append([title, vurl])print('共 %d 个视频' % len(videos_list))for video in videos_list:print(video[0] + ':' + video[1])
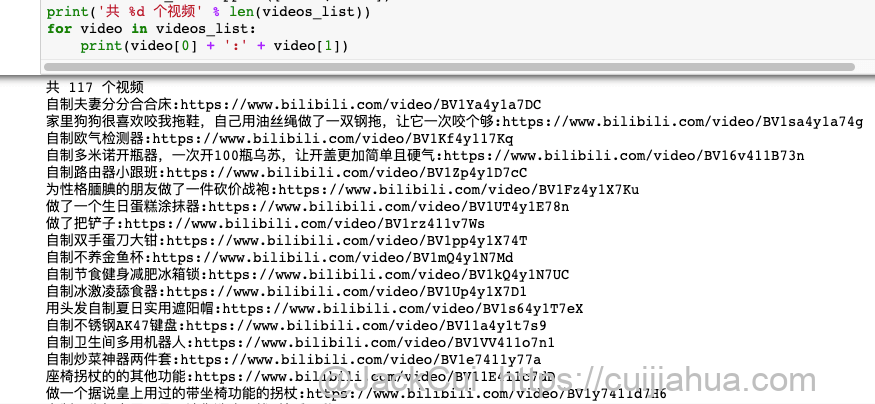
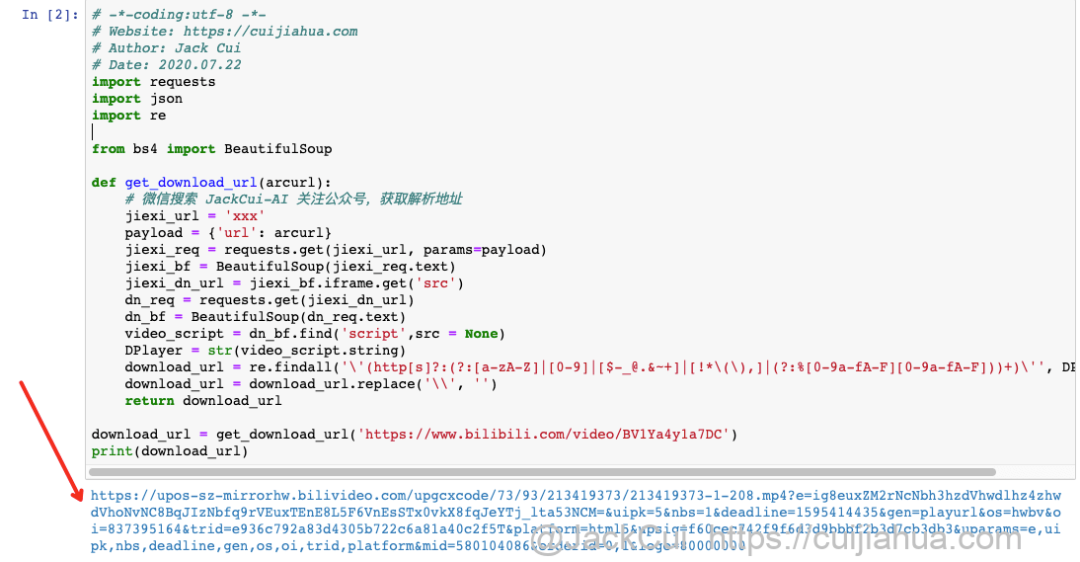
4
# -*-coding:utf-8 -*-# Website: https://cuijiahua.com# Author: Jack Cui# Date: 2020.07.22import requestsimport jsonimport refrom bs4 import BeautifulSoupdef get_download_url(arcurl):# 微信搜索 JackCui-AI 关注公众号,后台回复「B 站」获取视频解析地址jiexi_url = 'xxx'payload = {'url': arcurl}jiexi_req = requests.get(jiexi_url, params=payload)jiexi_bf = BeautifulSoup(jiexi_req.text)jiexi_dn_url = jiexi_bf.iframe.get('src')dn_req = requests.get(jiexi_dn_url)dn_bf = BeautifulSoup(dn_req.text)video_script = dn_bf.find('script',src = None)DPlayer = str(video_script.string)download_url = re.findall('\'(http[s]?:(?:[a-zA-Z]|[0-9]|[$-_@.&~+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+)\'', DPlayer)[0]download_url = download_url.replace('\\', '')return download_urldownload_url = get_download_url('https://www.bilibili.com/video/BV1Ya4y1a7DC')print(download_url)
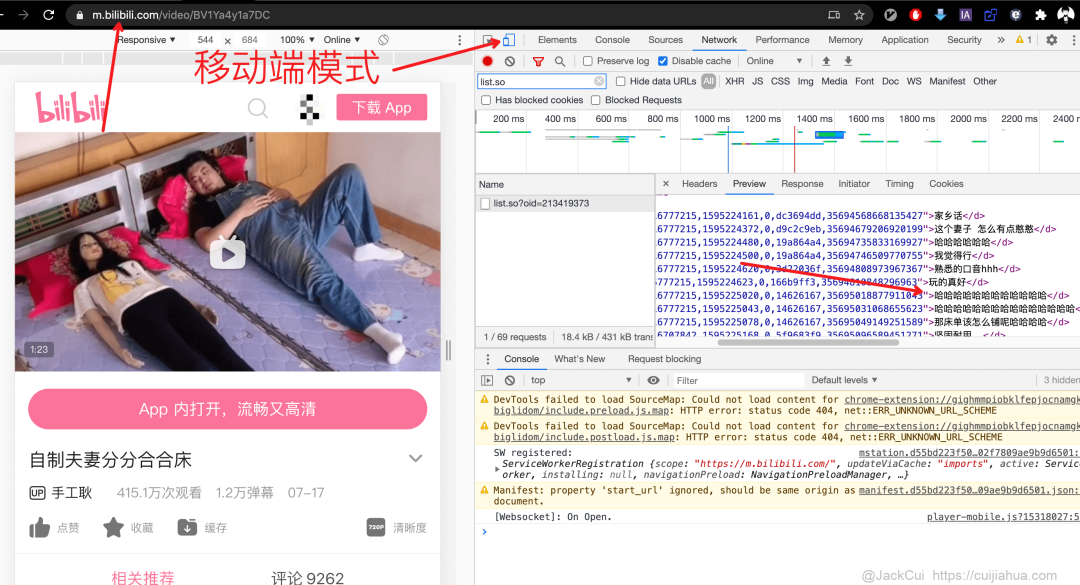
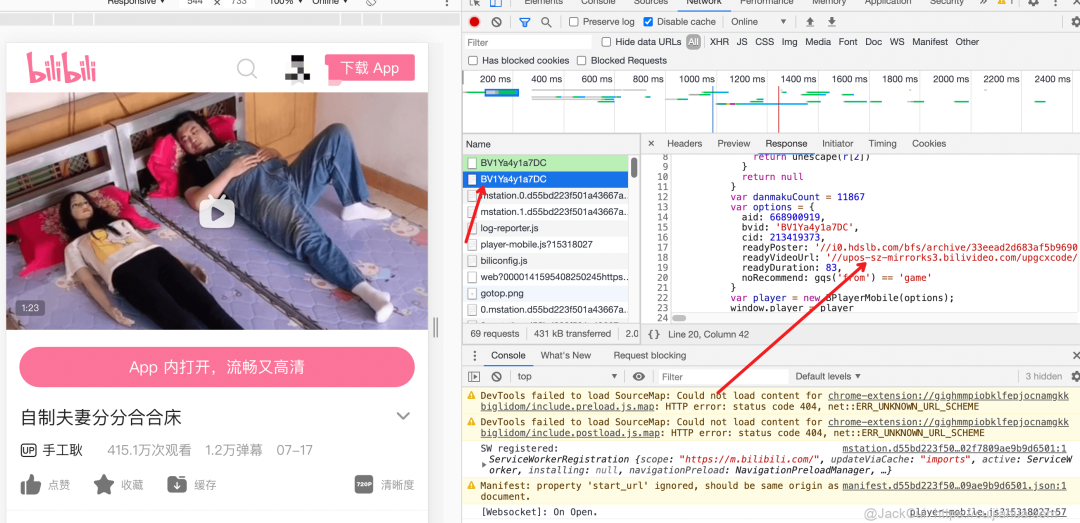
https://api.bilibili.com/x/v1/dm/list.so?oid=213419373# -*-coding:utf-8 -*-# Website: https://cuijiahua.com# Author: Jack Cui# Date: 2020.07.22import requestsimport xml2assimport timefrom contextlib import closingfilename = '自制夫妻分分合合床'danmu_name = filename + '.xml'danmu_ass = filename + '.ass'download_url = 'https://upos-sz-mirrorhw.bilivideo.com/upgcxcode/73/93/213419373/213419373-1-208.mp4?e=ig8euxZM2rNcNbh3hzdVhwdlhz4zhwdVhoNvNC8BqJIzNbfq9rVEuxTEnE8L5F6VnEsSTx0vkX8fqJeYTj_lta53NCM=&uipk=5&nbs=1&deadline=1595414435&gen=playurl&os=hwbv&oi=837395164&trid=e936c792a83d4305b722c6a81a40c2f5T&platform=html5&upsig=f60cec742f9f6d3d9bbbf2b3d7cb3db3&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=580104086&orderid=0,1&logo=80000000'oid = download_url.split('/')[6]danmu_url = 'https://api.bilibili.com/x/v1/dm/list.so?oid={}'.format(oid)print(danmu_url)sess = requests.Session()danmu_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36','Accept': '*/*','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9'}with closing(sess.get(danmu_url, headers=danmu_header, stream=True, verify=False)) as response:if response.status_code == 200:with open(danmu_name, 'wb') as file:for data in response.iter_content():file.write(data)file.flush()else:print('链接异常')time.sleep(0.5)xml2ass.Danmaku2ASS(danmu_name, danmu_ass, 1280, 720)

5
总而言之,更快更强。
程序调用迅雷下载,需要将迅雷设置为一键下载。
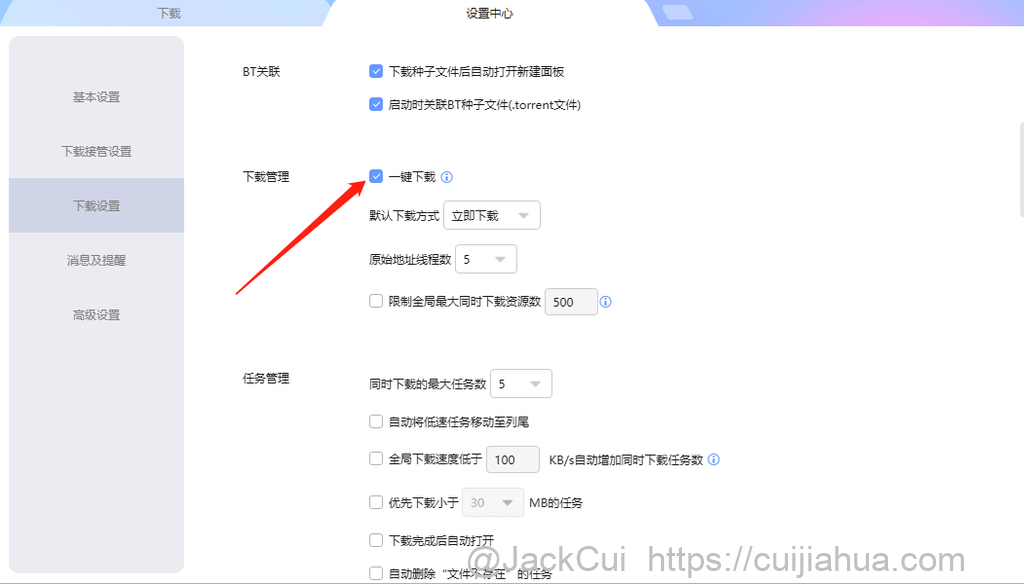
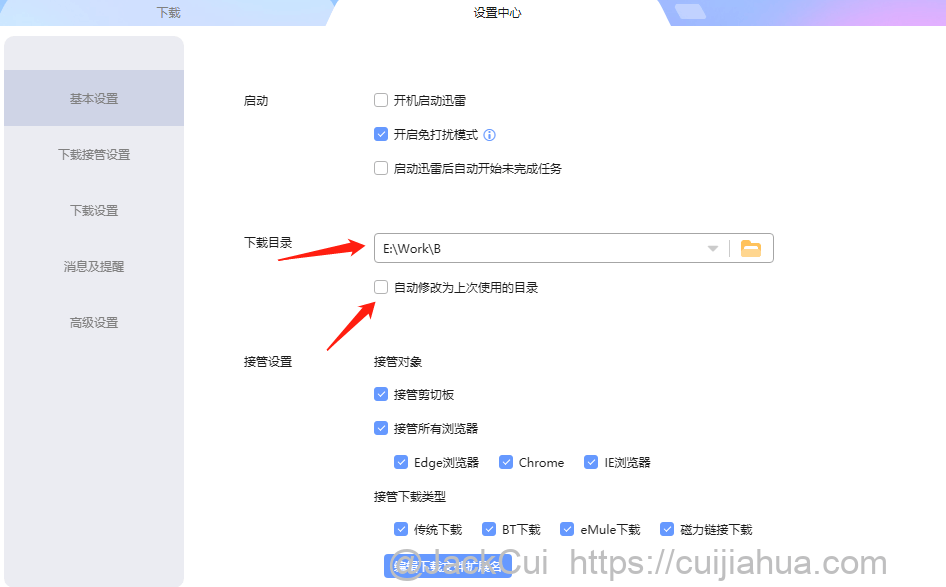
此外,再将迅雷下载目录改为,我们的工程目录,并将「自动修改为上次使用的目录」去掉。
import osimport timefrom win32com.client import Dispatchdef addTasktoXunlei(down_url):flag = Falseo = Dispatch('ThunderAgent.Agent64.1')try:o.AddTask(down_url, "", "", "", "", -1, 0, 5)o.CommitTasks()flag = Trueexcept Exception:print(Exception.message)print(" AddTask is fail!")return flagaddTasktoXunlei('ftp://b:b@dx.dl1234.com:8206/[电影天堂www.dy2018.com]战狼BD国语中字.rmvb')

6
# -*-coding:utf-8 -*-# Website: https://cuijiahua.com# Author: Jack Cui# Date: 2020.07.22import requestsimport jsonimport reimport jsonimport mathimport xml2assimport timefrom contextlib import closingfrom bs4 import BeautifulSoupimport osfrom win32com.client import Dispatchdef addTasktoXunlei(down_url):flag = Falseo = Dispatch('ThunderAgent.Agent64.1')try:o.AddTask(down_url, "", "", "", "", -1, 0, 5)o.CommitTasks()flag = Trueexcept Exception:print(Exception.message)print(" AddTask is fail!")return flagdef get_download_url(arcurl):# 微信搜索 JackCui-AI 关注公众号,后台回复「B 站」获取视频解析地址jiexi_url = 'xxx'payload = {'url': arcurl}jiexi_req = requests.get(jiexi_url, params=payload)jiexi_bf = BeautifulSoup(jiexi_req.text)jiexi_dn_url = jiexi_bf.iframe.get('src')dn_req = requests.get(jiexi_dn_url)dn_bf = BeautifulSoup(dn_req.text)video_script = dn_bf.find('script',src = None)DPlayer = str(video_script.string)download_url = re.findall('\'(http[s]?:(?:[a-zA-Z]|[0-9]|[$-_@.&~+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+)\'', DPlayer)[0]download_url = download_url.replace('\\', '')return download_urlspace_url = 'https://space.bilibili.com/280793434'search_url = 'https://api.bilibili.com/x/space/arc/search'mid = space_url.split('/')[-1]sess = requests.Session()search_headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36','Accept-Language': 'zh-CN,zh;q=0.9','Accept-Encoding': 'gzip, deflate, br','Accept': 'application/json, text/plain, */*'}# 获取视频个数ps = 1pn = 1search_params = {'mid': mid,'ps': ps,'tid': 0,'pn': pn}req = sess.get(url=search_url, headers=search_headers, params=search_params, verify=False)info = json.loads(req.text)video_count = info['data']['page']['count']ps = 10page = math.ceil(video_count/ps)videos_list = []for pn in range(1, page+1):search_params = {'mid': mid,'ps': ps,'tid': 0,'pn': pn}req = sess.get(url=search_url, headers=search_headers, params=search_params, verify=False)info = json.loads(req.text)vlist = info['data']['list']['vlist']for video in vlist:title = video['title']bvid = video['bvid']vurl = 'https://www.bilibili.com/video/' + bvidvideos_list.append([title, vurl])print('共 %d 个视频' % len(videos_list))all_video = {}# 下载前 10 个视频for video in videos_list[:10]:download_url = get_download_url(video[1])print(video[0] + ':' + download_url)# 记录视频名字xunlei_video_name = download_url.split('?')[0].split('/')[-1]filename = video[0]for c in u'´☆◦\/:*?"<>| ':filename = filename.replace(c, '')save_video_name = filename + '.mp4'all_video[xunlei_video_name] = save_video_nameaddTasktoXunlei(download_url)# 弹幕下载danmu_name = filename + '.xml'danmu_ass = filename + '.ass'oid = download_url.split('/')[6]danmu_url = 'https://api.bilibili.com/x/v1/dm/list.so?oid={}'.format(oid)danmu_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36','Accept': '*/*','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9'}with closing(sess.get(danmu_url, headers=danmu_header, stream=True, verify=False)) as response:if response.status_code == 200:with open(danmu_name, 'wb') as file:for data in response.iter_content():file.write(data)file.flush()else:print('链接异常')time.sleep(0.5)xml2ass.Danmaku2ASS(danmu_name, danmu_ass, 1280, 720)# 视频重命名for key, item in all_video.items():while key not in os.listdir('./'):time.sleep(1)os.rename(key, item)

7
使用迅雷下载,速度飞起。用本文的方法,爬 B 站视频,就很舒服。
代码、教程仅限于学习交流,请勿用于任何商业用途!
评论