
B站弹幕爬虫

作者:Huangwei AI
来源:Python与机器学习之路
B站作为弹幕文化的代表,有着非常丰富的弹幕资源。今天我们尝试对B站的弹幕进行爬虫并且绘制词云图展示爬虫结果。
 爬虫方式01PART
爬虫方式01PART众所周知,B站的内容非常丰富:

要想找到一个视频中的弹幕,我们其实有很多种方法。
给大家介绍Github上一个B站爬虫数据接口大全:
在这次爬虫中,我们使用【读取Up视频列表】的方式:

02PART基本信息
我们选取一位叫做【小时姑娘】的Up主来爬取:
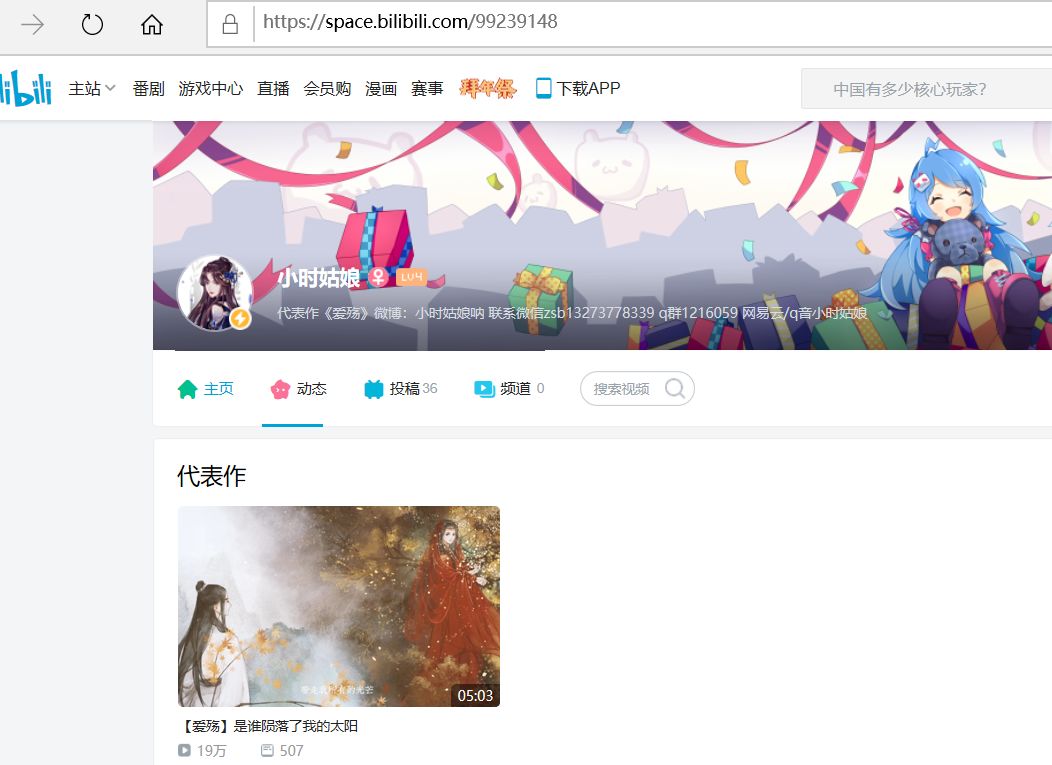
注意上面网址中的id=99239148,这是个核心信息。
由于我们是数据接口是列表的形式,所以原则上可以爬取该Up主的所有视频信息。
但是,这次我们专注于一个视频。
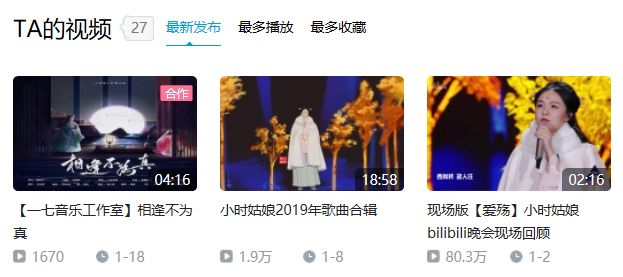
没错,就是上面图片中第三个视频,播放量为80.3万的现场版【爱殇】。
这个视频来自于bilibili晚会。弹幕和播放量都够我们爬的。
爬虫代码03PART我们爬虫的代码主要参考知乎的一个回答:
只需要根据Up主id信息以及视频在列表中位置就可以顺利爬虫:
import requestsimport reimport osimport sysimport json# B站API详情 https://github.com/Vespa314/bilibili-api/blob/master/api.md# 视频AV号列表aid_list = []# 评论用户及其信息info_list = []# 获取指定UP的所有视频的AV号 mid:用户编号 size:单次拉取数目 page:页数def getAllAVList(mid, size, page):for n in range(1,page+1):url = "http://space.bilibili.com/ajax/member/getSubmitVideos?mid=" + str(mid) + "&pagesize=" + str(size) + "&page=" + str(n)r = requests.get(url)text = r.textjson_text = json.loads(text)print (json_text)# 遍历JSON格式信息,获取视频aidfor item in json_text["data"]["vlist"]:aid_list.append(item["aid"])print(aid_list)# 获取一个AV号视频下所有评论def getAllCommentList(item):url = "http://api.bilibili.com/x/reply?type=1&oid=" + str(item) + "&pn=1&nohot=1&sort=0"r = requests.get(url)numtext = r.textjson_text = json.loads(numtext)commentsNum = json_text["data"]["page"]["count"]page = commentsNum // 20 + 1for n in range(1,page):url = "https://api.bilibili.com/x/v2/reply?jsonp=jsonp&pn="+str(n)+"&type=1&oid="+str(item)+"&sort=1&nohot=1"req = requests.get(url)text = req.textjson_text_list = json.loads(text)for i in json_text_list["data"]["replies"]:info_list.append([i["member"]["uname"],i["content"]["message"]])# print(info_list)# 保存评论文件为txtdef saveTxt(filename,filecontent):filename = str(filename) + ".txt"for content in filecontent:with open(filename, "a", encoding='utf-8') as txt:txt.write(content[0] +' '+content[1].replace('\n','') + '\n\n')print("文件写入中")if __name__ == "__main__":# 爬取小时姑娘 只爬取第一页的第一个getAllAVList(99239148,3,1)for item in aid_list:info_list.clear()getAllCommentList(item)saveTxt(item,info_list)
04PART词云图

我们将结果通过词云图的方式展示出来:
可以看出来,弹幕还是非常丰富多彩的。
有夸唱的好听的,有提到小时姑娘名字的,还有卧槽,哈哈哈。
值得注意的是里面有很多提到了东宫,查了一下资料才发现这首歌原来已经出现很久了:
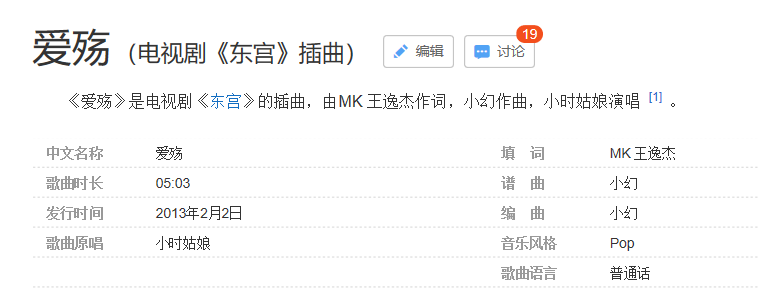
大家感兴趣的话,可以去爬自己喜欢的视频哦。

·END·
◆ ◆ ◆ ◆ ◆
长按二维码关注我们
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
评论