
读光OCR-文字识别技术解读与ctc center loss实现
共 2976字,需浏览 6分钟
·
2022-02-09 17:37
OCR商业应用场景
实现本文中一个crnn 改进的段落
相似字的解决方案如上图所示,之前无法解决相似字的原因是softmax不能有效的表征差异导致的偏差。现在提出了centerloss强化特征之间的差异,解决了形似字分类困难的问题。同时结合CTC和centerloss这两个技术,对30万形近字进行了测试,精确度从原来的83%提高到了97%。相似字得到了识别。
github:https://github.com/tommyMessi/crnn_ctc-centerloss
正文部分
OCR的本质是识别图片中的文字。根据需要处理的数据类型可以分为四种数据场景,数字原生类、文档类、拍照表单类和自然场景类。
数字原生类

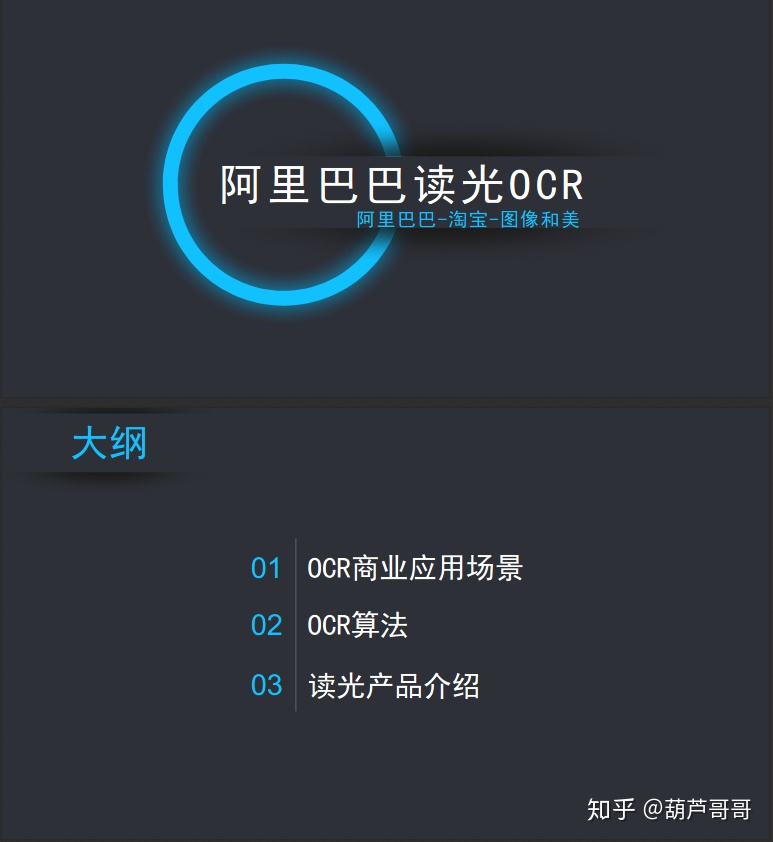
淘宝商品图是最具代表的数字原生类字图。图片中的文字是机器生成,后期添加到图片中。该类字图具有最复杂多样、最有价值和图片量最大等特征。在淘宝的商品图里面包含了各种各样的数字原生类图片,其中包含各种字体、背景、排列和组合等。阿里巴巴最近就淘宝商品图举行了一场比赛——MTWI挑战赛,这是目前最大的OCR竞赛。最有价值主要体现在淘宝图上除了有商品的图片以外,还有很多的文字信息,它是商品信息传递的一个载体;这个商品图汇聚了商家美工、制作等很多人的工作。图片数量巨大,淘宝商品的背后大概有千亿图片,而且这些图片非常的有活力,每日不停地更新。读光OCR在淘宝的商品图上做了大量的工作,目前覆盖了所有电商图片的OCR识别。
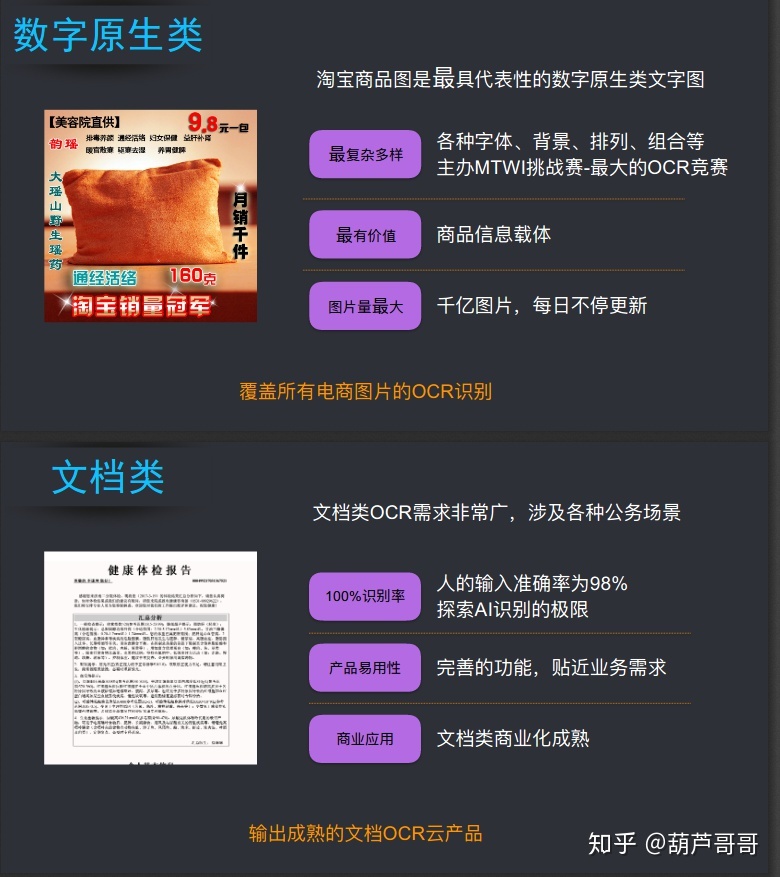
文档类OCR需求非常的广,涉及各种公务场景。文档类图片相对于其他类文档相对简单,没有复杂的背景、复杂的字体,但是需要做到100%的识别率。正常人在放松情况下的输入准确率为98%,在此基础上探索AI识别的极限;读光的
易用性是完善的功能,贴近业务的产品需求实现;文档类商业的成熟更加易于商业的应用。读光也在阿里云上输出成熟OCR云产品的文档。


拍照表单类OCR价值非常大,比较复杂,也非常具有挑战性。根据场景和数据得知,拍照表单类的数据具有隐私性,拍照表单应用都是和我们个人信息息息相关的,比如个人身份证、结婚证、房产证等等,需要典型的应用场景沉淀技术能力;拍照类表单的应用范围非常的广,所以需要制定一套通用性的解决方案。读光提出了一种专家知识+模板=文本理解的结构模式,这样一套方案能够解决文字识别和结构化的功能,实现了产品的通用性。它的商业价值和行业场景深度接入,AI能力改善行业数据流程。阿里云提供了定制的拍照表格识别和结构化云服务。
自然场景类是OCR学术研究的重点方向,没有具体的数据类型定义,比如街拍数据;目前遇到的本质的技术难点是定位和识别;市场的商业价值非常的大,主要应用于车牌识别、摄像监控和自动驾驶等。目前读光OCR具有相对领先的技术能力

OCR算法


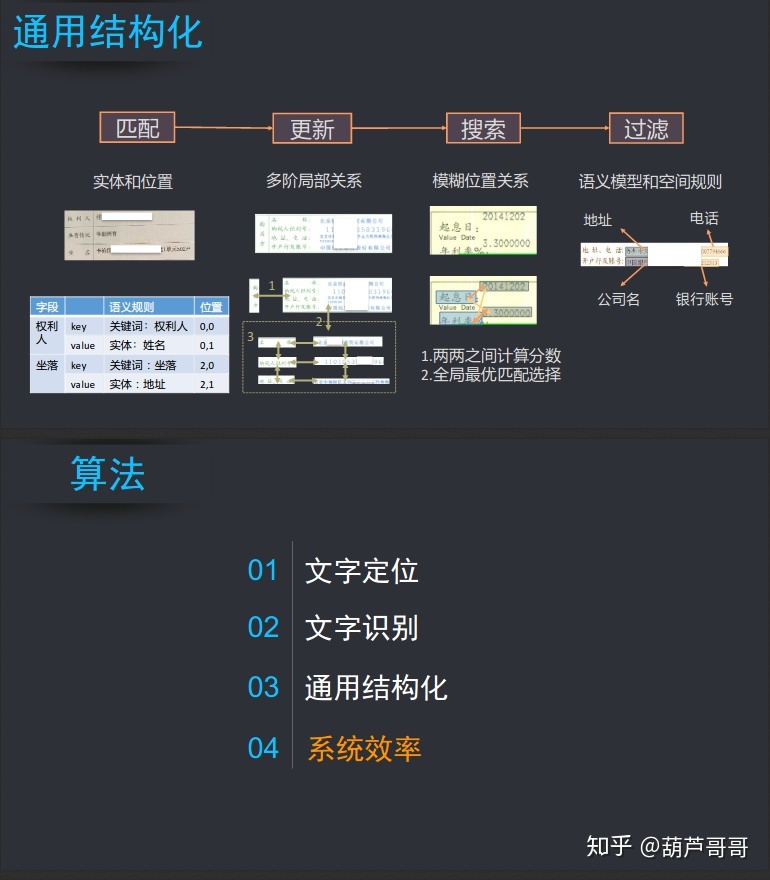
算法如上图所示,该算法是在CV的基础上进行扩展的,首先是基于文字定位和文字识别的,根据图片进行图像分析、图像提取和表格提取。需要根据应用进行结构化,根据实体的检测,同时根据语义和图形图像的空间关系实现结构的关系,最后实现文本的理解,文本分析和KV结构化输出。根据工程设计的能力实现相应的产品,需要考虑深度学习引擎的环境,通过私有云系统进行输出。通过文本理解和工程设计,最终实现了产品的构建。产品的输出包括通用OCR、文档OCR、表单OCR、OCR小程序、端上OCR。
文字定位
文字定位的目标是定位文字在图像中的位置并表征成行。背景特征的干扰问题,特征问题是不可避免的问题,随着深度学习发展,现在已经能够较好的解决特征问题点。
scale问题就是物体定位的共性问题,在复杂的图片中,文字的高度也是不同,需要解决更好的识别文字;这个问题经过如图上进程不断地改进,最终通过统一样本学习,多尺度特种输出和多尺度Attention融合已经得到了解决


成行的问题是文字定位特有的问题,文字可能横着、斜着甚至是弧形的排列。刚开始使用行mask解决,但是存在粘连问题;后来定义了行,但是发现定义不清,很难进行标注;最后用起始和方向进行行定义,如果知道行的起始、结尾和方向就可以很容易的定义行,解决了行粘连问题。
文字识别
文字识别就是在文字定位的基础上,识别文字内容同时,输出单字位置和识别用于文本的理解。文字识别包含分类和序列两部分,分类就是精细特征的提取问题;序列就是从人的认知进行分析。
文字识别存在的两大难题就是相似字和生僻字的识别。相似字识别是学术难题。现在发现一共有2278个形近字,CRN对这2278个字进行单独的识别测试,识别率只达到83%,最终发现识别率低的原因是softmax不能有效的表征差异导致的偏差。常用汉字大约有3700个,覆盖了99%书面资料,但是姓名、地名大概有21303个,包含大量的生僻字,而且姓名和地名在我们的实际应用中又有着非常重要的价值。CRN进行测试发现识别率只达到21%。样本量的过少,不能进行充分的训练,识别率很难进行提高


生僻字的解决方法如上图所示,首先使用行识别,再进行了Attention单字识别方案解决了生僻字语料偏少的问题,Attention可以解决单字切字问题。通过上述方法,我们对2万多生僻字测试集进行了测试,精确度从21%提高到了99%,基本上解决了生僻字问题。
相似字的解决方案如上图所示,之前无法解决相似字的原因是softmax不能有效的表征差异导致的偏差。现在提出了centerloss强化特征之间的差异,解决了形似字分类困难的问题。同时结合CTC和centerloss这两个技术,对30万形近字进行了测试,精确度从原来的83%提高到了97%。相似字得到了识别。github:https://github.com/tommyMessi/crnn_ctc-centerloss
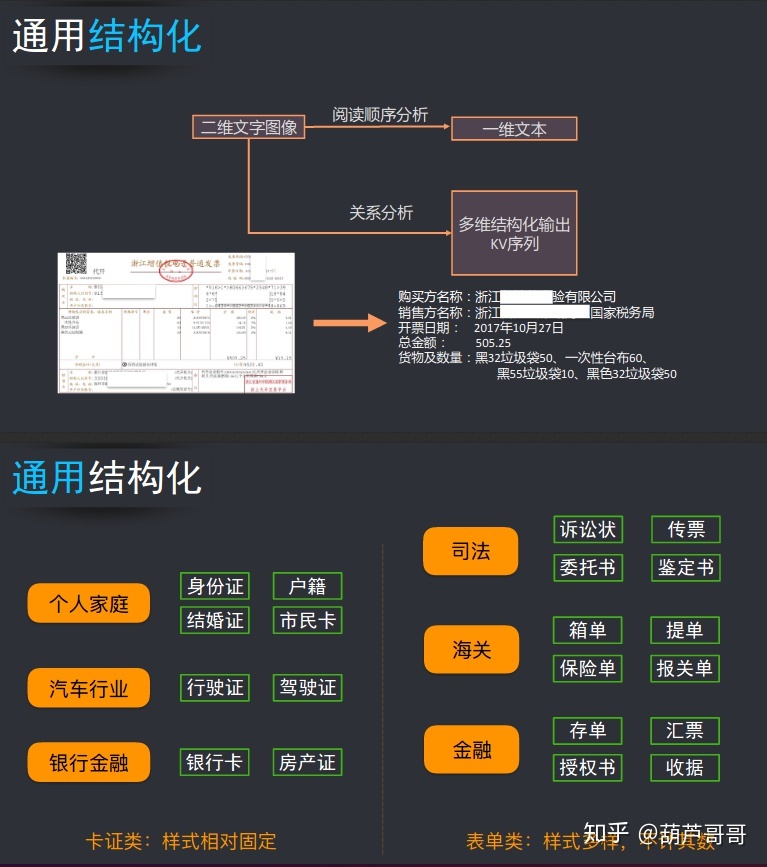
通用结构化
通用结构化中结构化的目的是把二维文字图像转化成一维文字或多维结构化输出KV序列。一维文本就是按照阅读顺序进行分析,多维结构化是通过关系分析。例如卡证类,样式是相对固定的,但是种类非常的繁多。表单类样式更加的多样,不计其数。因为种类的繁多,我们必须通用化的结构才能解决繁重的工作量。
通用结构化的实现包括匹配、更新、搜索和过滤四部分。匹配是通过实体和全局的位置实现KV的关系对;更新是通过多阶的局部关系来实现更新;搜索是模糊位置关系的处理,首先需要对模糊的位置进行计算分数,然后进行全局最优的方式进行选择。过滤是当不同信息混合在一起时,使用语义模型和空间规则进行处理分离


读光产品主要包括全文识别产品和结构化产品。全文识别产品用于多场景的普通性文字识别算法体系,具有高效性、通用性和高实时性。结构化产品链接行业知识和算法,具有高鲁棒性、易配置和扩展性强。读光OCR在阿里落地,主要应用在内容质量管理、内容知识挖掘和运营效率提高三个方面,实现智能化电商平台治理,商品信息化实现商品信息大全,智能运营代替人工运营。读光OCR已进行集团全覆盖,已处理2000亿张图,覆盖阿里云的淘宝、1688、支付宝、钉钉等公司。读光OCR云产品在云上也推出了通用文字识别和通用结构化。主要用于信息治理、内容知识挖掘和表单结构化
欢迎批评指正,欢迎交流勾搭~
对OCR感兴趣的小伙伴,也可以加入我们的微信群,一起交流。
由于群权限设置,请加群主微信(a28992932),由群主拉进群。