
文字识别中CTC损失的直觉解释
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

非常直观的解释了文字识别中非常常用的CTC损失和解码的操作。

如果你想让计算机识别文本,神经网络(NN)是一个不错的选择,因为它们目前的表现优于所有其他方法。这里的神经网络通常由卷积层(CNN)和递归层(RNN)组成,前者用于提取特征序列,后者用于通过该序列传递信息。它输出每个序列元素的字符得分,它只需要用一个矩阵来表示。现在,我们想对这个矩阵做两件事:
训练:计算神经网络的损失来训练网络
推断:解码矩阵,得到包含在输入图像中的文本
这两项任务都由CTC操作完成。手写识别系统概述如图1所示。
让我们更仔细地看看CTC操作,并讨论它是如何工作的,剖析一下它所基于的复杂公式背后的巧妙思想。最后,如果你感兴趣,我会给你一些参考资料,你可以在其中找到Python代码和(不太复杂的)公式。
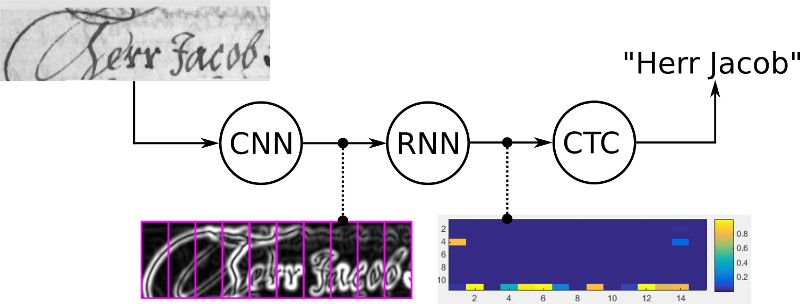
当然,我们可以用文本行图像创建一个数据集,然后为图像的每个水平位置指定相应的字符,如图2所示。然后,我们可以训练一个神经网络输出每个水平位置的字符得分。然而,这种解决方案有两个问题:
在字符级标注数据集非常耗时(而且枯燥)。
我们只得到字符分数,因此需要进一步处理才能得到最终文本。一个字符可以跨越多个水平位置,例如,我们可以得到“ttooo”,因为“o”是一个宽字符,如图2所示。我们必须删除所有重复的“t”和“o”。但如果被认可的文本是“too”呢?删除所有重复的“o”会得到错误的结果。如何处理这个问题?

我们只需要告诉CTC loss函数图像中出现的文本。因此,我们忽略了图像中字符的位置和宽度。
不需要对已识别的文本进行进一步处理。
CTC如何工作
正如已经讨论过的,我们不希望在每个水平位置上对图像进行标注(从现在开始,我们将其称为time-step)。神经网络的训练将以CTC损失函数为指导。我们只将神经网络的输出矩阵和相应的ground-truth(GT)文本输入到CTC损失函数中。但是它如何知道每个字符出现在哪里呢?它不知道。相反,它尝试图像中GT文本的所有可能的对齐,并对所有的得分求和。这样,如果对齐分数的求和值很高,则GT文本的分数就很高。
文本编码
还有一个问题是如何编码重复的字符(还记得我们说过的“too”吗?),它通过引入一个伪字符(称为blank,但不要将它与“真正的”blank混淆,即空白字符)来解决。在下面的文本中,这个特殊字符将被表示为“-”。我们使用一个聪明的编码模式来解决重复字符的问题:在编码文本时,我们可以在任何位置插入任意多的空格,而在解码时这些空格将被删除。但是,我们必须在重复的字符之间插入空格,比如“hello”。此外,我们可以重复每个字符,只要我们喜欢。
我们来看一些例子:
“to”→“ttttttooo”,或“-t-o”,或“to”
“too”- >“ttttto - o”或“- t - o - o”,或“- o”,但不能是“too”
正如你所看到的,这个模式还允许我们轻松地创建相同文本的不同对齐,例如“t-o”和“too”以及“-to”都表示相同的文本(“to”),但是对图像的对齐不同。该神经网络被训练成输出编码文本(编码在神经网络输出矩阵中)。
损失的计算
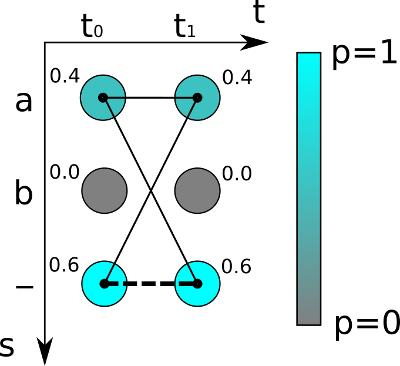
我们需要计算给定对图像和GT文本的损失值来训练神经网络。你已经知道,NN在每个时间步长输出一个矩阵,其中包含每个字符的得分。一个极小矩阵如图3所示:有两个时间步长(t0, t1)和三个字符(“A”,“b”和空白“-”)。每个时间步的字符得分总和为1。
此外,你已经知道损失的计算方法是将GT文本的所有可能对齐的所有得分相加,这样,文本在图像中出现的位置就不重要了。
一个对齐(或path,通常在文献中称为path)的得分是通过将相应的字符得分相乘来计算的。在上面的例子中,路径“aa”的得分为0.4·0.4=0.16,路径“a-”的得分为0.4·0.6=0.24,路径“a”的得分为0.6·0.4=0.24。为了得到给定GT文本的分数,我们对与此文本对应的所有路径的分数求和。假设示例中的GT文本是“a”:我们必须计算长度为2的所有可能路径(因为矩阵有2个时间步长),即:“aa”、“a-”和“a-”。我们已经计算了这些路径的得分,所以我们只需要对它们求和,得到0.4·0.4+0.4·0.6+0.6·0.4=0.64。假设GT文本为“”,我们看到只有一条对应的路径,即“--”,得到总分0.6·0.6=0.36。
如果你仔细看,你会发现我们计算的是GT文本的概率,而不是损失。然而,损失只是概率的负对数。损失值通过神经网络反向传播,神经网络的参数根据所使用的优化器进行更新,在此不再赘述。
当我们有一个训练过的神经网络时,我们通常想要用它来识别以前没有见过的图像中的文本。或者用更专业的术语来说>我们希望计算给定神经网络输出矩阵的最有可能的文本。你已经知道了计算给定文本得分的方法。但这一次,我们没有得到任何文本,事实上,这正是我们要找的文本。如果只有几个时间步骤和字符,那么尝试所有可能的文本都是可行的,但是对于实际的情况下,这是不可行的。
一个简单而快速的算法是最佳路径解码,它包括两个步骤:
它通过在每个时间步中选择最可能的字符来计算最佳路径。
它首先删除重复的字符,然后从路径中删除所有空格,从而撤消编码。剩下的表示已识别的文本。
如图4所示。字符是“a”、“b”和“-”(空白)。有5个时间步骤。让我们对这个矩阵应用我们最好的路径解码器:t0最可能的字符是“a”,同样适用于t1和t2。空白字符在t3处得分最高。最后,“b”最有可能出现在t4。这给出了路径aaa-b。我们删除重复的字符,这将生成“a-b”,然后从剩余的路径中删除任何空白,这将生成文本“ab”,我们将其输出为可识别的文本。
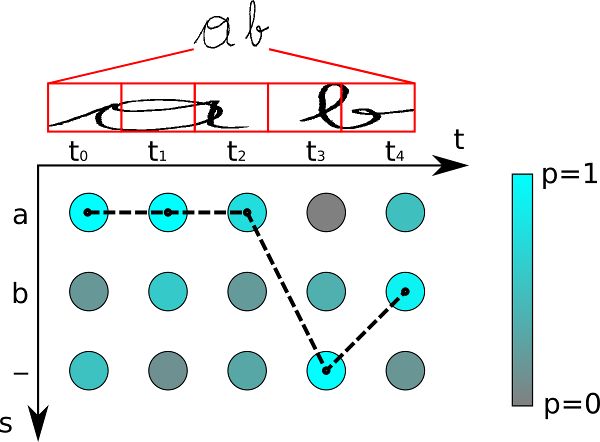
当然,最佳路径解码只是一种近似。对于它给出错误结果的例子很容易构造:如果你从图3中解码矩阵,你将得到“”作为可识别的文本。但是我们已经知道""的概率只有0.36而"a"的概率是0.64。然而,这种近似算法在实际应用中往往能得到较好的结果。还有一些更高级的译码器,如beam-search解码器、prefix-search解码器和令牌传递译码器,它们也利用语言结构的信息来改进解码结果。
首先,我们研究了神经网络解决方案所产生的问题。然后,我们看到CTC是如何解决这些问题的。然后,我们通过研究CTC如何编码文本、如何进行损失计算以及如何解码CTC训练的神经网络的输出来研究CTC的工作原理。
这将使你可以很好地理解在TensorFlow中调用ctc_loss或ctc_greedy_decoder等函数时,幕后发生了什么。然而,当你想要自己实现CTC时,你需要了解更多的细节,尤其是想使它运行得更快。Graves等人[1]介绍了CTC运算,并给出了所有相关的数学计算。如果你对如何改进解码感兴趣,请参阅有关beam-search解码的文章。我用Python和c++实现了一些解码器和损失函数,你可以在github上找到。最后,如果你想了解如何识别(手写)文本的全局,请参阅我关于如何构建手写文本识别系统的文章。
小白团队出品:零基础精通语义分割↓↓↓

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~