
Sharding-JDBC基本使用,整合Springboot实现分库分表,读写分离
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
一、Sharding-JDBC介绍
1、这里引用官网上的介绍:
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
2、自己的理解:
增强版的JDBC驱动,客户端使用的时候,就像正常使用JDBC驱动一样, 引入Sharding-JDBC依赖包,连接好数据库,配置好分库分表规则,读写分离配置,然后客户端的sql 操作 Sharding-JDBC会自动根据配置完成 分库分表和读写分离操作。
二、实现效果
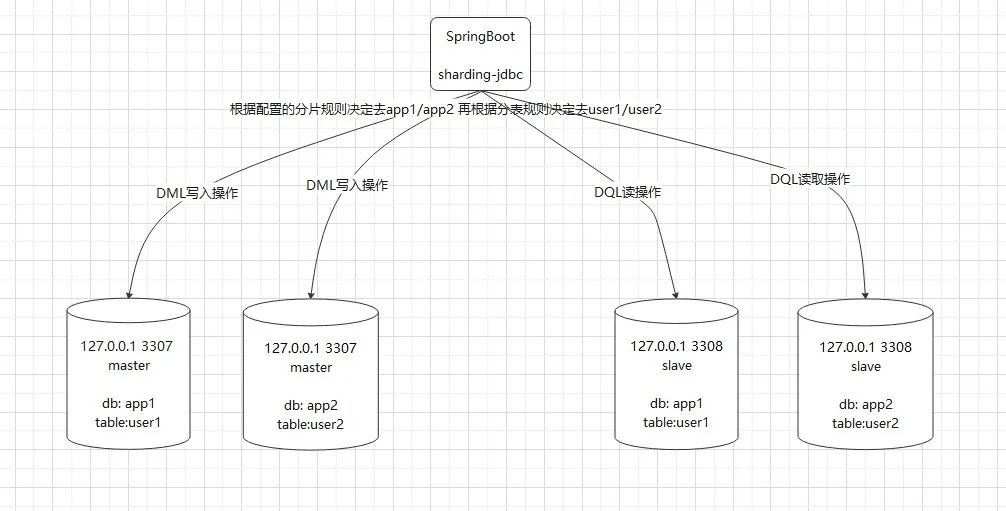
1、下图展示了我们通过Sharding-JDBC实现的分库分表及读写分离效果图
分库分表:结合上一篇的主从,这里我们使用上次搭建的主从数据库,3307的app1是主数据库,3308的app1是对应的从数据库。同时,我们在3307新建app2库和user2表,这里的app2库需要和app1库一样,user2表和user1表结构一样,主从会自动帮我们建表同步到3308,然后我们在项目中使用Sharding-JDBC 配置响应的分库分表策略,使得插入数据的时候 根据配置字段的分片规则将数据打入对应的库和表。在我们这里主要是 根据分库的分片规则决定数据进入3307的app1库还是app2库,然后再根据分表的分片规则决定进入user1表还是user2表。
读写分离:读写分离 在我们这里主要指的是 我们项目DQL会根据Sharding-JDBC配置的master-slave-rule走的3308的数据源,而项目的DML会根据master-slave-rule走3307的数据源
三、Spring-Boot项目整合Sharding-JDBC实现分库分表、读写分离
1、这里创建一个maven项目,首先引入依赖,pom.xml文件如下。
"1.0" encoding="UTF-8"?>
"http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.3.3.RELEASE
com.cgg
sharding-jdbc-test
1.0-SNAPSHOT
1.8
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
mysql
mysql-connector-java
8.0.15
com.alibaba
druid
1.1.21
com.baomidou
mybatis-plus-boot-starter
3.1.1
com.baomidou
mybatis-plus-extension
3.1.1
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
4.0.0-RC1
org.projectlombok
lombok
org.springframework.boot
spring-boot-maven-plugin
注意:这里使用的是4.0的sharding-jdbc,spring-boot的版本是2.x的,在整合过程中遇见了许多问题,后面会有错误的解决步骤。
2、application.yml文件如下
spring:
jpa:
properties:
hibernate:
hbm2ddl:
auto: create
dialect: org.hibernate.dialect.MySQL5Dialect
show_sql: true
shardingsphere:
props:
sql:
show: true
datasource:
names: master0,master0slave0,master1,master1slave0
master0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3307/app1?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: 654321
master1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3307/app2?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: 654321
master0slave0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3308/app1?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=GMT
username: root
password: 654321
master1slave0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3308/app2?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=GMT
username: root
password: 654321
sharding:
default-database-strategy:
inline:
sharding-column: id
algorithm-expression: app$->{(id % 2)+1}
tables:
user:
actual-data-nodes: app$->{1..2}.user$->{1..2}
table-strategy:
inline:
sharding-column: id
algorithm-expression: user$->{((""+id)[2..10].toInteger() % 2)+1}
key-generator:
column: id
type: SNOWFLAKE
master-slave-rules:
app1:
master-data-source-name: master0
slave-data-source-names: master0slave0
app2:
master-data-source-name: master1
slave-data-source-names: master1slave0
sharding:
jdbc:
config:
masterslave:
load-balance-algorithm-type: random
3、application.properties文件
spring.main.allow-bean-definition-overriding=true
mybatis-plus.mapper-locations= classpath:/mapper/*.xml
mybatis-plus.configuration.log-impl= org.apache.ibatis.logging.stdout.StdOutImpl
4、分库分表实现
4.1、先说下数据源,结合之前mysql主从的文章,我本地127.0.0.1:3307端口是主,127.0.0.1:3308端口是从。
在3307下建立两个库app1和app2,同时每个库里面建立两张表user1和user2表,用来完成分库分表。
下面是app1库SQL语句:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for user1
-- ----------------------------
DROP TABLE IF EXISTS `user1`;
CREATE TABLE `user1` (
`id` bigint(11) NOT NULL COMMENT '主键id',
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for user2
-- ----------------------------
DROP TABLE IF EXISTS `user2`;
CREATE TABLE `user2` (
`id` bigint(11) NOT NULL COMMENT '主键id',
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = DYNAMIC;
SET FOREIGN_KEY_CHECKS = 1;
下面是app2库SQL语句:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for user1
-- ----------------------------
DROP TABLE IF EXISTS `user1`;
CREATE TABLE `user1` (
`id` bigint(11) NOT NULL COMMENT '主键id',
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = DYNAMIC;
-- ----------------------------
-- Table structure for user2
-- ----------------------------
DROP TABLE IF EXISTS `user2`;
CREATE TABLE `user2` (
`id` bigint(11) NOT NULL COMMENT '主键id',
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
4.2、这里我们解释一下配置的分库分表规则实现将数据插入到app1和app2库,user1和user2表
sharding:
default-database-strategy:
inline:
sharding-column: id #分片的字段是id主键
algorithm-expression: app$->{(id % 2)+1} #分片的算法是 id对2求余然后加1
tables:
user:
actual-data-nodes: app$->{1..2}.user$->{1..2} #实际的数据节点是(app1/app2).(user1/user2)
table-strategy:
inline:
sharding-column: id #分表的分片字段是主键id
algorithm-expression: user$->{((""+id)[2..10].toInteger() % 2)+1} #分表的算法是取id的2-10位对2求余然后加1
key-generator:
column: id # 自动生成主键
type: SNOWFLAKE # 生成主键的规则是雪花算法
上面配置的规则指的是,当有数据要插入数据库,或者进行查询时,sharding-jdbc通过分片配置的字段id的值,去根据配置的算法 进行运算,得到结果,例如上述分库规则,拿到id值 对2求余加1,那么不管id怎么变化算法返回的值永远是1和2,即app$->{(id % 2)+1} 对应的就是app1和app2库,分表的规则是同样道理。
说明:这里只是配置了简单的分片规则来演示sharding-jdbc如何完成分库分表,我们也可以使用代码重写
方法来实现更复杂的分片策略。最后,这里的$->{(id % 2)+1} 的{}中实际上是一个Groovy语法的表达式,sharding-jdbc是通过Groovy语法糖来解析分片策略的。所以想要配置更为复杂的策略,建议学一下Groovy语法。
4.3、接下来我们介绍配置的读写分离规则,如何实现读写分离
master-slave-rules:
app1: #分区 app1
master-data-source-name: master0 #分区 app1的主数据源
slave-data-source-names: master0slave0 #分区 app1的从数据源
app2: #分区 app2
master-data-source-name: master1 #分区 app2的主数据源
slave-data-source-names: master1slave0 #分区 app2的从数据源
上面读写分离的规则指的是,分区app1的主从数据源,分区app2的主从数据源。至于这里的分区为什么是app1和app2?这里说明一下,我自己配置的时候,配置了几次都没有成功,一开始参照官网手册配置,以为分区名称可以自定义,于是配置的是ds0和ds1,但是项目启动报错了。报错信息是:Cannot find data source in sharding rule, invalid actual data node is: 'app1.user1'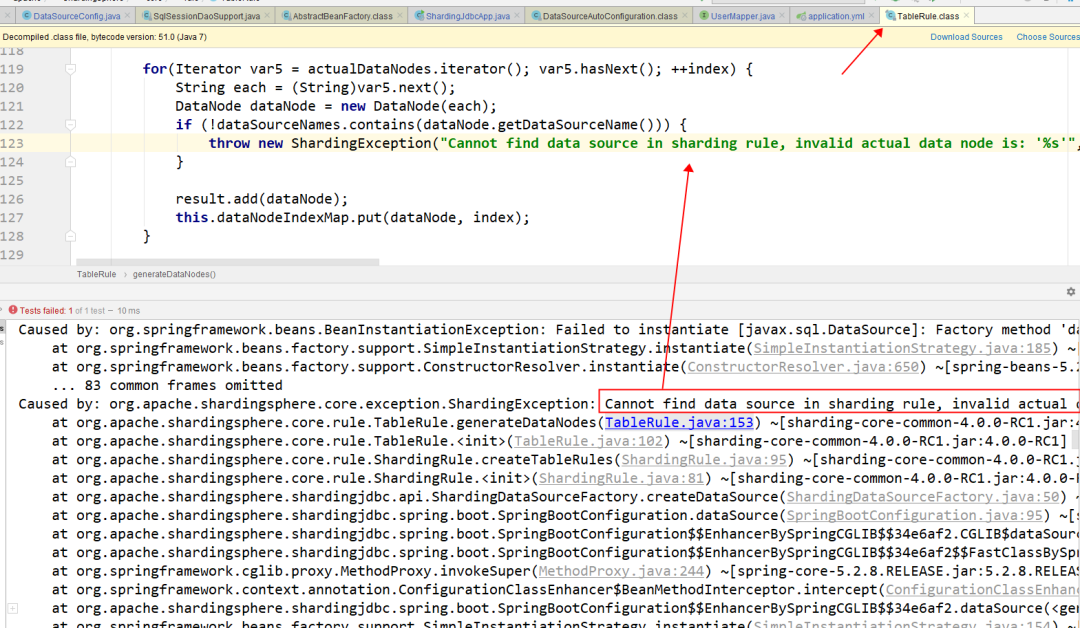
开始以为是使用的sharding-jdbc版本问题,但是换了版本还是有问题,于是开始调试了一下源码:
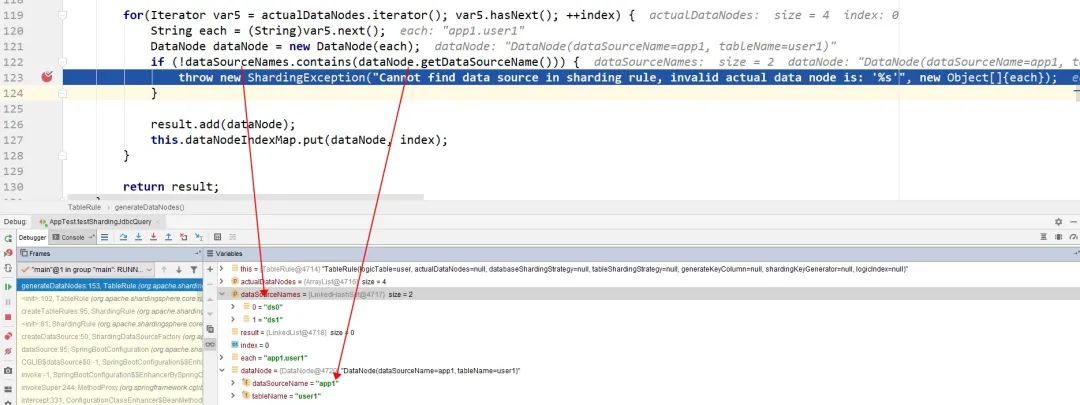
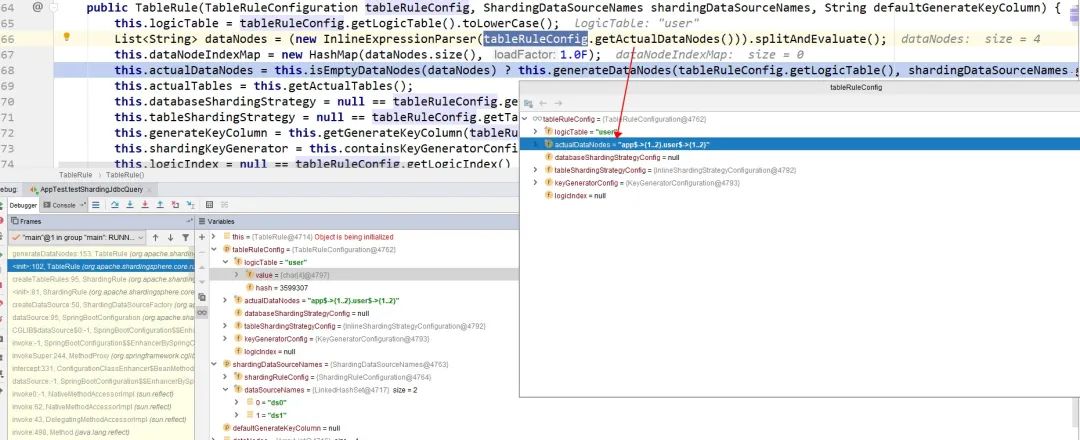
从上面的截图中很明显就能发现,这里是要判断我们配置的分区集合也就是ds0和ds1是否包含 实际节点的数据源名称,也就是数据库名称。所以这里的分区名称是和我们上面配置的分片策略的数据库名称有关系的。
4.4、验证
接下来我们验证实际的效果。这里贴一下单元测试的代码。
/**
* @author cgg
* @version 1.0.0
* @date 2021/10/25
*/
@SpringBootTest(classes = ShardingJdbcApp.class)
@RunWith(SpringRunner.class)
public class AppTest {
@Resource
private IUserService userService;
/**
* 测试sharding-jdbc添加数据
*/
@Test
public void testShardingJdbcInsert() {
userService.InsertUser();
}
/**
* 测试sharding-jdbc查询数据
*/
@Test
public void testShardingJdbcQuery() {
//全部查询
userService.queryUserList();
//根据指定条件查询
userService.queryUserById(1452619866473324545L);
}
}
/**
* @author cgg
* @version 1.0.0
* @date 2021/10/25
*/
@Service
@Slf4j
public class UserServiceImpl implements IUserService {
@Resource
private UserMapper userMapper;
@Resource
private DataSource dataSource;
@Override
public List queryUserList() {
List userList = userMapper.queryUserList();
userList.forEach(user -> System.out.println(user.toString()));
return userList;
}
@Override
public User queryUserById(Long id) {
User user = userMapper.selectOne(Wrappers.lambdaQuery().eq(User::getId, id));
System.out.println(user.toString());
return user;
}
@Override
public void InsertUser() {
for (int i = 20; i < 40; i++) {
User user = new User();
user.setName("XX-" + i);
int count = userMapper.insert(user);
System.out.println(count);
}
}
}
4.4.1、首先看全部查询的结果
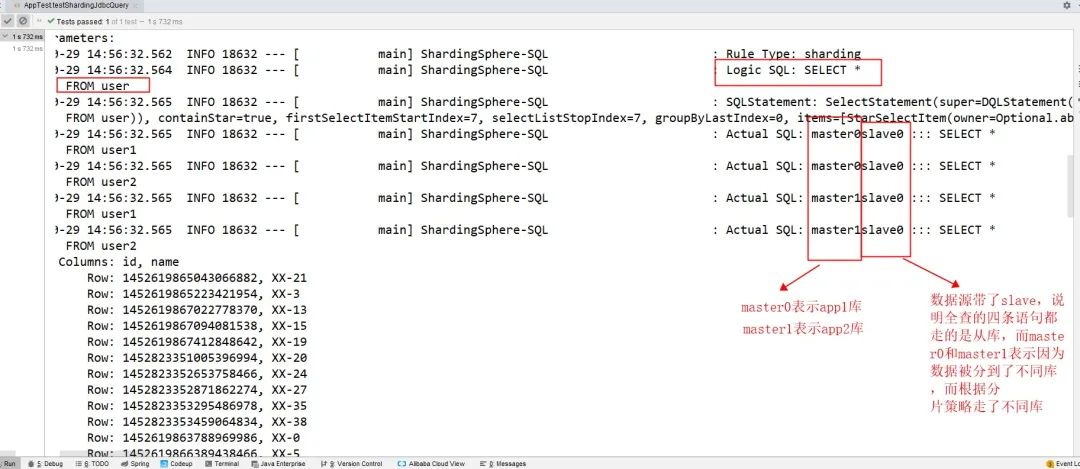
4.4.2、再看下单条查询的结果
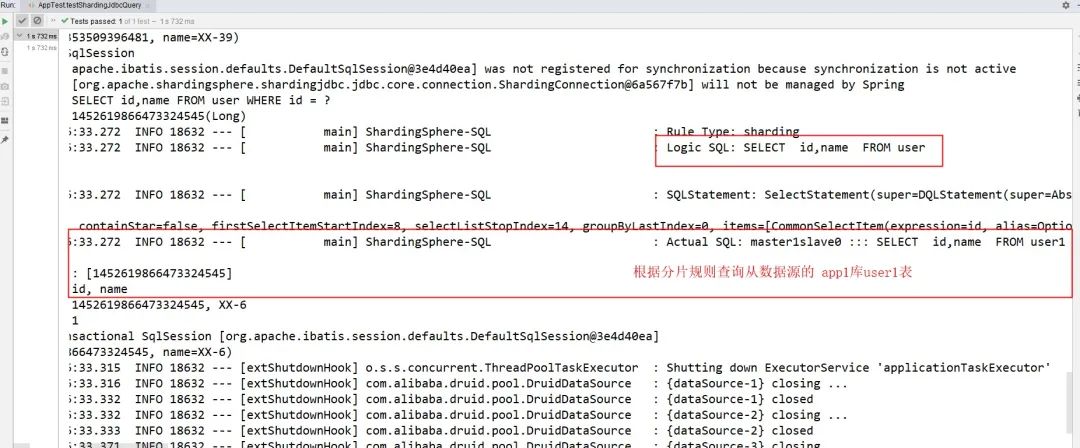
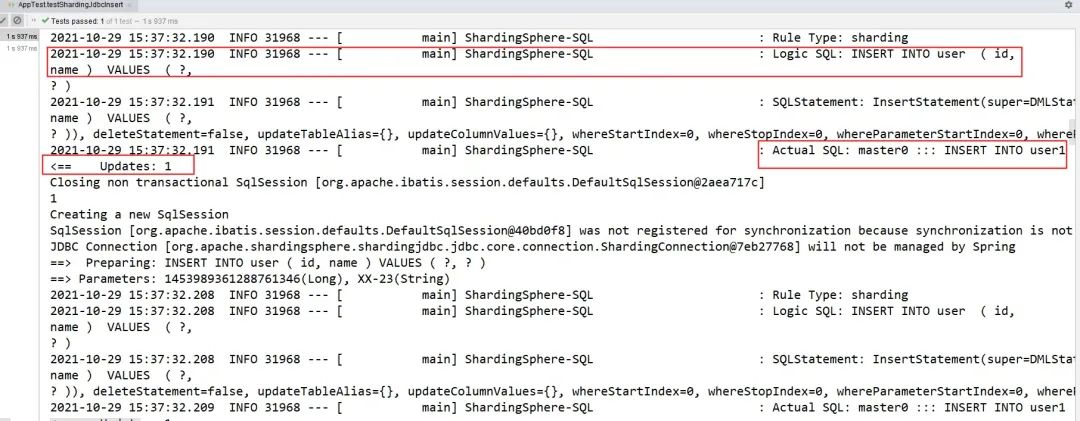
4.4.3、再看下新增结果(实际插入到了主数据源的app1库user1表,并且后续每条插入都是走的主数据源,没有slave的操作)
作者 | coffeebabe
来源 | cnblogs.com/wa1l-E/p/15465884.html
