
ConcurrentHashMap的实现原理(JDK1.7和JDK1.8)
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
JDK1.8之前
HashMap的底层是数组+链表结合在一起使用。
1、HashMap 通过 key 的hashCode 经过哈希函数处理过后得到 hash 值;
2、然后通过 (n - 1) & hash 判断当前元素存放的位置(n 指的是数组的长度);
3、如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash值以及 key是否相同;
4、如果相同的话,直接覆盖;
5、不相同就通过拉链法解决冲突。
JDK1.8之后
HashMap的底层数据结构为数组+链表+红黑树实现
当链表的长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索的时间。
将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树。
ConcurrentHashMap
JDK5中添加了新的concurrent包,在线程安全的基础上提供了更好的写并发能力,但同时降低了对读一致性的要求。
ConcurrentHashMap是java.util.concurrent下的类;
在并发编程中,ConcurrentHashMap是一个经常被使用的数据结构,它的实际与实现非常精巧,大量利用volatile,final,CAS等技术来减少锁竞争对于性能的影响。
简单的对比
HashTable 是一个线程安全的类,它使用synchronized来锁住整张Hash表来实现线程安全,每次锁住整张表让线程独占,相当于所有线程进行读写时都去竞争同一把锁,效率比较低
HashMap 不是一个线程安全的类
ConcurrentHashMap可以做到读取数据不加锁,并且其内部的结构可以让其在进行写操作的时候能够将锁的粒度保持地尽量地小,允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。只要不争夺同一把锁,它们就可以并发进行。
JDK1.7
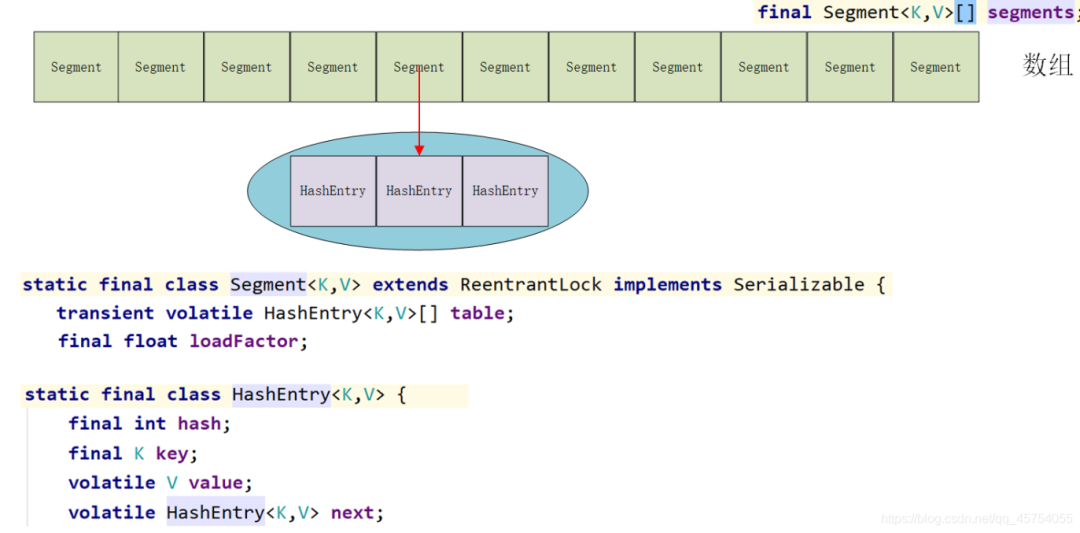
1、底层的数据结构还是数组+链表。链表的结点是HashEntry
2、采用了segment分段锁技术,在多线程并发更新操作时,对同一个segment进行同步加3 锁,保证数据安全。
3、同步的实现方式使基于ReentrantLock(Segment继承自ReentrantLock)
4、存在Hash冲突时,链表的查询效率低
JDK1.8
ContcurrentHashMap基于JDK1.8的源码剖析
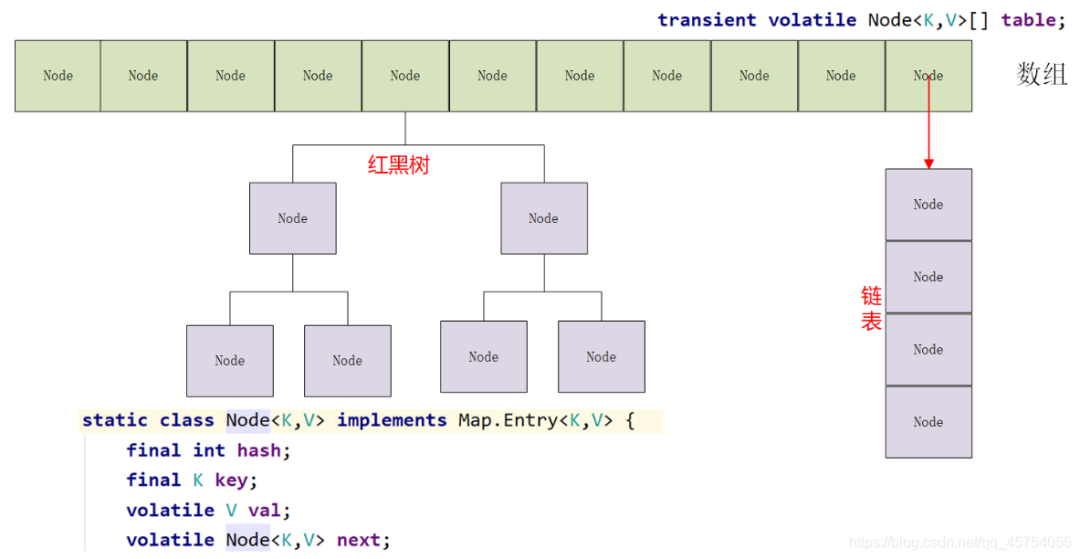
底层的数据结构与HashMap1.8版本一样,都是基于数组+链表+红黑树
支持多线程的并发操作,实现的原理是CAS+synchronized保证并发更新
检索操作不用加锁,get方法是非阻塞的
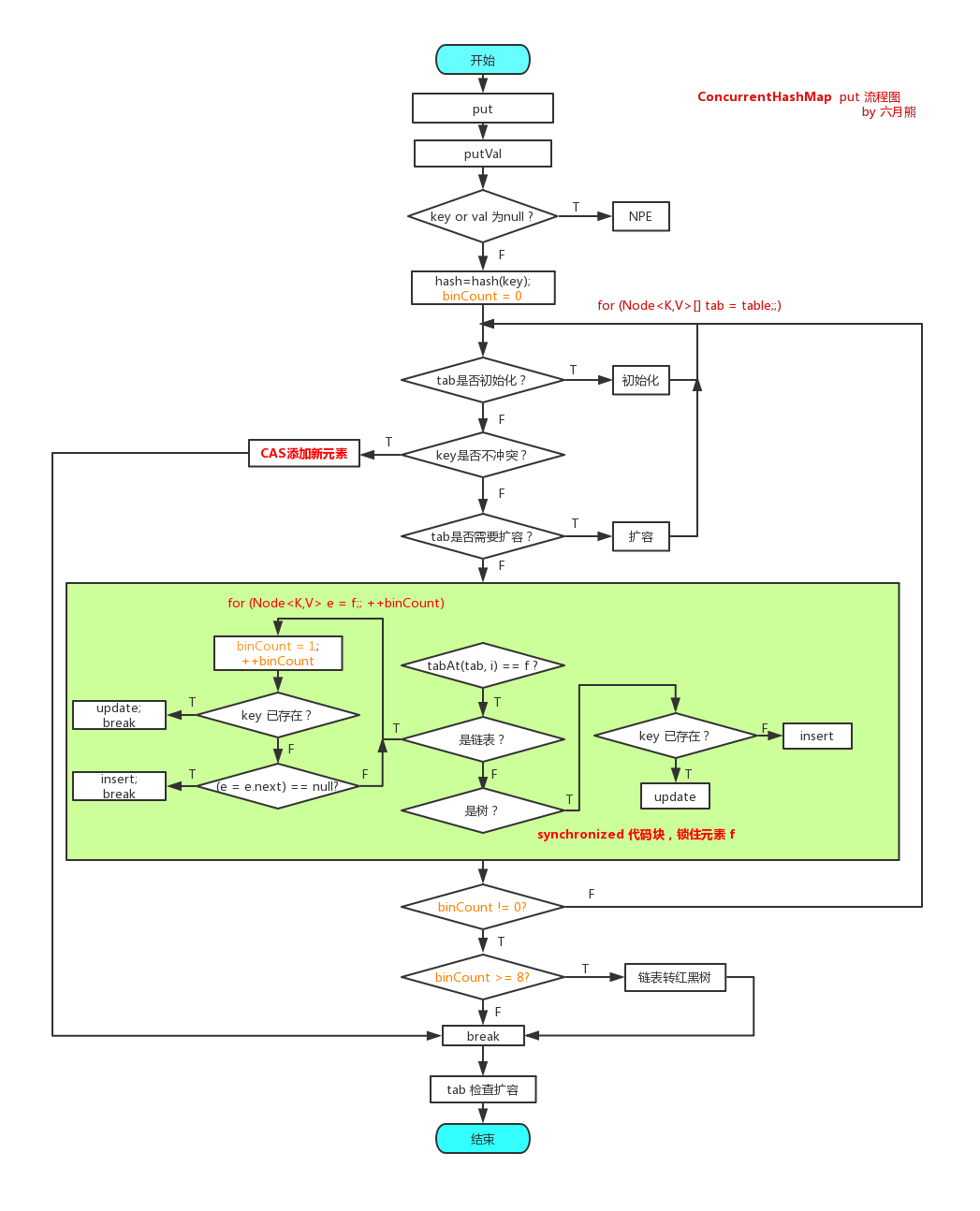
put方法
public V put(K key, V value) {
//实际调用的是putVal(key,value,false)
//无论key在表中所对应的值是否存在,都使用value进行更新
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
//key和value的值必须是非null的
if (key == null || value == null) throw new NullPointerException();
//计算key的hash值用来定位元素的位置
int hash = spread(key.hashCode());
int binCount = 0;
//table 引用指向的是ConcurrentHashMap中 所有元素所存在的数组的引用 所以下面依次将遍历
for (ConcurrentHashMap.Node<K,V>[] tab = table;;) {
ConcurrentHashMap.Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();//table为空,则初始化table,首次初始化默认的数组长度为16
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 判断key对应的数组位置上是否为null,若尚未发生hash碰撞,即进行CAS操作,new 一个 Node<K,V>存放到tab中,退出for循环;
if (casTabAt(tab, i, null,
new ConcurrentHashMap.Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//判断是否需要扩容
else if ((fh = f.hash) == MOVED) // MOVED = -1
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {//加锁
if (tabAt(tab, i) == f) {
if (fh >= 0) {//当作链表处理
binCount = 1;
for (ConcurrentHashMap.Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {// key 存在,更新
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
ConcurrentHashMap.Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new ConcurrentHashMap.Node<K,V>(hash, key,
value, null);//key 不存在,链表中追加新元素
break;
}
}
}
//按照红黑树的方式进行插入
else if (f instanceof ConcurrentHashMap.TreeBin) {
ConcurrentHashMap.Node<K,V> p;
binCount = 2;
//key不存在则putTreeVal方法直接添加新元素并返回null,key存在则返回对应节点p并做val更新
if ((p = ((ConcurrentHashMap.TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//当插入链表后值大于8的时候要转为红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//size++
addCount(1L, binCount);
return null;
}
put方法流程图
1.7和1.8版本都存在的特性
ConcurrentHashMap的key和value都不能为null
键值迭代器为弱一致性迭代器,创建迭代器后,可以对元素进行更新,对元素更新不会影响遍历;
读操作没有加锁,value是voliate修饰的,保证了可见性
读写分离提高效率:多线程对不同的Node/Segment 的插入和删除是可以并发、并行执行的,对同一个Node/Segment的写操作是互斥的。读操作都是无锁的操作,可以并发、并行执行。
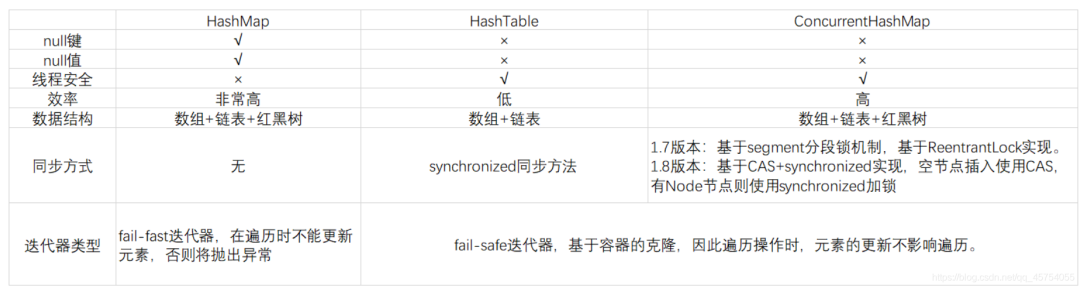
HashMap,HashTable和ConcurrentHashMap的区别:
————————————————
版权声明:本文为CSDN博主「小王~同学」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/qq_45754055/article/details/115592109
粉丝福利:Java从入门到入土学习路线图
👇👇👇

👆长按上方微信二维码 2 秒
感谢点赞支持下哈 