
DropBlock的原理和实现
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
DropBlock是谷歌在2018年提出的一种用于CNN的正则化方法。普通的DropOut只是随机屏蔽掉一部分特征,而DropBlock是随机屏蔽掉一部分连续区域,如下图所示。图像是一个2D结构,像素或者特征点之间在空间上存在依赖关系,这样普通的DropOut在屏蔽语义就不够有效,但是DropBlock这样屏蔽连续区域块就能有效移除某些语义信息比如狗的头,从而起到有效的正则化作用。DropBlock和CutOut有点类似,只不过CutOut是用于图像的一种数据增强方法,而DropBlock是用在CNN的特征上的一种正则化手段。 DropBlock的原理很简单,它和DropOut的最大区别是就是屏蔽的地方是一个连续的方块区域,其伪代码如下所示:
DropBlock的原理很简单,它和DropOut的最大区别是就是屏蔽的地方是一个连续的方块区域,其伪代码如下所示: DropBlock有两个主要参数:block_size和,其中block_size为方块区域的边长,而控制被屏蔽的特征数量大小。对于DropBlock,首先要用参数为的伯努利分布生成一个center mask,这个center mask产生的是要屏蔽的block的中心点,然后将mask中的每个点扩展到block_size大小的方块区域,从而生成最终的block mask。假定输入的特征大小为,那么center mask的大小应该为,而block mask的大小为,在实现上我们可以先对center mask进行padding,然后用一个kernel_size为block_size的max pooling来得到block mask。最后我们将特征乘以block mask即可,不过和DropOut类似,为了保证训练和测试的一致性,还需要对特征进行归一化:乘以count(block mask)/count_ones(block mask)。
DropBlock有两个主要参数:block_size和,其中block_size为方块区域的边长,而控制被屏蔽的特征数量大小。对于DropBlock,首先要用参数为的伯努利分布生成一个center mask,这个center mask产生的是要屏蔽的block的中心点,然后将mask中的每个点扩展到block_size大小的方块区域,从而生成最终的block mask。假定输入的特征大小为,那么center mask的大小应该为,而block mask的大小为,在实现上我们可以先对center mask进行padding,然后用一个kernel_size为block_size的max pooling来得到block mask。最后我们将特征乘以block mask即可,不过和DropOut类似,为了保证训练和测试的一致性,还需要对特征进行归一化:乘以count(block mask)/count_ones(block mask)。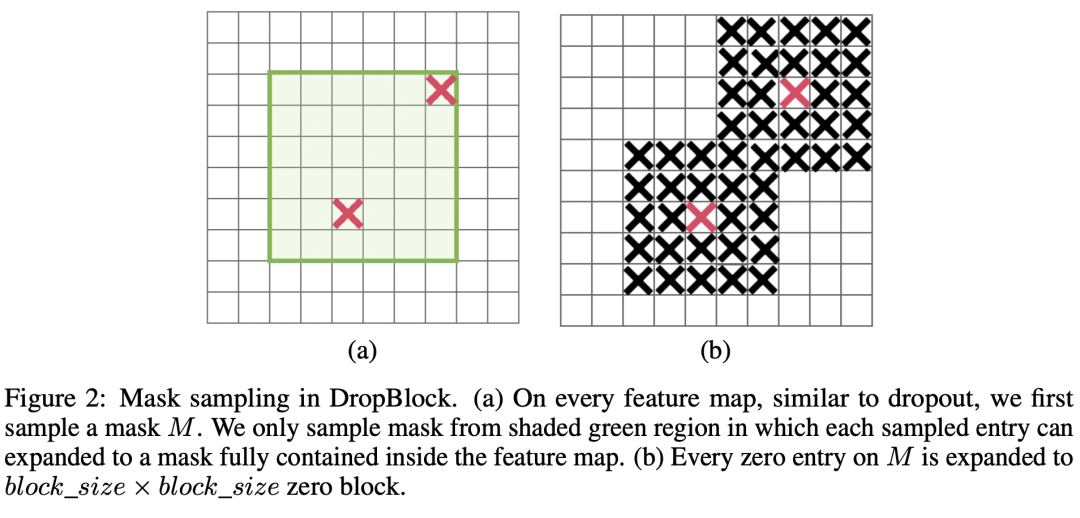 对于DropBlock,我们往往像DropOut那样直接设置一个keep_prob(或者drop_prob),这个概率值控制特征被屏蔽的量。此时我们需要将keep_prob转换为,两个参数带来的效果应该是等价的,所以有:
对于DropBlock,我们往往像DropOut那样直接设置一个keep_prob(或者drop_prob),这个概率值控制特征被屏蔽的量。此时我们需要将keep_prob转换为,两个参数带来的效果应该是等价的,所以有:
这里为特征图大小,那么有了keep_prob就可以计算出:
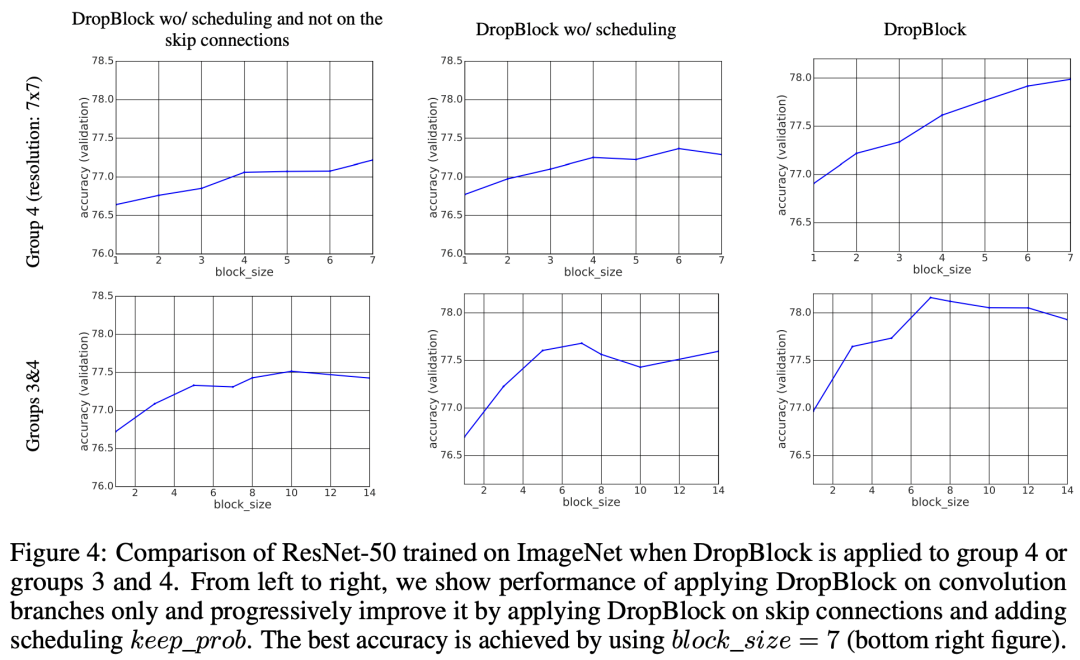
不过这里并没有考虑到两个block可能会发生重叠,所以上述公式只是估算。DropBlock往往采用较大的keep_prob,如下图所示采用0.9的效果是最好的。另外,论文中发现对keep_prob采用一个线性递减的scheduler可以进一步增加效果:keep_prob从1.0线性递减到设定值如0.9。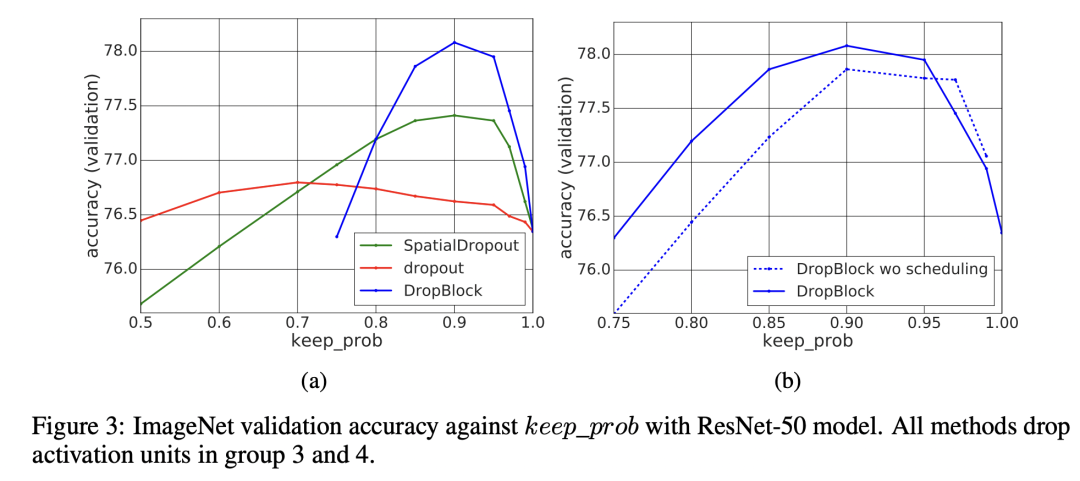 对于block_size,实验发现采用block_size=7效果是最好的,如下所示:
对于block_size,实验发现采用block_size=7效果是最好的,如下所示:
 以ResNet50为例,使用DropBlock后top-1 acc可以从76.5%提升至78.3%,超过其它dropout方法:
以ResNet50为例,使用DropBlock后top-1 acc可以从76.5%提升至78.3%,超过其它dropout方法: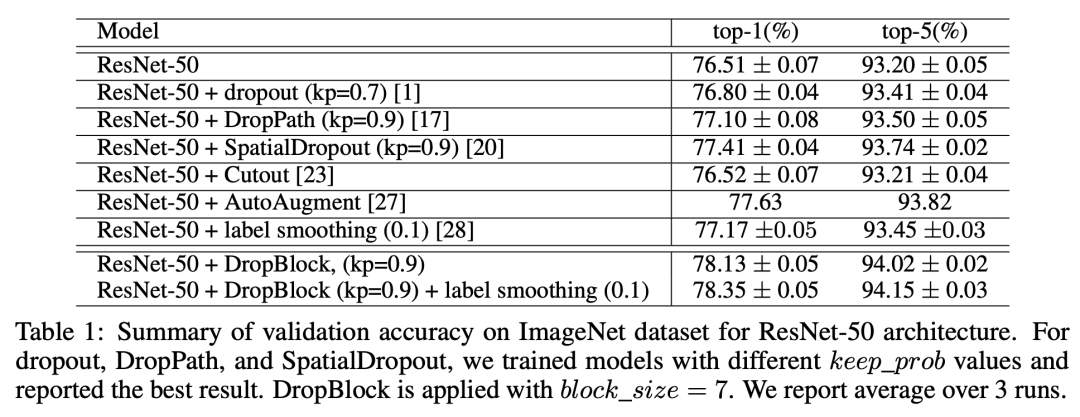 对于DropBlock的使用位置,论文发现对ResNet50来说,用在group3和group4中的卷积层中(即最后两个stage),效果最好。
对于DropBlock的使用位置,论文发现对ResNet50来说,用在group3和group4中的卷积层中(即最后两个stage),效果最好。
下面为DropBlock在PyTorch的具体实现:
class DropBlock2d(nn.Module):
"""
Implements DropBlock2d from `"DropBlock: A regularization method for convolutional networks"
`.
Args:
p (float): Probability of an element to be dropped.
block_size (int): Size of the block to drop.
inplace (bool): If set to ``True``, will do this operation in-place. Default: ``False``
"""
def __init__(self, p: float, block_size: int, inplace: bool = False) -> None:
super().__init__()
if p < 0.0 or p > 1.0:
raise ValueError(f"drop probability has to be between 0 and 1, but got {p}")
self.p = p
self.block_size = block_size
self.inplace = inplace
def forward(self, input: Tensor) -> Tensor:
"""
Args:
input (Tensor): Input feature map on which some areas will be randomly
dropped.
Returns:
Tensor: The tensor after DropBlock layer.
"""
if not self.training:
return input
N, C, H, W = input.size()
# compute the gamma of Bernoulli distribution
gamma = (self.p * H * W) / ((self.block_size ** 2) * ((H - self.block_size + 1) * (W - self.block_size + 1)))
mask_shape = (N, C, H - self.block_size + 1, W - self.block_size + 1)
mask = torch.bernoulli(torch.full(mask_shape, gamma, device=input.device))
mask = F.pad(mask, [self.block_size // 2] * 4, value=0)
mask = F.max_pool2d(mask, stride=(1, 1), kernel_size=(self.block_size, self.block_size), padding=self.block_size // 2)
mask = 1 - mask
normalize_scale = mask.numel() / (1e-6 + mask.sum())
if self.inplace:
input.mul_(mask * normalize_scale)
else:
input = input * mask * normalize_scale
return input
def __repr__(self) -> str:
s = f"{self.__class__.__name__}(p={self.p}, block_size={self.block_size}, inplace={self.inplace})"
return s
参考
DropBlock: A regularization method for convolutional networks https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/plugins/dropblock.py
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
