
经典回顾:ResNet的原理和实现
编辑:张 欢
引言
深度残差网络(Deep residual network, ResNet)的提出是CNN图像史上的一件里程碑事件,让我们先看一下ResNet在ILSVRC和COCO 2015上的战绩:
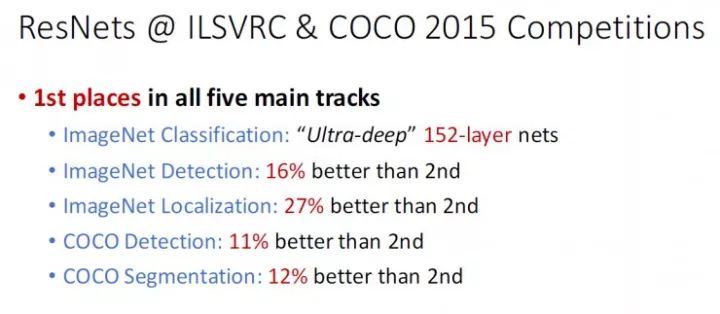
图1 ResNet在ILSVRC和COCO 2015上的战绩
ResNet取得了5项第一,并又一次刷新了CNN模型在ImageNet上的历史:
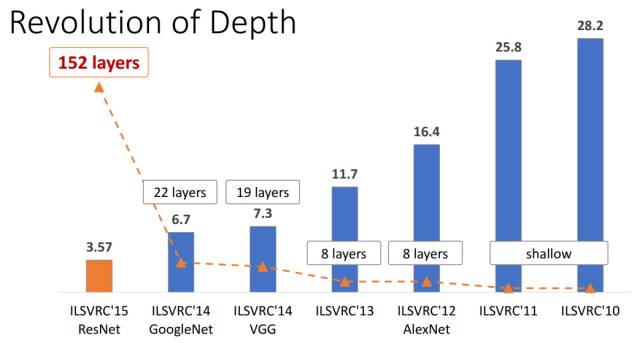
图2 ImageNet分类Top-5误差
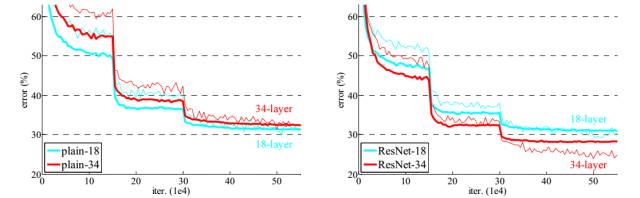
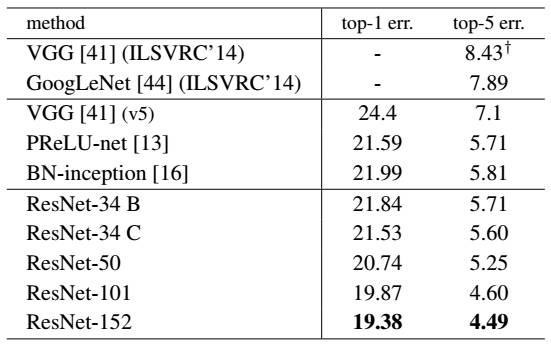
ResNet的作者何凯明(http://kaiminghe.com/)也因此摘得CVPR2016最佳论文奖,当然何博士的成就远不止于此,感兴趣的可以去搜一下他后来的辉煌战绩。那么ResNet为什么会有如此优异的表现呢?其实ResNet是解决了深度CNN模型难训练的问题,从图2中可以看到14年的VGG才19层,而15年的ResNet多达152层,这在网络深度完全不是一个量级上,所以如果是第一眼看这个图的话,肯定会觉得ResNet是靠深度取胜。事实当然是这样,但是ResNet还有架构上的trick,这才使得网络的深度发挥出作用,这个trick就是残差学习(Residual learning)。下面详细讲述ResNet的理论及实现。
从经验来看,网络的深度对模型的性能至关重要,当增加网络层数后,网络可以进行更加复杂的特征模式的提取,所以当模型更深时理论上可以取得更好的结果,从图2中也可以看出网络越深而效果越好的一个实践证据。但是更深的网络其性能一定会更好吗?实验发现深度网络出现了退化问题(Degradation problem):网络深度增加时,网络准确度出现饱和,甚至出现下降。这个现象可以在图3中直观看出来:56层的网络比20层网络效果还要差。这不会是过拟合问题,因为56层网络的训练误差同样高。我们知道深层网络存在着梯度消失或者爆炸的问题,这使得深度学习模型很难训练。但是现在已经存在一些技术手段如BatchNorm来缓解这个问题。因此,出现深度网络的退化问题是非常令人诧异的。
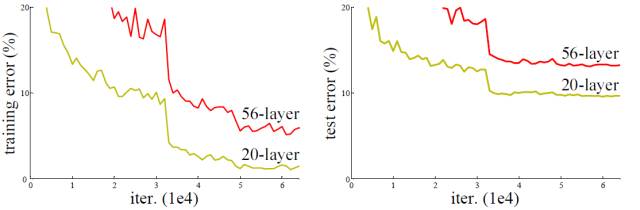
图3 20层与56层网络在CIFAR-10上的误差
深度网络的退化问题至少说明深度网络不容易训练。但是我们考虑这样一个事实:现在你有一个浅层网络,你想通过向上堆积新层来建立深层网络,一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即这样新层是恒等映射(Identity mapping)。在这种情况下,深层网络应该至少和浅层网络性能一样,也不应该出现退化现象。好吧,你不得不承认肯定是目前的训练方法有问题,才使得深层网络很难去找到一个好的参数。
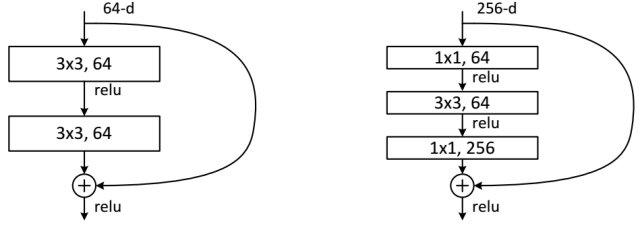
这个有趣的假设让何博士灵感爆发,他提出了残差学习来解决退化问题。对于一个堆积层结构(几层堆积而成)当输入为时其学习到的特征记为,现在我们希望其可以学习到残差,这样其实原始的学习特征是。之所以这样是因为残差学习相比原始特征直接学习更容易。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。残差学习的结构如图4所示。这有点类似与电路中的“短路”,所以是一种短路连接(shortcutconnection)。
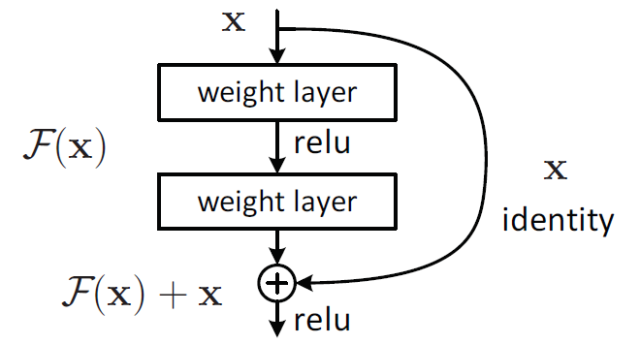
图4 残差学习单元
为什么残差学习相对更容易,从直观上看残差学习需要学习的内容少,因为残差一般会比较小,学习难度小点。不过我们可以从数学的角度来分析这个问题,首先残差单元可以表示为:
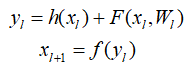
其中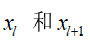 分别表示的是第
分别表示的是第个残差单元的输入和输出,注意每个残差单元一般包含多层结构。
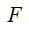 是残差函数,表示学习到的残差,而
是残差函数,表示学习到的残差,而 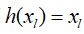 表示恒等映射,
表示恒等映射, 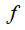 是ReLU激活函数。基于上式,我们求得从浅层
是ReLU激活函数。基于上式,我们求得从浅层 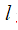 到深层
到深层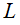 的学习特征
的学习特征
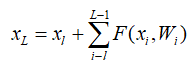
利用链式规则,可以求得反向过程的梯度:
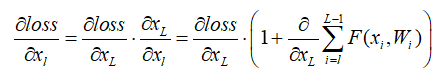
式子的第一个因子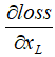 表示的损失函数到达的梯度,小括号中的1表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。所以残差学习会更容易。要注意上面的推导并不是严格的证明。
表示的损失函数到达的梯度,小括号中的1表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。所以残差学习会更容易。要注意上面的推导并不是严格的证明。

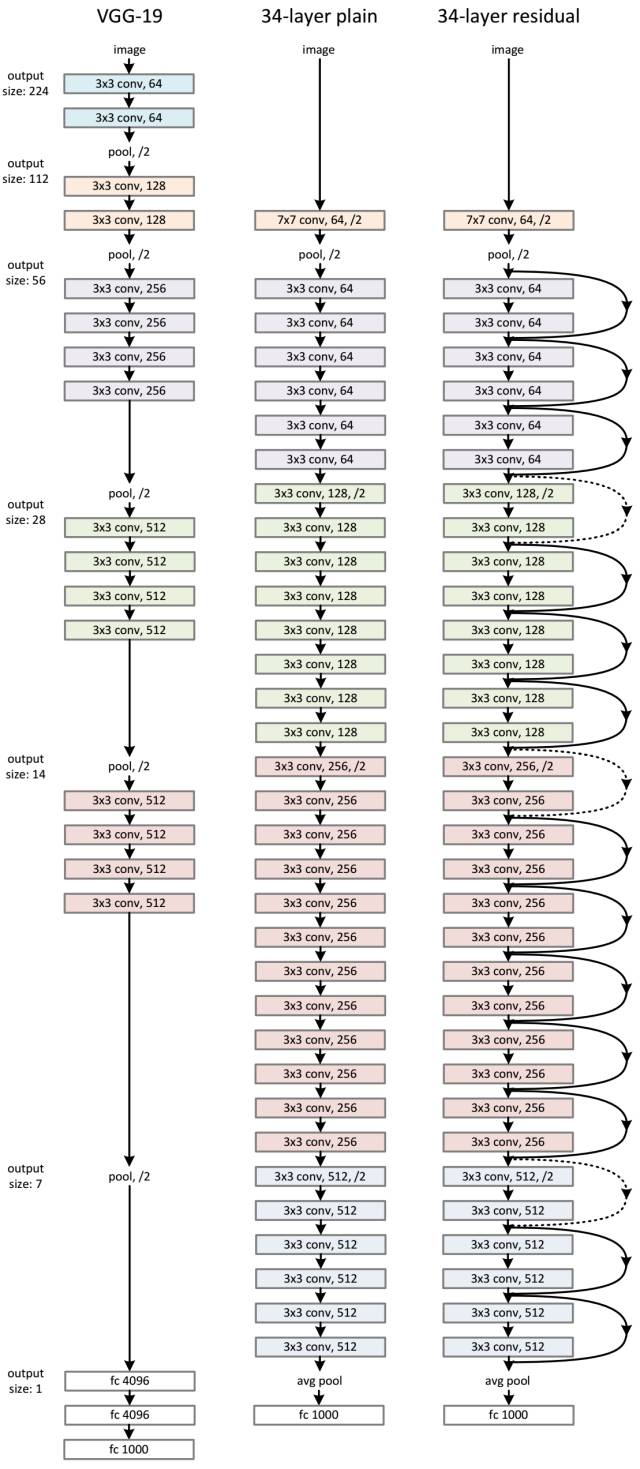
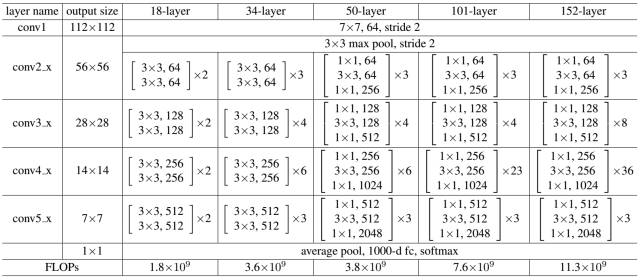
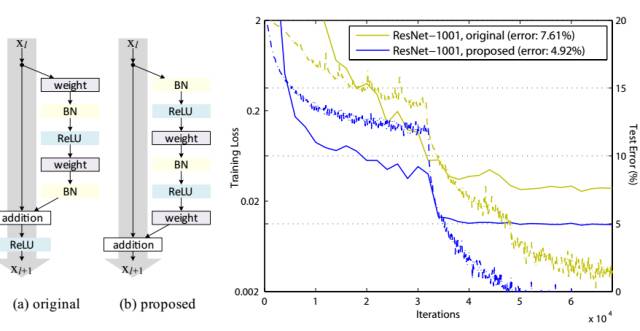
ResNet通过残差学习解决了深度网络的退化问题,让我们可以训练出更深的网络,这称得上是深度网络的一个历史大突破吧。也许不久会有更好的方式来训练更深的网络,让我们一起期待吧!
参考资料
1. Deep ResidualLearning for Image Recognition: https://arxiv.org/abs/1512.03385.
2. Identity Mappings in Deep Residual Networks: https://arxiv.org/abs/1603.05027.
3. 去膜拜一下大神: http://kaiminghe.com/.
3.RNN入门与实践
机器学习算法全栈工程师
一个用心的公众号

进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助

公众号商务合作请联系 ▶▶▶