
【收藏】BPF 技术介绍及学习路线分享

来自【分布式实验室】

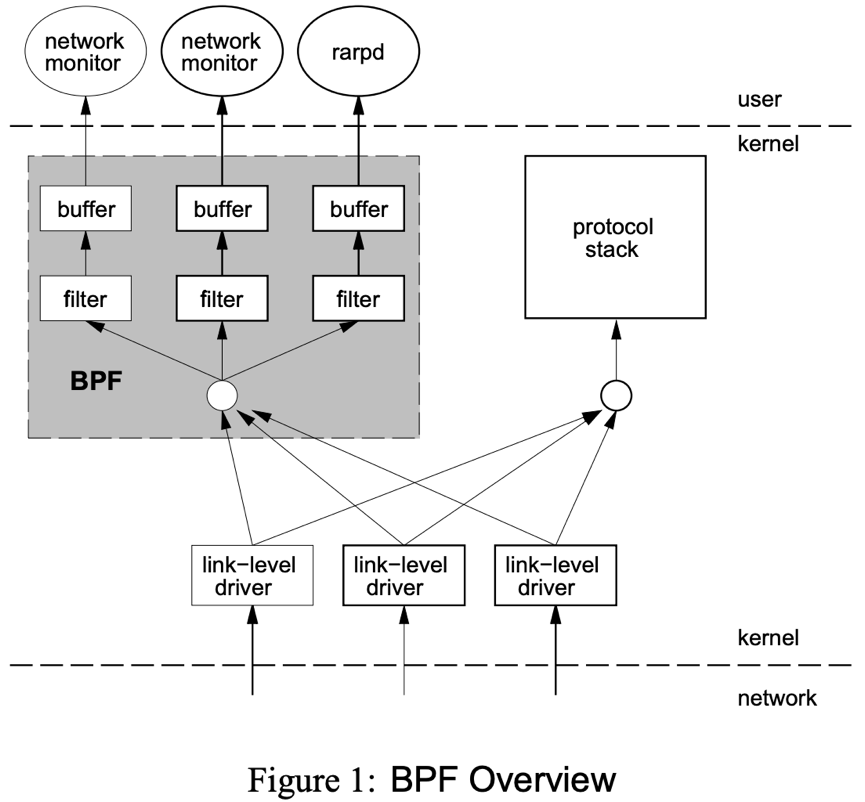
一个新的虚拟机(VM)设计,可以有效地工作在基于寄存器结构的CPU之上;
应用程序使用缓存只复制与过滤数据包相关的数据,不会复制数据包的所有信息,最大程度地减少BPF 处理的数据,提高处理效率。
强安全,即不能允许不可信的代码运行在内核中,这是头等重要的事情
高性能,作为承载千百万服务的操作系统内核,如果没有高性能的保障,互联网蓬勃发展将收到严重影响
持续交付,在越来越多应用进入到云原生时代的今天,持续交付这个命题,一点都不陌生,而在内核开发领域,这点也至关重要,每次功能的升级,都需要你重新安装新的系统,大多数人都不会买账。我们希望做到跟Chrome浏览器升级一样,用户都不会注意到升级完成了(除非有一些视觉上的变化),实现真正的无缝升级。
直接修改内核代码进行开发,通过API暴露能力,可能要等上n年用户才能更新到这个版本来使用,而且每次的功能更新都可能需要重新编译打包内核代码。
开发新的可即时加载的内核模块,用户可以在运行时加载到Linux内核中,从而实现扩展内核功能的目的。然而每次内核版本的官方更新,可能会引起内核API的变化,因此你编写的内核模块可能会随着每一个内核版本的发布而不可用,这样就必须得为每次的内核版本更新调整你的模块代码,你得非常小心,不然就会让内核直接崩溃。
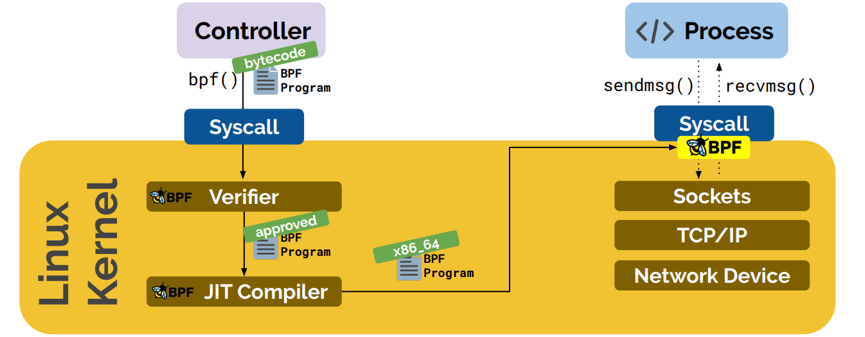
强安全:BPF验证器(verifier)会保证每个程序能够安全运行,它会去检查将要运行到内核空间的程序的每一行是否安全可靠,如果检查不通过,它将拒绝这个程序被加载到内核中去,从而保证内核本身不会崩溃,这是不同于开发内核模块的。比如以下几种情况是无法通过的BPF验证器的:
BPF验证机制很像Chrome浏览器对于JavaScript脚本的沙盒机制。
没有实际加载BPF程序所需的权限
访问任意内核空间的内存数据
将任意内核空间的内存数据暴露给用户空间
高性能:一旦通过了BPF验证器,那么它就会进入JIT编译阶段,利用Just-In-Time编译器,编译生成的是通用的字节码,它是完全可移植的,可以在x86和ARM等任意球CPU架构上加载这个字节码,这样我们能获得本地编译后的程序运行速度,而且是安全可靠的。
持续交付:通过JIT编译后,就会把编译后的程序附加到内核中各种系统调用的钩子(hook)上,而且可以在不影响系统运行的情况下,实时在线地替换这些运行在Linux内核中的BPF程序。举个例子,拿一个处理网络数据包的应用程序来说,在每秒都要处理几十万个数据包的情况下,在一个数据包和下一个数据包之间,加载到网络系统调用hook上的BPF程序是可以自动替换的,可以预见到的结果是,上一个数据包是旧版本的程序在处理,而下一个数据包就会看到新版本的程序了,没有任何的中断。这就是无缝升级,从而实现持续交付的能力。
kernel functions(kprobes)
userspace functions(uprobes)
system calls
fentry/fexit
Tracepoints
network devices(tc/xdp)
network routes
TCP congestion algorithms
sockets(data level)
Hash tables,Arrays
LRU(Least Recently Used)
Ring Buffer
Stack Trace
LPM(Longest Prefix match)

BPF Map是可以被用户空间访问并操作的
BPF Map是可以与BPF程序分离的,即当创建一个BPF Map的BPF程序运行结束后,该BPF Map还能存在,而不是随着程序一起消亡


eBPF程序不能调用任意的内核参数,只限于内核模块中列出的BPF Helper函数,函数支持列表也随着内核的演进在不断增加
eBPF程序不允许包含无法到达的指令,防止加载无效代码,延迟程序的终止
eBPF程序中循环次数限制且必须在有限时间内结束
eBPF堆栈大小被限制在MAX_BPF_STACK,截止到内核Linux 5.8版本,被设置为512。目前没有计划增加这个限制,解决方法是改用BPF Map,它的大小是无限的。
eBPF字节码大小最初被限制为4096条指令,截止到内核Linux 5.8版本, 当前已将放宽至100万指令(BPF_COMPLEXITY_LIMIT_INSNS),对于无权限的BPF程序,仍然保留4096条限制(BPF_MAXINSNS)
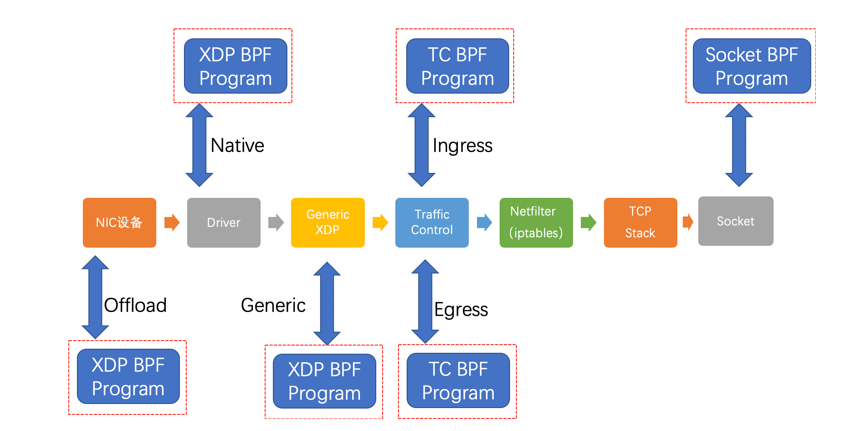
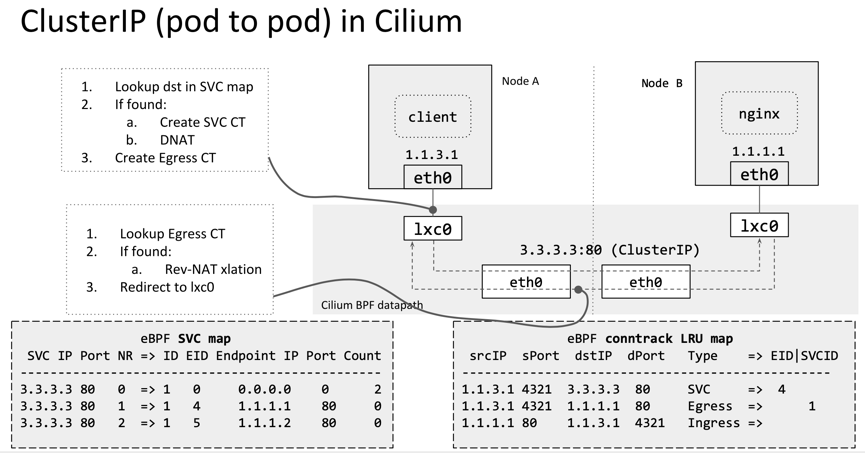

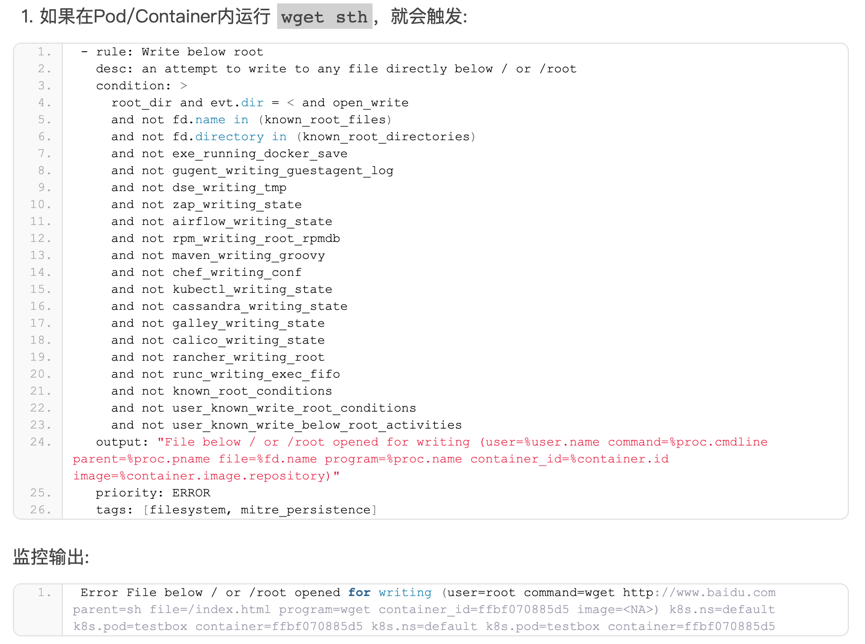
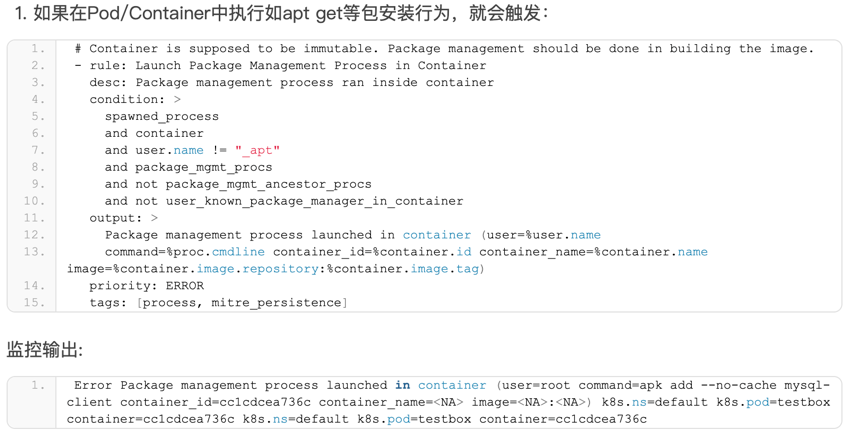

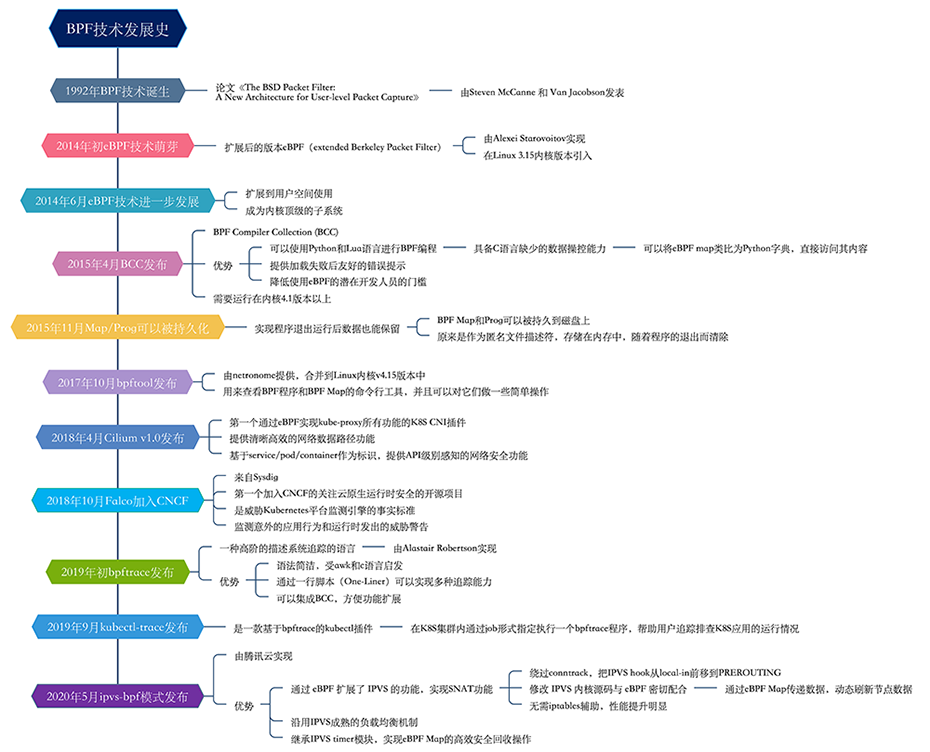
https://ebpf.io,最全BPF学习资源网站,主要由Cilium团队维护,上面会及时更新BPF技术的文档和视频。
https://lwn.net/Kernel/Index/#Berkeley_Packet_Filter,LWN是学习Linux内核技术的最好的网站,这个BPF分类文章集合,记录了很多BPF里程碑事件的前前后后,既学会了知识,又明白了背景。
https://cilium.readthedocs.io/en/stable/bpf/,Cilium提供的BPF文档,是我看到过的最具实战价值的BPF手册,值得好好阅读。
https://www.kernel.org/doc/html/latest/bpf/bpf_devel_QA.html,开发BPF必读Q&A,里面是维护BPF内核代码的大佬给出的代码开发建议,读了能明白社区是如何运作BPF的。
https://git.kernel.org/pub/scm/linux/kernel/git/bpf/bpf.git/,这个repo是Linux社区官方维护的独立BPF代码仓库,一旦发布新版本后,代码就不会大改,只接受bug fix,相当于master repo,最终会merge到Linux内核代码主干中。
https://git.kernel.org/pub/scm/linux/kernel/git/bpf/bpf-next.git/,这个repo也是Linux社区官方维护的BPF代码仓库,更新频繁,用于引入新功能或现有功能优化,稳定后merge到上面的master repo,相当于feature repo。
https://cilium.slack.com/archives/C4XCTGYEM,为Cilium提供的关于eBPF的thread,有什么疑问都可以去问
https://github.com/DavadDi/bpf_study,狄卫华老师的收集的BPF文章和教程,有问题可以去提issue
https://github.com/nevermosby/linux-bpf-learning,本人编写的BPF教程,欢迎来提issue和PR
Brendan Gregg,来自Netflix最强BPF布道师,他的博客都是关于Linux系统优化的,观点独到,每一篇都值得一读;
Alexei Starovoitov,eBPF创造者,目前在Facebook就职,经常能在内核代码commit中看到他的踪迹;
Daniel Borkmann,eBPF kernel co-maintainer,目前在Cilium所在的公司Isovalent就职,是给eBPF增加feature的能力者;
Thomas Graf,Cilium之父,Isovalent的CTO,他也是eBPF和Cilium的强力布道师,能说会道,各种大会上都有他的风采;
Quentin Monnet,BPFTool co-maintainer,Quentin是在stackoverflow上bpf问题的killer,Twitter有关于eBPF的系列实战短文,值得细品。
《Linux Observability with BPF》,作者David Calavera和Lorenzo Fontana, 这本书篇幅不长,是来自sysdig的两位大佬写的BPF手册书,推荐入门阅读
《Linux内核观测技术BPF》,是最近刚出版的第一本BPF中文书籍,为上面英文书的翻译版本,由范彬和狄卫华两位翻译
《BPF Performance Tools》,这是Brendan Gregg大神对于BPF技术如何做系统性能优化的一本集大成者的秘籍,BPF学习者必备。
《Systems Performance: Enterprise and the Cloud, 2nd Edition》,这是Brendan Gregg大神系统优化书籍的第二版,篇幅较长,但是值得一啃。
绕过conntrack,使用eBPF增强 IPVS优化k8s网络性能:https://v.qq.com/x/page/s3137ehoq8i.html
深入了解服务网格数据平面性能和调优:https://v.qq.com/x/page/v3137ax6zss.html
Kubernetes中用于混沌与跟踪的BPF:https://v.qq.com/x/page/f3130lpe0iv.html
https://kccnceu20.sched.com/event/ZejN/tutorial-using-bpf-in-cloud-native-environments-alban-crequy-marga-manterola-kinvolk
https://kccnceu20.sched.com/event/Zeoz/hubble-ebpf-based-observability-for-kubernetes-sebastian-wicki-isovalent
https://kccnceu20.sched.com/event/Zexb/designing-a-grpc-interface-for-kernel-tracing-with-ebpf-leonardo-di-donato-sysdig
https://kccnceu20.sched.com/event/ZemQ/ebpf-and-kubernetes-little-helper-minions-for-scaling-microservices-daniel-borkmann-cilium
https://kccnceu20.sched.com/event/Zewd/intro-to-falco-intrusion-detection-for-containers-shane-lawrence-shopify
https://kccnceu20.sched.com/event/ZetL/seccomp-security-profiles-and-you-a-practical-guide-duffie-cooley-vmware
https://kccnceu20.sched.com/event/ZeqL/k8s-in-the-datacenter-integrating-with-preexisting-bare-metal-environments-max-stritzinger-bloomberg
Tcpdump
BCC,BPFTrace,kubectl-trace from IOVisor
Cilium from Isovalent
Falco from Sysdig
Katran from Facebook
Bottlerocket from Amazon
腾讯云IPVS-BPF K8S网络优化方案
Kernel Chaos With BPF by PingCAP
网易轻舟做系统检测和网络优化
字节跳动做高性能网络ACL管理

r0保存了调用一次辅助函数后的返回值
r1 – r5 保存了从BPF程序到辅助函数的参数列表
r6 – r9 是用来保存中间值的寄存器,它可以被多个辅助函数调用
r10 是唯一的只读寄存器,包含访问BPF stack的指针
在线阅读Linux内核代码的好去处:https://elixir.bootlin.com/linux/v5.8.7/source
快速定位函数的定义和引用
下载Linux内核代码,编译运行BPF示例程序
参见博文: https://davidlovezoe.club/compile-bpf-examples
根据示例程序,写自己的BPF程序,并跑起来
能够静下心来看Linux内核代码,这件事听起来简单,做起来不易,因为有了学习兴趣有学习目标,我开始习惯于阅读那些看起来冗长晦涩的代码
理解Linux系统调用、文件系统等功能模块的工作原理,正式由于能静下心来读代码,所以那些原本认为这辈子都看不懂的东西,竟然慢慢变得清晰起来
写文章可以锻炼很多其他软技能,比如画图,录视频,做视频等等,写技术博客就是这么一件痛并快乐着的事情
有收获,点个在看
