
收藏:FPGA知识及芯片技术


前段时间,笔者分享了“中国FPGA芯片行业研究报告(上篇)”,今天继续聊聊FPGA技术话题。
FPGA可用于处理多元计算密集型任务,依托流水线并行结构体系,FPGA相对GPU、CPU在计算结果返回时延方面具备技术优势。
计算密集型任务:矩阵运算、机器视觉、图像处理、搜索引擎排序、非对称加密等类型的运算属于计算密集型任务。该类运算任务可由CPU卸载至FPGA执行。
FPGA执行计算密集型任务性能表现:
• 计算性能相对CPU:如Stratix系列FPGA进行整数乘法运算,其性能与20核CPU相当,进行浮点乘法运算,其性能与8核CPU相当。
• 计算性能相对GPU:FPGA进行整数乘法、浮点乘法运算,性能相对GPU存在数量级差距,可通过配置乘法器、浮点运算部件接近GPU计算性能。
FPGA执行计算密集型任务核心优势:搜索引擎排序、图像处理等任务对结果返回时限要求较为严格,需降低计算步骤时延。传统GPU加速方案下数据包规模较大,时延可达毫秒级别。FPGA加速方案下,PCIe时延可降至微秒级别。远期技术推动下,CPU与FPGA数据传输时延可降至100纳秒以下。
FPGA可针对数据包步骤数量搭建同等数量流水线(流水线并行结构),数据包经多个流水线处理后可即时输出。GPU数据并行模式依托不同数据单元处理不同数据包,数据单元需一致输入、输出。针对流式计算任务,FPGA流水线并行结构在延迟方面具备天然优势。
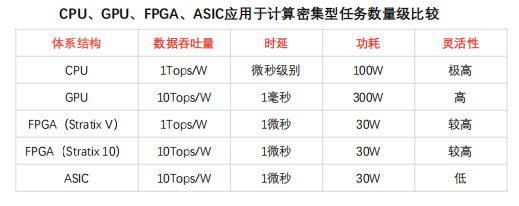
FPGA用于处理通信密集型任务不受网卡限制,在数据包吞吐量、时延方面表现优于CPU方案,时延稳定性较强。
通信密集型任务:对称加密、防火墙、网络虚拟化等运算属于通信密集型计算任务,通信密集数据处理相对计算密集数据处理复杂度较低,易受通信硬件设备限制。
FPGA执行通信密集型任务优势:
① 吞吐量优势:CPU方案处理通信密集任务需通过网卡接收数据,易受网卡性能限制(线速处理64字节数据包网卡有限,CPU及主板PCIe网卡插槽数量有限)。GPU方案(高计算性能)处理通信密集任务数据包缺乏网口,需依靠网卡收集数据包,数据吞吐量受CPU及网卡限制,时延较长。FPGA可接入40Gbps、100Gbps网线,并以线速处理各类数据包,可降低网卡、交换机配置成本。
② 时延优势:CPU方案通过网卡收集数据包,并将计算结果发送至网卡。受网卡性能限制,DPDK数据包处理框架下,CPU处理通信密集任务时延近5微秒,且CPU时延稳定性较弱,高负载情况下时延或超过几十微秒,造成任务调度不确定性。FPGA无需指令,可保证稳定、极低时延,FPGA协同CPU异构模式可拓展FPGA方案在复杂端设备的应用。
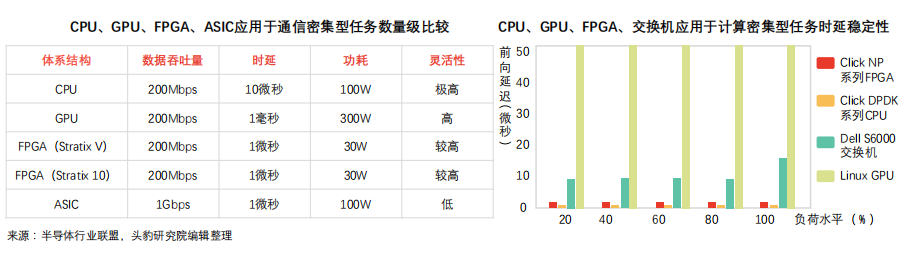
FPGA部署包括集群式、分布式等,逐渐从中心化过渡至分布式,不同部署方式下,服务器沟通效率、故障传导效应表现各异。
FPGA嵌入功耗负担:FPGA嵌入对服务器整体功耗影响较小,以Catapult联手微软开展的FPGA加速机器翻译项目为例,加速模块整体总计算能力达到103Tops/W,与10万块GPU计算能力相当。相对而言,嵌入单块FPGA导致服务器整体功耗增加约30W。
FPGA部署方式特点及限制:
① 集群部署特点及限制:FPGA芯片构成专用集群,形成FPGA加速卡构成的超级计算器(如Virtex系列早期实验板于同一硅片部署6块FPGA,单位服务器搭载4块实验板)。
• 专用集群模式无法在不同机器FPGA之间实现通信;
• 数据中心其他机器需集中发送任务至FPGA集群,易造成网络延迟;
• 单点故障导致数据中心整体加速能力受限
② 网线连接分布部署:为保证数据中心服务器同构性(ASIC解决方案亦无法满足),该部署方案于不同服务器嵌入FPGA,并通过专用网络连接,可解决单点故障传导、网络延迟等问题。
• 类同于集群部署模式,该模式不支持不同机器FPGA间通信;
• 搭载FPGA芯片的服务器具备高度定制化特点,运维成本较高
③ 共享服务器网络部署:该部署模式下,FPGA置于网卡、交换机间,可大幅提高加速网络功能并实现存储虚拟化。FPGA针对每台虚拟机设置虚拟网卡,虚拟交换机数据平面功能移动至FPGA内,无需CPU或物理网卡参与网络数据包收发过程。该方案显著提升虚拟机网络性能(25Gbps),同时可降低数据传输网络延迟(10倍)。
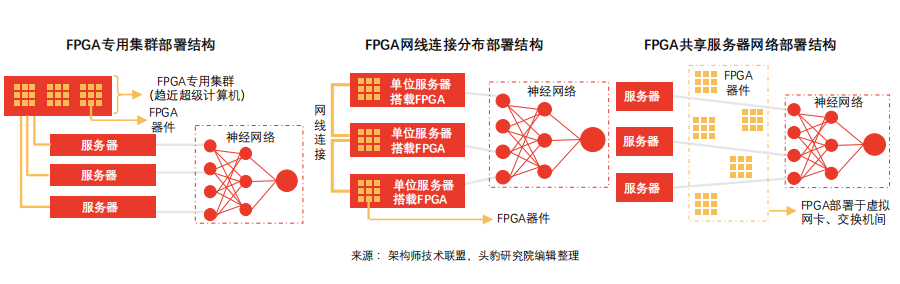
分享服务器网络部署模式下,FPGA加速器有助于降低数据传输时延,维护数据中心时延稳定,显著提升虚拟机网络性能。
分享服务器网络部署模式下FPGA加速Bing搜索排序:Bing搜索排序于该模式下采用10Gbps专用网线通信,每组网络由8个FPGA组成。其中,部分负责提取信号特征,部分负责计算特征表达式,部分负责计算文档得分,最终形成机器人即服务(RaaS)平台。FPGA加速方案下,Bing搜索时延大幅降低,延迟稳定性呈现正态分布。该部署模式下,远程FPGA通信延迟相对搜索延迟可忽略。
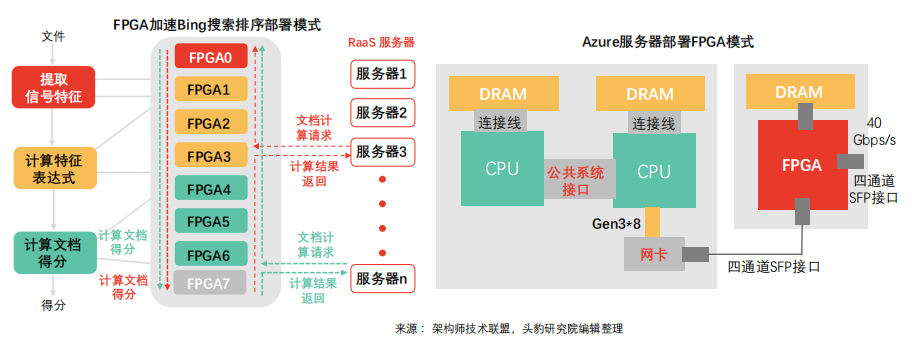
Azure服务器部署FPGA模式:Azure针对网络及存储虚拟化成本较高等问题采取FPGA分享服务器网络部署模式。随网络计算速度达到40Gbps,网络及存储虚拟化CPU成本激增(单位CPU核仅可处理100Mbps吞吐量)。通过在网卡及交换机间部署FPGA,网络连接扩展至整个数据中心。通过轻量级传输层,同一服务器机架时延可控制在3微秒内,触达同数据中心全部FPGA机架时延可控制在20微秒内。
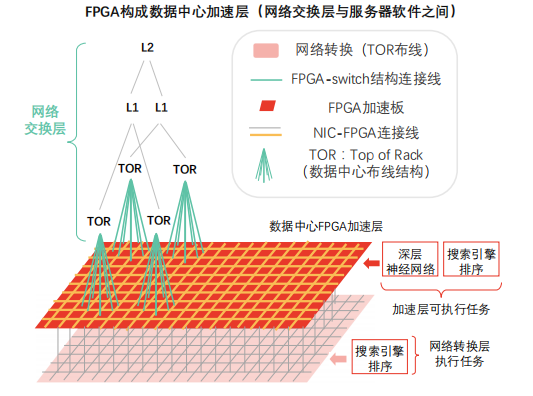
依托高带宽、低时延优势,FPGA可组成网络交换层与服务器软件之间的数据中心加速层,并随分布式加速器规模扩大实现性能超线性提升。
数据中心加速层:FPGA嵌入数据中心加速平面,位于网络交换层(支架层、第一层、第二层)及传统服务器软件(CPU层面运行软件)之间。
加速层优势:
• FPGA加速层负责为每台服务器(提供云服务)提供网络加速、存储虚拟化加速支撑,加速层剩余资源可用于深度神经网络(DNN)等计算任务。
• 随分布式网络模式下FPGA加速器规模扩大,虚拟网络性能提升呈现超线性特征。
加速层性能提升原理:使用单块FPGA时,单片硅片内存不足以支撑全模型计算任务,需持续访问DRAM以获取权重,受制于DRAM性能。加速层通过数量众多的FPGA支撑虚拟网络模型单层或单层部分计算任务。该模式下,硅片内存完整加载模型权重,可突破DRAM性能瓶颈,FPGA计算性能得到充分发挥。加速层需避免计算任务过度拆分而导致计算、通信失衡。
嵌入式eFPGA技术在性能、成本、功耗、盈利能力等方面优于传统FPGA嵌入方案,可针对不同应用场景、不同细分市场需求提供灵活解决方案.
eFPGA技术驱动因素:设计复杂度提升伴随设备成本下降的经济趋势促发市场对eFPGA技术需求。
器件设计复杂度提升:SoC设计实现过程相关软件工具趋于复杂(如Imagination Technologies为满足客户完整开发解决方案需求而提供PowerVR图形界面、Eclipse整合开发环境),工程耗时增加(编译时间、综合时间、映射时间,FPGA规模越大,编译时间越长)、制模成本提高(FPGA芯片成本为同规格ASIC芯片成本100倍)。
设备单位功能成本持续下降:20世纪末期,FPGA平均售价较高(超1,000元),传统模式下,FPGA与ASIC集成设计导致ASIC芯片管芯面积、尺寸增大,复杂度提升,早期混合设备成本较高。21世纪,相对批量生产的混合设备,FPGA更多应用于原型设计、预生产设计,成本相对传统集成持续下降(最低约100元),应用灵活。eFPGA技术优势:
更优质:eFPGA IP核及其他功能模块的SoC设计相对传统FPGA嵌入ASIC解决方案,在功耗、性能、体积、成本等方面表现更优。
更方便:下游应用市场需求更迭速度快,eFPGA可重新编程特性有助于设计工程师更新SoC,产品可更长久占有市场,利润、收入、盈利能力同时大幅提升。eFPGA方案下SoC可实现高效运行,一方面迅速更新升级以支持新接口标准,另一方面可快速接入新功能以应对细分化市场需求。
更节能:SoC设计嵌入eFPGA技术可在提高总性能的同时降低总功耗。利用eFPGA技术可重新编程特性,工程师可基于硬件,针对特定问题对解决方案进行重新配置,进而提高设计性能、降低功耗。

FPGA技术无需依靠指令、无需共享内存,在云计算网络互连系统中提供低延迟流式通信功能,可广泛满足虚拟机之间、进程之间加速需求.
FPGA云计算任务执行流程:主流数据中心以FPGA为计算密集型任务加速卡,赛灵思及阿尔特拉推出基于OpenCL的高层次编程模型,模型依托CPU触达DRAM,向FPGA传输任务,通知执行,FPGA完成计算并将执行结果传输至DRAM,最终传输至CPU。
FPGA云计算性能升级空间:受限于工程实现能力,当前数据中心FPGA与CPU之间通信多以DRAM为中介,通过烧写DRAM、启动kernel、读取DRAM的流程完成通信(FPGADRAM相对CPU DRAM数据传输速度较慢),时延近2毫秒(OpenCL、多个kernel间共享内存)。CPU与FPGA间通信时延存在升级空间,可借助PCIe DMA实现高效直接通信,时延最低可降至1微秒。
FPGA云计算通信调度新型模式:新通信模式下,FPGA与CPU无需依托共享内存结构,可通过管道实现智行单元、主机软件之间的高速通信。云计算数据中心任务较为单一,重复性强,主要包括虚拟平台网络构建和存储(通信任务)以及机器学习、对称及非对称加密解密(计算任务),算法较为复杂。新型调度模式下,CPU计算任务趋于碎片化,远期云平台计算中心或以FPGA为主,并通过FPGA将复杂计算任务卸载至CPU(区别于传统模式下CPU卸载任务至FPGA的模式)。

全球FPGA市场由四大巨头Xilinx赛灵思,Intel英特尔(收购阿尔特拉)、Lattice莱迪思、Microsemi美高森美垄断,四大厂商垄断9,000余项专利技术,把握行业“制空权”。
FPGA芯片行业形成以来,全球范围约有超70家企业参与竞争,新创企业层出不穷(如Achronix Semiconductor、MathStar等)。产品创新为行业发展提供动能,除传统可编程逻辑装置(纯数字逻辑性质),新型可编程逻辑装置(混讯性质、模拟性质)创新速度加快,具体如Cypress Semiconductor 研 发 具 有 可 组 态 性 混 讯 电 路 PSoC(Programmable System on Chip),再如Actel推出Fusion(可程序化混讯芯片)。此外,部分新创企业推出现场可编程模拟数组FPAA(Field Programmable Analog Array)等。
随智能化市场需求变化演进,高度定制化芯片(SoC ASIC)因非重复投资规模大、研发周期长等特点导致市场风险剧增。相对而言,FPGA在并行计算任务领域具备优势,在高性能、多通道领域可以代替部分ASIC。人工智能领域多通道计算任务需求推动FPGA技术向主流演进。
基于FPGA芯片在批量较小(流片5万片为界限)、多通道计算专用设备(雷达、航天设备)领域的优势,下游部分应用市场以FPGA取代ASIC应用方案。
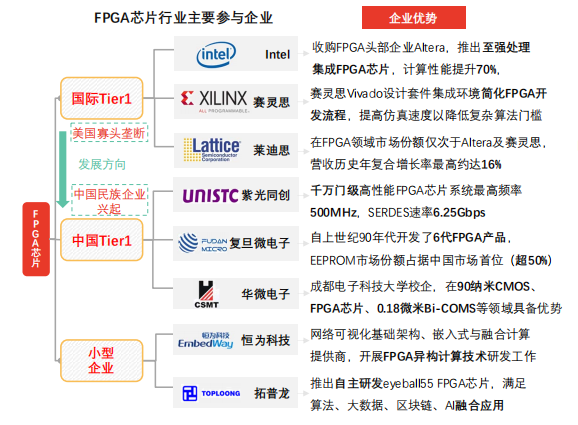
中国FPGA芯片研发企业可以紫光同创、国微电子、成都华微电子、安路科技、智多晶、高云半导体、上海复旦微电子和京微齐力为例。从产品角度分析,中国FPGA硬件性能指标相较赛灵思、Intel等差距较大。紫光同创是当前中国市场唯一具备自主产权千万门级高性能FPGA研发制造能力的企业。上海复旦微电子于2018年5月推出自主知识产权亿门级FPGA产品。中国FPGA企业紧跟大厂步伐,布局人工智能、自动驾驶等市场,打造高、中、低端完整产品线。
中国FPGA企业竞争突破口现阶段中国FPGA厂商芯片设计软件、应用软件不统一,易在客户端造成资源浪费,头部厂商可带头集中产业链资源,提高行业整体竞争力。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕,知识点深度讲解,提供182页完整版下载。
获取方式:点击“阅读原文”即可查看PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。

转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(37本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“全店铺技术资料打包(全)”,后续可享全店内容更新“免费”赠阅,价格仅收198元(原总价350元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。