
简单回答:SparkSQL数据抽象和SparkSQL底层执行过程
SparkSQL数据抽象
引入DataFrame
就易用性而言,对比传统的MapReduce API,Spark的RDD API有了数量级的飞跃并不为过。然而,对于没有MapReduce和函数式编程经验的新手来说,RDD API仍然存在着一定的门槛。
另一方面,数据科学家们所熟悉的R、Pandas等传统数据框架虽然提供了直观的API,却局限于单机处理,无法胜任大数据场景。
为了解决这一矛盾,Spark SQL 1.3.0在原有SchemaRDD的基础上提供了与R和Pandas风格类似的DataFrame API。
新的DataFrame AP不仅可以大幅度降低普通开发者的学习门槛,同时还支持Scala、Java与Python三种语言。更重要的是,由于脱胎自SchemaRDD,DataFrame天然适用于分布式大数据场景。
注意:
DataFrame它不是Spark SQL提出来的,而是早期在R、Pandas语言就已经有了的。
DataFrame是什么
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。

使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行针对性的优化,最终达到大幅提升运行时效率。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
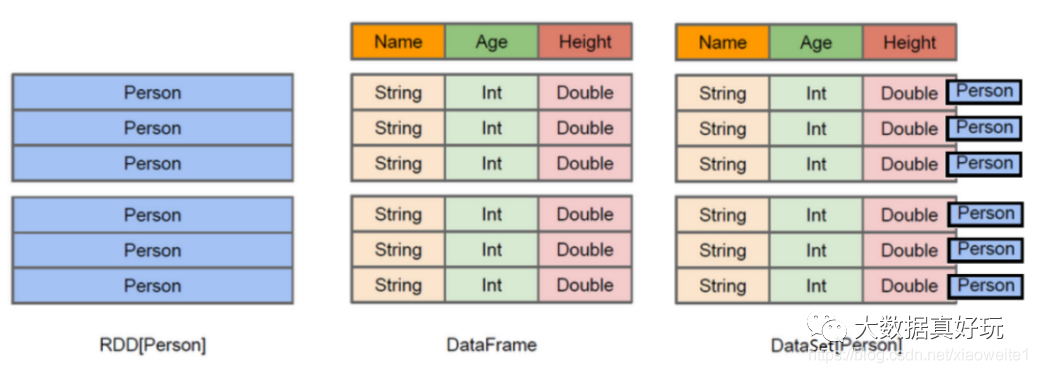
上图中左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而中间的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。了解了这些信息之后,Spark SQL的查询优化器就可以进行针对性的优化。后者由于在编译期有详尽的类型信息,编译期就可以编译出更加有针对性、更加优化的可执行代码。官方定义:
Dataset:A DataSet is a distributed collection of data. (分布式的数据集)
DataFrame:A DataFrame is a DataSet organized into named columns.(以列(列名,列类型,列值)的形式构成的分布式的数据集,按照列赋予不同的名称)
DataFrame有如下特性:
1)分布式的数据集,并且以列的方式组合的,相当于具有schema的RDD;
2)相当于关系型数据库中的表,但是底层有优化;
3)提供了一些抽象的操作,如select、filter、aggregation、plot;
4)它是由于R语言或者Pandas语言处理小数据集的经验应用到处理分布式大数据集上;
5)在1.3版本之前,叫SchemaRDD;
Schema 信息
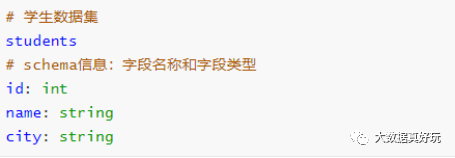
查看DataFrame中Schema是什么,执行如下命令:
df.schema
Schema信息封装在StructType中,包含很多StructField对象,源码。
StructType 定义,是一个样例类,属性为StructField的数组

StructField 定义,同样是一个样例类,有四个属性,其中字段名称和类型为必填

自定义Schema结构,官方提供的示例代码:

Row
DataFrame中每条数据封装在Row中,Row表示每行数据。
如何构建Row对象:要么是传递value,要么传递Seq,官方实例代码:
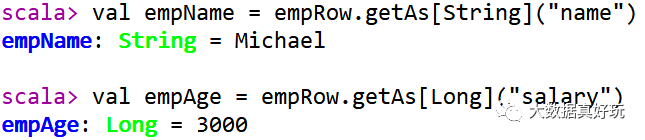
方式一:下标获取,从0开始,类似数组下标获取如何获取Row中每个字段的值呢?

方式二:指定下标,知道类型

方式三:通过As转换类型
Dataset
引入
Spark在Spark 1.3版本中引入了Dataframe,DataFrame是组织到命名列中的分布式数据集合,但是有如下几点限制:
编译时类型不安全:Dataframe API不支持编译时安全性,这限制了在结构不知道时操纵数据。以下示例在编译期间有效。但是,执行此代码时将出现运行时异常。

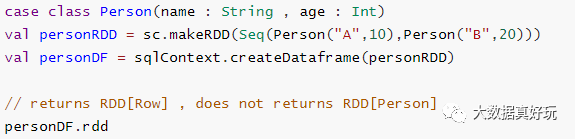
无法对域对象(丢失域对象)进行操作:将域对象转换为DataFrame后,无法从中重新生成它;下面的示例中,一旦我们从personRDD创建personDF,将不会恢复Person类的原始RDD(RDD [Person])。
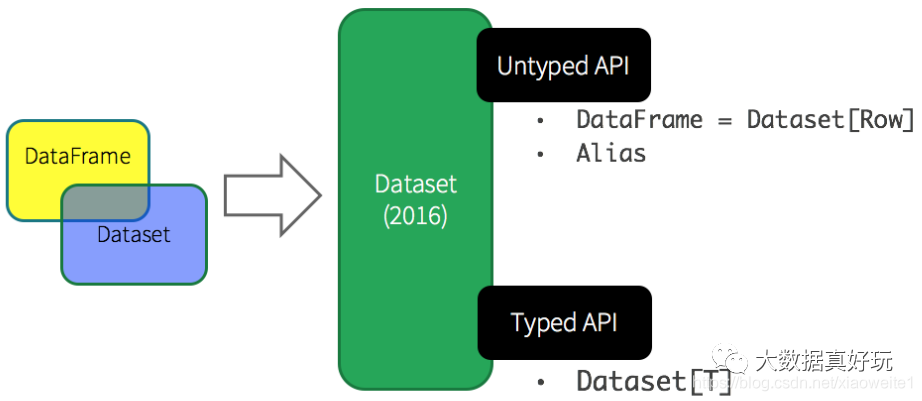
基于上述的两点,从Spark 1.6开始出现Dataset,至Spark 2.0中将DataFrame与Dataset合并,其中DataFrame为Dataset特殊类型,类型为Row。
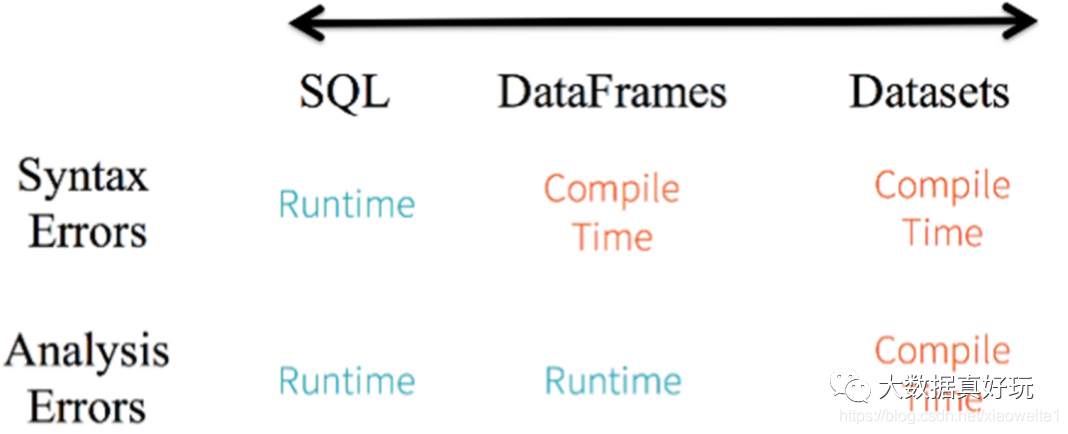
针对RDD、DataFrame与Dataset三者编程比较来说,Dataset API无论语法错误和分析错误在编译时都能发现,然而RDD和DataFrame有的需要在运行时才能发现。
此外RDD与Dataset相比较而言,由于Dataset数据使用特殊编码,所以在存储数据时更加节省内存。

总结:
Dataset是在Spark1.6中添加的新的接口,是DataFrame API的一个扩展,是Spark最新的数据抽象,结合了RDD和DataFrame的优点。
与RDD相比:保存了更多的描述信息,概念上等同于关系型数据库中的二维表;
与DataFrame相比:保存了类型信息,是强类型的,提供了编译时类型检查,调用Dataset的方法先会生成逻辑计划,然后被Spark的优化器进行优化,最终生成物理计划,然后提交到集群中运行;
Dataset 是什么
Dataset是一个强类型的特定领域的对象,这种对象可以函数式或者关系操作并行地转换。
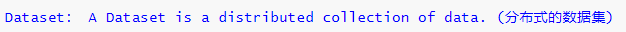
从Spark 2.0开始,DataFrame与Dataset合并,每个Dataset也有一个被称为一个DataFrame的类型化视图,这种DataFrame是Row类型的Dataset,即Dataset[Row]。
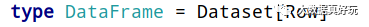
Dataset API是DataFrames的扩展,它提供了一种类型安全的,面向对象的编程接口。它是一个强类型,不可变的对象集合,映射到关系模式。在数据集的核心 API是一个称为编码器的新概念,它负责在JVM对象和表格表示之间进行转换。表格表示使用Spark内部Tungsten二进制格式存储,允许对序列化数据进行操作并提高内存利用率。Spark 1.6支持自动生成各种类型的编码器,包括基本类型(例如String,Integer,Long),Scala案例类和Java Bean。
针对Dataset数据结构来说,可以简单的从如下四个要点记忆与理解:

Spark 框架从最初的数据结构RDD、到SparkSQL中针对结构化数据封装的数据结构DataFrame,最终使用Dataset数据集进行封装,发展流程如下。
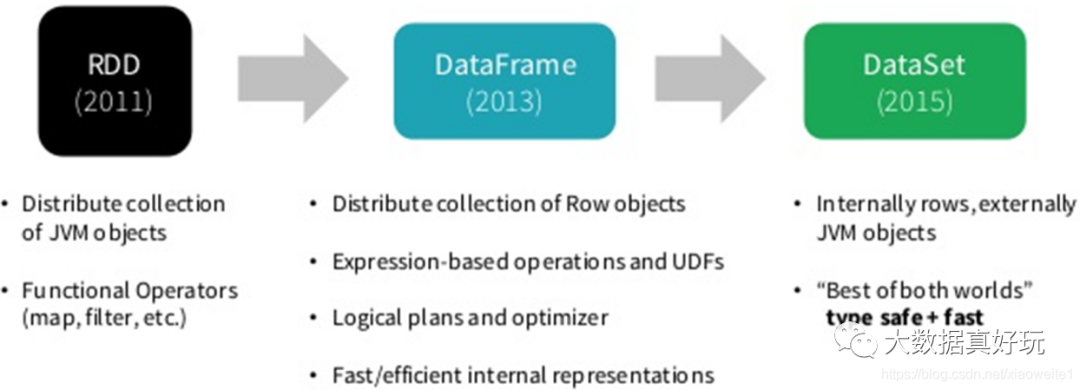
所以在实际项目中建议使用Dataset进行数据封装,数据分析性能和数据存储更加好。
面试题:如何理解RDD、DataFrame和Dataset
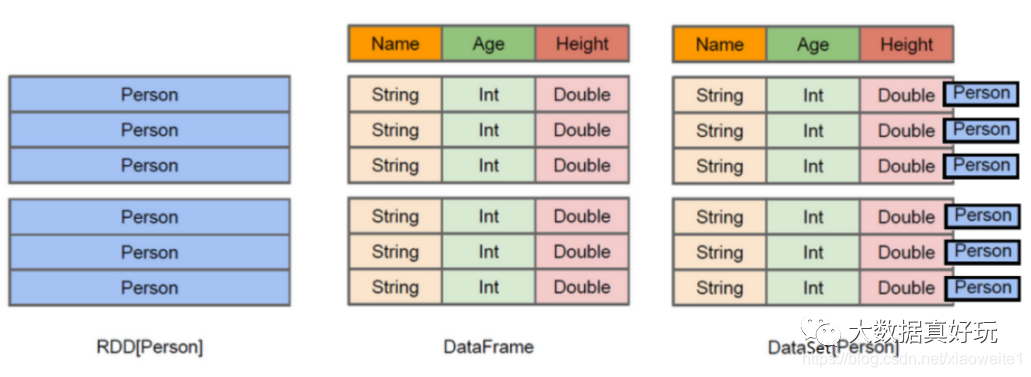
SparkSQL中常见面试题:如何理解Spark中三种数据结构RDD、DataFrame和Dataset关系?
RDD:
RDD(Resilient Distributed Datasets)叫做弹性分布式数据集,是Spark中最基本的数据抽象,源码中是一个抽象类,代表一个不可变、可分区、里面的元素可并行计算的集合。
编译时类型安全,但是无论是集群间的通信,还是IO操作都需要对对象的结构和数据进行序列化和反序列化,还存在较大的GC的性能开销,会频繁的创建和销毁对象。
DataFrame:
与RDD类似,DataFrame是一个分布式数据容器,不过它更像数据库中的二维表格,除了数据之外,还记录这数据的结构信息(即schema)。
DataFrame也是懒执行的,性能上要比RDD高(主要因为执行计划得到了优化)。
由于DataFrame每一行的数据结构一样,且存在schema中,Spark通过schema就能读懂数据,因此在通信和IO时只需要序列化和反序列化数据,而结构部分不用。Spark能够以二进制的形式序列化数据到JVM堆以外(off-heap:非堆)的内存,这些内存直接受操作系统管理,也就不再受JVM的限制和GC的困扰了。但是DataFrame不是类型安全的。
Dataset:
Dataset是DataFrame API的一个扩展,是Spark最新的数据抽象,结合了RDD和DataFrame的优点。
DataFrame=Dataset[Row](Row表示表结构信息的类型),DataFrame只知道字段,但是不知道字段类型,而Dataset是强类型的,不仅仅知道字段,而且知道字段类型。
样例类CaseClass被用来在Dataset中定义数据的结构信息,样例类中的每个属性名称直接对应到Dataset中的字段名称。
Dataset具有类型安全检查,也具有DataFrame的查询优化特性,还支持编解码器,当需要访问非堆上的数据时可以避免反序列化整个对象,提高了效率。
SparkSQL底层如何执行
RDD 的运行流程
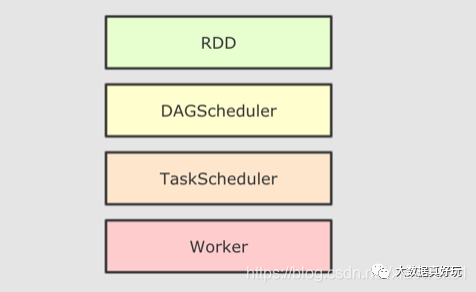
大致运行步骤:
先将 RDD 解析为由 Stage 组成的 DAG, 后将 Stage 转为 Task 直接运行
问题:
任务会按照代码所示运行, 依赖开发者的优化, 开发者的会在很大程度上影响运行效率
解决办法:
创建一个组件, 帮助开发者修改和优化代码, 但这在 RDD 上是无法实现的
为什么 RDD 无法自我优化?
RDD 没有 Schema 信息
RDD 可以同时处理结构化和非结构化的数据
SparkSQL 提供了什么?
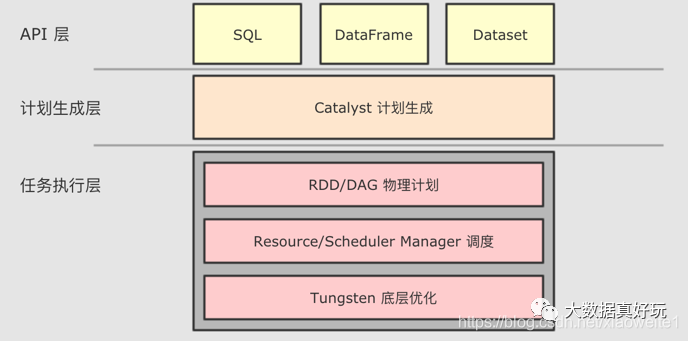
和 RDD 不同, SparkSQL 的 Dataset 和 SQL 并不是直接生成计划交给集群执行, 而是经过了一个叫做 Catalyst 的优化器, 这个优化器能够自动帮助开发者优化代码。也就是说, 在 SparkSQL 中, 开发者的代码即使不够优化, 也会被优化为相对较好的形式去执行。
为什么 SparkSQL 提供了这种能力?
首先, SparkSQL 大部分情况用于处理结构化数据和半结构化数据, 所以 SparkSQL 可以获知数据的 Schema, 从而根据其 Schema 来进行优化。
Catalyst
为了解决过多依赖 Hive 的问题, SparkSQL 使用了一个新的 SQL 优化器替代 Hive 中的优化器, 这个优化器就是 Catalyst, 整个 SparkSQL 的架构大致如下:

1.API 层简单的说就是 Spark 会通过一些 API 接受 SQL 语句 2.收到 SQL 语句以后, 将其交给 Catalyst, Catalyst 负责解析 SQL, 生成执行计划等 3.Catalyst 的输出应该是 RDD 的执行计划 4.最终交由集群运行
具体流程:

Step 1 : 解析 SQL, 并且生成 AST (抽象语法树)
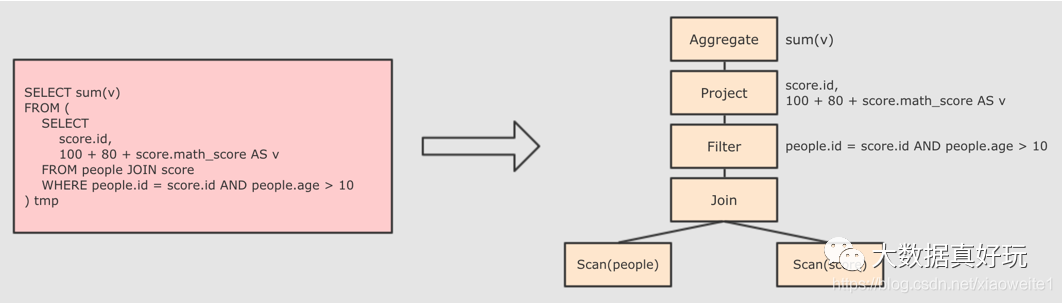
Step 2 : 在 AST 中加入元数据信息, 做这一步主要是为了一些优化, 例如 col = col 这样的条件, 下图是一个简略图, 便于理解
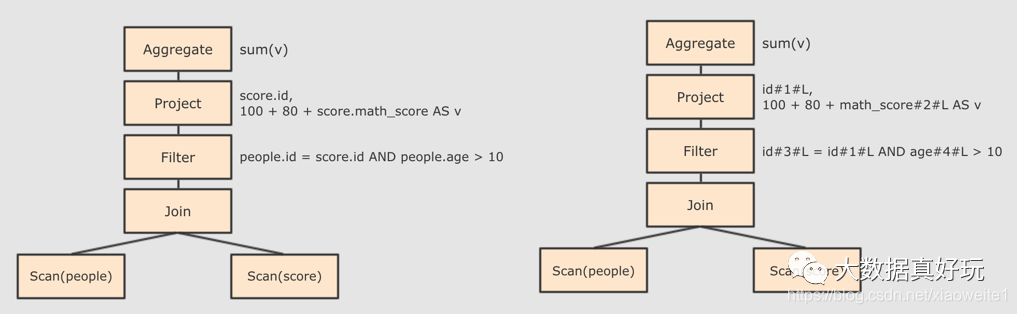
score.id → id#1#L 为 score.id 生成 id 为 1, 类型是 Long
score.math_score → math_score#2#L 为 score.math_score 生成 id 为 2, 类型为 Long
people.id → id#3#L 为 people.id 生成 id 为 3, 类型为 Long
people.age → age#4#L 为 people.age 生成 id 为 4, 类型为 Long
Step 3 : 对已经加入元数据的 AST, 输入优化器, 进行优化, 从两种常见的优化开始, 简单介绍:
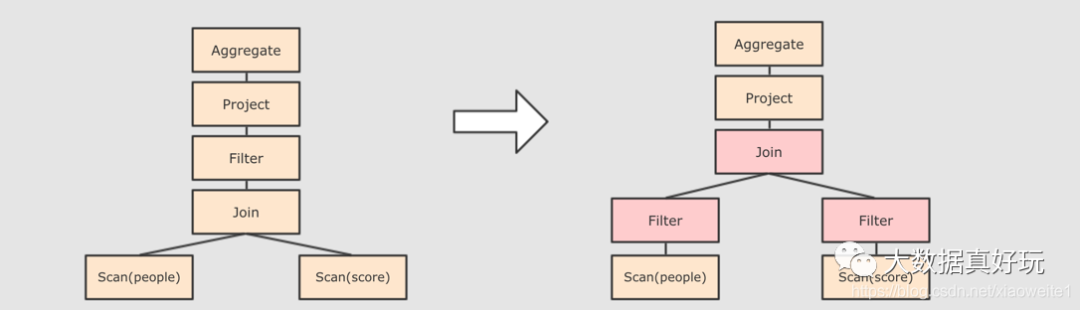
谓词下推 Predicate Pushdown, 将 Filter 这种可以减小数据集的操作下推, 放在 Scan 的位置, 这样可以减少操作时候的数据量。
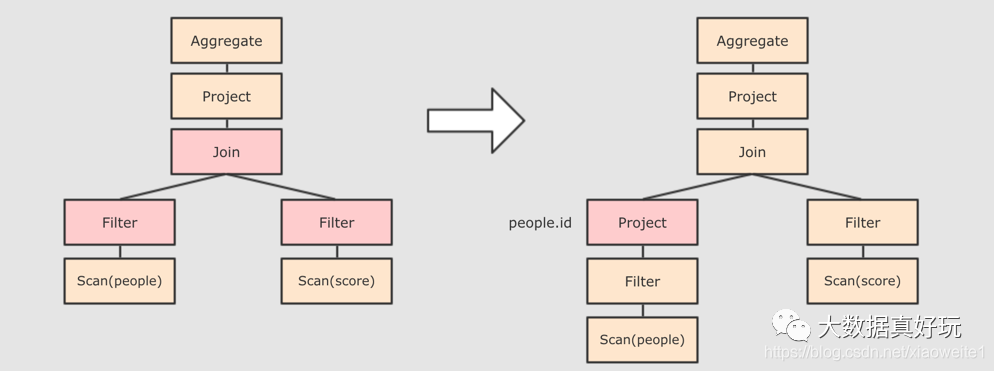
列值裁剪 Column Pruning, 在谓词下推后, people 表之上的操作只用到了 id 列, 所以可以把其它列裁剪掉, 这样可以减少处理的数据量, 从而优化处理速度
还有其余很多优化点, 大概一共有一二百种, 随着 SparkSQL 的发展, 还会越来越多, 感兴趣的同学可以继续通过源码了解, 源码在 org.apache.spark.sql.catalyst.optimizer.Optimizer
Step 4 : 上面的过程生成的 AST 其实最终还没办法直接运行, 这个 AST 叫做 逻辑计划, 结束后, 需要生成 物理计划, 从而生成 RDD 来运行。
在生成物理计划的时候, 会经过成本模型对整棵树再次执行优化, 选择一个更好的计划。
在生成物理计划以后, 因为考虑到性能, 所以会使用代码生成, 在机器中运行。
可以使用 queryExecution 方法查看逻辑执行计划, 使用 explain 方法查看物理执行计划。
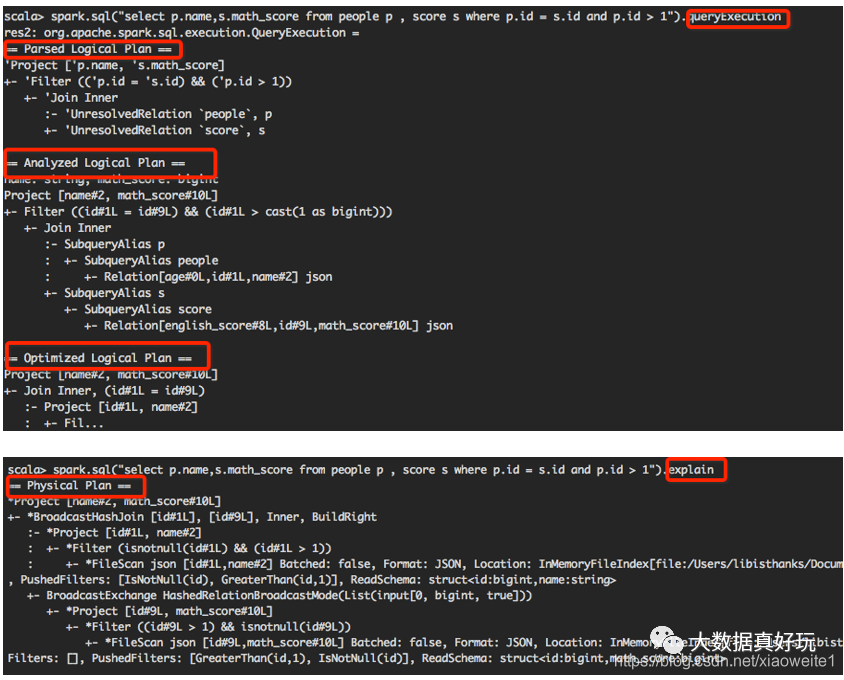
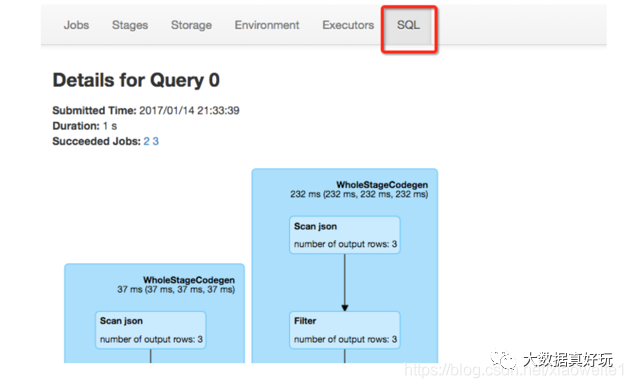
也可以使用 Spark WebUI 进行查看:
SparkSQL 和 RDD 不同的主要点是在于其所操作的数据是结构化的, 提供了对数据更强的感知和分析能力, 能够对代码进行更深层的优化, 而这种能力是由一个叫做 Catalyst 的优化器所提供的。
Catalyst 的主要运作原理是分为三步, 先对 SQL 或者 Dataset 的代码解析, 生成逻辑计划, 后对逻辑计划进行优化, 再生成物理计划, 最后生成代码到集群中以 RDD 的形式运行。