
【Spark重点难点-面试篇】SparkSQL面试专题

本文已经加入「大数据成神之路PDF版」中提供下载。
你可以关注公众号,后台回复:「PDF」 即可获取。
《【Spark重点难点01】你从未深入理解的RDD和关键角色》 《【Spark重点难点02】你以为的Shuffle和真正的Shuffle》 《【Spark重点难点03】你的数据存在哪了?》 《【Spark重点难点04】你的代码跑起来谁说了算?(内存管理)》 《【Spark重点难点05】SparkSQL YYDS(上)!》 《【Spark重点难点06】SparkSQL YYDS(中)!》 《【Spark重点难点07】SparkSQL YYDS(加餐)!》 《【Spark重点难点08】Spark3.0中的AQE和DPP小总结》 《Spark3.0核心调优参数小总结》
1.谈谈你对Spark SQL的理解
Spark SQL是一个用来处理结构化数据的Spark组件,前身是shark,但是shark过多的依赖于hive如采用hive的语法解析器、查询优化器等,制约了Spark各个组件之间的相互集成,因此Spark SQL应运而生。
Spark SQL在汲取了shark诸多优势如内存列存储、兼容hive等基础上,做了重新的构造,因此也摆脱了对hive的依赖,但同时兼容hive。除了采取内存列存储优化性能,还引入了字节码生成技术、CBO和RBO对查询等进行动态评估获取最优逻辑计划、物理计划执行等。基于这些优化,使得Spark SQL相对于原有的SQL on Hadoop技术在性能方面得到有效提升。
同时,Spark SQL支持多种数据源,如JDBC、HDFS、HBase。它的内部组件,如SQL的语法解析器、分析器等支持重定义进行扩展,能更好的满足不同的业务场景。与Spark Core无缝集成,提供了DataSet/DataFrame的可编程抽象数据模型,并且可被视为一个分布式的SQL查询引擎。
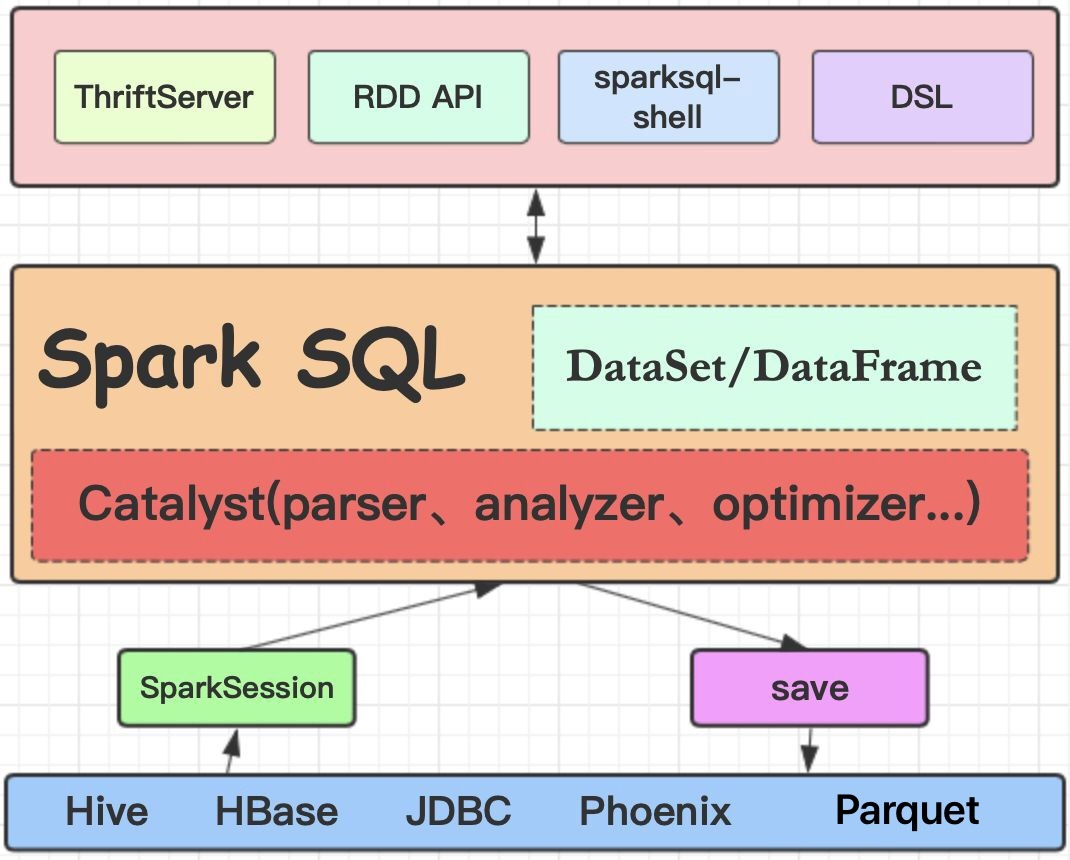
2.谈谈你对DataSet/DataFrame的理解
DataSet/DataFrame都是Spark SQL提供的分布式数据集,相对于RDD而言,除了记录数据以外,还记录表的schema信息。
DataSet是自Spark1.6开始提供的一个分布式数据集,具有RDD的特性比如强类型、可以使用强大的lambda表达式,并且使用Spark SQL的优化执行引擎。DataSet API支持Scala和Java语言,不支持Python。但是鉴于Python的动态特性,它仍然能够受益于DataSet API(如,你可以通过一个列名从Row里获取这个字段 row.columnName),类似的还有R语言。
DataFrame是DataSet以命名列方式组织的分布式数据集,类似于RDBMS中的表,或者R和Python中的 data frame。DataFrame API支持Scala、Java、Python、R。在Scala API中,DataFrame变成类型为Row的Dataset:
type DataFrame = Dataset[Row]。
DataFrame在编译期不进行数据中字段的类型检查,在运行期进行检查。但DataSet则与之相反,因为它是强类型的。此外,二者都是使用catalyst进行sql的解析和优化。为了方便,以下统一使用DataSet统称。
DataSet创建
DataSet通常通过加载外部数据或通过RDD转化创建。
加载外部数据
以加载json和mysql为例:
val ds = sparkSession.read.json("/路径/people.json")
val ds = sparkSession.read.format("jdbc")
.options(Map("url" -> "jdbc:mysql://ip:port/db",
"driver" -> "com.mysql.jdbc.Driver",
"dbtable" -> "tableName", "user" -> "root", "root" -> "123")).load()
RDD转换为DataSet
通过RDD转化创建DataSet,关键在于为RDD指定schema,通常有两种方式(伪代码):
1.定义一个case class,利用反射机制来推断
1) 从HDFS中加载文件为普通RDD
val lineRDD = sparkContext.textFile("hdfs://ip:port/person.txt").map(_.split(" "))
2) 定义case class(相当于表的schema)
case class Person(id:Int, name:String, age:Int)
3) 将RDD和case class关联
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
4) 将RDD转换成DataFrame
val ds= personRDD.toDF
2. 手动定义一个schema StructType,直接指定在RDD上
val schemaString ="name age"
val schema = StructType(schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true)))
val rowRdd = peopleRdd.map(p=>Row(p(0),p(1)))
val ds = sparkSession.createDataFrame(rowRdd,schema)
操作DataSet的两种风格语法
DSL语法
1.查询DataSet部分列中的内容
personDS.select(col("name"))
personDS.select(col("name"), col("age"))
2.查询所有的name和age和salary,并将salary加1000
personDS.select(col("name"), col("age"), col("salary") + 1000)
personDS.select(personDS("name"), personDS("age"), personDS("salary") + 1000)
3.过滤age大于18的
personDS.filter(col("age") > 18)
4.按年龄进行分组并统计相同年龄的人数
personDS.groupBy("age").count()
注意:直接使用col方法需要import org.apache.spark.sql.functions._
SQL语法
如果想使用SQL风格的语法,需要将DataSet注册成表
personDS.registerTempTable("person")
//查询年龄最大的前两名
val result = sparkSession.sql("select * from person order by age desc limit 2")
//保存结果为json文件。注意:如果不指定存储格式,则默认存储为parquet
result.write.format("json").save("hdfs://ip:port/res2")
3.说说Spark SQL的几种使用方式
sparksql-shell交互式查询
就是利用Spark提供的shell命令行执行SQL
编程
首先要获取Spark SQL编程"入口":SparkSession(当然在早期版本中大家可能更熟悉的是SQLContext,如果是操作hive则为HiveContext)。这里以读取parquet为例:
val spark = SparkSession.builder()
.appName("example").master("local[*]").getOrCreate();
val df = sparkSession.read.format("parquet").load("/路径/parquet文件")
然后就可以针对df进行业务处理了。
Thriftserver
beeline客户端连接操作
启动spark-sql的thrift服务,sbin/start-thriftserver.sh,启动脚本中配置好Spark集群服务资源、地址等信息。然后通过beeline连接thrift服务进行数据处理。
hive-jdbc驱动包来访问spark-sql的thrift服务
在项目pom文件中引入相关驱动包,跟访问mysql等jdbc数据源类似。示例:
Class.forName("org.apache.hive.jdbc.HiveDriver")
val conn = DriverManager.getConnection("jdbc:hive2://ip:port", "root", "123");
try {
val stat = conn.createStatement()
val res = stat.executeQuery("select * from people limit 1")
while (res.next()) {
println(res.getString("name"))
}
} catch {
case e: Exception => e.printStackTrace()
} finally{
if(conn!=null) conn.close()
}
4. 说说Spark SQL 获取Hive数据的方式
Spark SQL读取hive数据的关键在于将hive的元数据作为服务暴露给Spark。除了通过上面thriftserver jdbc连接hive的方式,也可以通过下面这种方式:
首先,配置 $HIVE_HOME/conf/hive-site.xml,增加如下内容:
hive.metastore.uris
thrift://ip:port
然后,启动hive metastore。
最后,将hive-site.xml复制或者软链到SPARK_HOME/lib/下,启动spark-sql即可操作hive中的库和表。而此时使用hive元数据获取SparkSession的方式为:
val spark = SparkSession.builder()
.config(sparkConf).enableHiveSupport().getOrCreate()
5. 分别说明UDF、UDAF、Aggregator
UDF
UDF是最基础的用户自定义函数,以自定义一个求字符串长度的udf为例:
val udf_str_length = udf{(str:String) => str.length}
spark.udf.register("str_length",udf_str_length)
val ds =sparkSession.read.json("路径/people.json")
ds.createOrReplaceTempView("people")
sparkSession.sql("select str_length(address) from people")
UDAF
定义UDAF,需要继承抽象类UserDefinedAggregateFunction,它是弱类型的,下面的aggregator是强类型的。以求平均数为例:
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.expressions.MutableAggregationBuffer
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction
import org.apache.spark.sql.types._
object MyAverage extends UserDefinedAggregateFunction {
// Data types of input arguments of this aggregate function
def inputSchema: StructType = StructType(StructField("inputColumn", LongType) :: Nil)
// Data types of values in the aggregation buffer
def bufferSchema: StructType = {
StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil)
}
// The data type of the returned value
def dataType: DataType = DoubleType
// Whether this function always returns the same output on the identical input
def deterministic: Boolean = true
// Initializes the given aggregation buffer. The buffer itself is a `Row` that in addition to
// standard methods like retrieving a value at an index (e.g., get(), getBoolean()), provides
// the opportunity to update its values. Note that arrays and maps inside the buffer are still
// immutable.
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
// Updates the given aggregation buffer `buffer` with new input data from `input`
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!input.isNullAt(0)) {
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
}
// Merges two aggregation buffers and stores the updated buffer values back to `buffer1`
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// Calculates the final result
def evaluate(buffer: Row): Double = buffer.getLong(0).toDouble / buffer.getLong(1)
}
// Register the function to access it
spark.udf.register("myAverage", MyAverage)
val df = spark.read.json("examples/src/main/resources/employees.json")
df.createOrReplaceTempView("employees")
df.show()
val result = spark.sql("SELECT myAverage(salary) as average_salary FROM employees")
result.show()
Aggregator
import org.apache.spark.sql.{Encoder, Encoders, SparkSession}
import org.apache.spark.sql.expressions.Aggregator
case class Employee(name: String, salary: Long)
case class Average(var sum: Long, var count: Long)
object MyAverage extends Aggregator[Employee, Average, Double] {
// A zero value for this aggregation. Should satisfy the property that any b + zero = b
def zero: Average = Average(0L, 0L)
// Combine two values to produce a new value. For performance, the function may modify `buffer`
// and return it instead of constructing a new object
def reduce(buffer: Average, employee: Employee): Average = {
buffer.sum += employee.salary
buffer.count += 1
buffer
}
// Merge two intermediate values
def merge(b1: Average, b2: Average): Average = {
b1.sum += b2.sum
b1.count += b2.count
b1
}
// Transform the output of the reduction
def finish(reduction: Average): Double = reduction.sum.toDouble / reduction.count
// Specifies the Encoder for the intermediate value type
def bufferEncoder: Encoder[Average] = Encoders.product
// Specifies the Encoder for the final output value type
def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
val ds = spark.read.json("examples/src/main/resources/employees.json").as[Employee]
ds.show()
// Convert the function to a `TypedColumn` and give it a name
val averageSalary = MyAverage.toColumn.name("average_salary")
val result = ds.select(averageSalary)
result.show()
6. 对比一下Spark SQL与HiveSQL
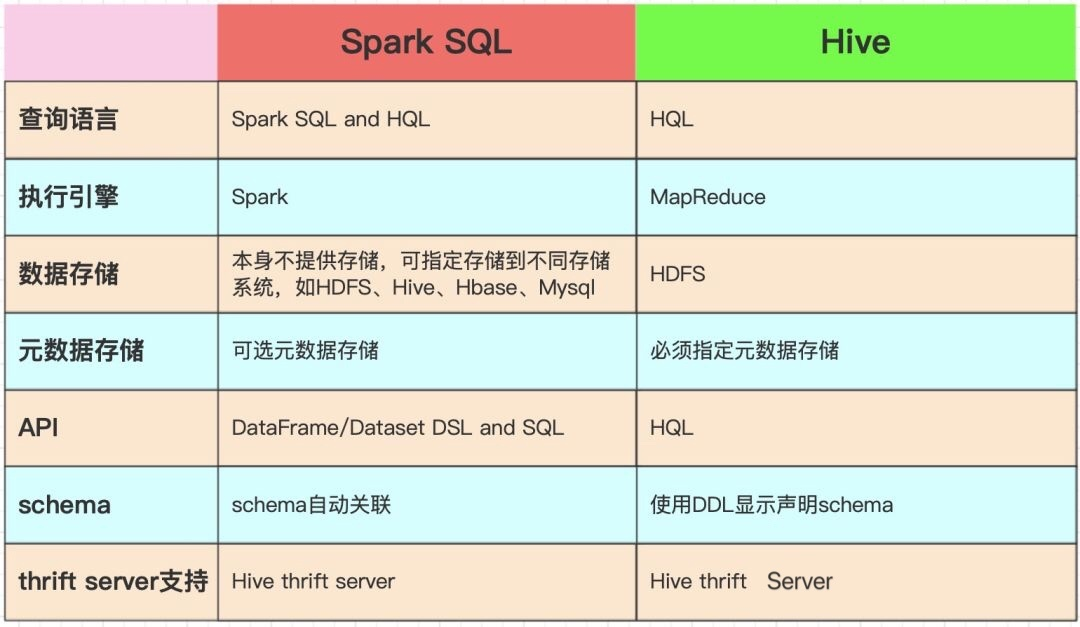
7.说说你对Spark SQL 小文件问题处理的理解
在生产中,无论是通过SQL语句或者Scala/Java等代码的方式使用Spark SQL处理数据,在Spark SQL写数据时,往往会遇到生成的小文件过多的问题,而管理这些大量的小文件,是一件非常头疼的事情。
大量的小文件会影响Hadoop集群管理或者Spark在处理数据时的稳定性:
Spark SQL写Hive或者直接写入HDFS,过多的小文件会对NameNode内存管理等产生巨大的压力,会影响整个集群的稳定运行
容易导致task数过多,如果超过参数spark.driver.maxResultSize的配置(默认1g),会抛出类似如下的异常,影响任务的处理
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Total size of serialized results of 478 tasks (2026.0 MB) is bigger than spark.driver.maxResultSize (1024.0 MB)
当然可以通过调大spark.driver.maxResultSize的默认配置来解决问题,但如果不能从源头上解决小文件问题,以后还可能遇到类似的问题。
此外,Spark在处理任务时,一个分区分配一个task进行处理,多个分区并行处理,虽然并行处理能够提高处理效率,但不是意味着task数越多越好。如果数据量不大,过多的task运行反而会影响效率。
最后,Spark中一个task处理一个分区从而也会影响最终生成的文件数。
在数仓建设中,产生小文件过多的原因有很多种,比如:
流式处理中,每个批次的处理执行保存操作也会产生很多小文件 为了解决数据更新问题,同一份数据保存了不同的几个状态,也容易导致文件数过多
那么如何解决这种小文件的问题呢?
通过repartition或coalesce算子控制最后的DataSet的分区数
注意repartition和coalesce的区别将Hive风格的Coalesce and Repartition Hint 应用到Spark SQL
需要注意这种方式对Spark的版本有要求,建议在Spark2.4.X及以上版本使用,示例:
INSERT ... SELECT /*+ COALESCE(numPartitions) */ ...
INSERT ... SELECT /*+ REPARTITION(numPartitions) */ ...
小文件定期合并可以定时通过异步的方式针对Hive分区表的每一个分区中的小文件进行合并操作
上述只是给出3种常见的解决办法,并且要结合实际用到的技术和场景去具体处理,比如对于HDFS小文件过多,也可以通过生成HAR 文件或者Sequence File来解决。
8.SparkSQL读写Hive metastore Parquet遇到过什么问题吗?
Spark SQL为了更好的性能,在读写Hive metastore parquet格式的表时,会默认使用自己的Parquet SerDe,而不是采用Hive的SerDe进行序列化和反序列化。该行为可以通过配置参数spark.sql.hive.convertMetastoreParquet进行控制,默认true。
这里从表schema的处理角度而言,就必须注意Hive和Parquet兼容性,主要有两个区别:
Hive是大小写敏感的,但Parquet相反 Hive会将所有列视为nullable,但是nullability在parquet里有独特的意义
由于上面的原因,在将Hive metastore parquet转化为Spark SQL parquet时,需要兼容处理一下Hive和Parquet的schema,即需要对二者的结构进行一致化。主要处理规则是:
有相同名字的字段必须要有相同的数据类型,忽略nullability。兼容处理的字段应该保持Parquet侧的数据类型,这样就可以处理到nullability类型了(空值问题)
兼容处理的schema应只包含在Hive元数据里的schema信息,主要体现在以下两个方面:
(1)只出现在Parquet schema的字段会被忽略
(2)只出现在Hive元数据里的字段将会被视为nullable,并处理到兼容后的schema中
关于schema(或者说元数据metastore),Spark SQL在处理Parquet表时,同样为了更好的性能,会缓存Parquet的元数据信息。此时,如果直接通过Hive或者其他工具对该Parquet表进行修改导致了元数据的变化,那么Spark SQL缓存的元数据并不能同步更新,此时需要手动刷新Spark SQL缓存的元数据,来确保元数据的一致性,方式如下:
// 第一种方式应用的比较多
1. sparkSession.catalog.refreshTable(s"${dbName.tableName}")
2. sparkSession.catalog.refreshByPath(s"${path}")
9.说说SparkSQL中产生笛卡尔积的几种典型场景以及处理策略
Spark SQL几种产生笛卡尔积的典型场景
首先来看一下在Spark SQL中产生笛卡尔积的几种典型SQL:
join语句中不指定on条件
select * from test_partition1 join test_partition2;
join语句中指定不等值连接
select * from test_partition1 t1 inner join test_partition2 t2 on t1.name <> t2.name;
join语句on中用or指定连接条件
select * from test_partition1 t1 join test_partition2 t2 on t1.id = t2.id or t1.name = t2.name;
join语句on中用||指定连接条件
select * from test_partition1 t1 join test_partition2 t2 on t1.id = t2.id || t1.name = t2.name;
除了上述举的几个典型例子,实际业务开发中产生笛卡尔积的原因多种多样。
同时需要注意,在一些SQL中即使满足了上述4种规则之一也不一定产生笛卡尔积。比如,对于join语句中指定不等值连接条件的下述SQL不会产生笛卡尔积:
--在Spark SQL内部优化过程中针对join策略的选择,最终会通过SortMergeJoin进行处理。
select * from test_partition1 t1 join test_partition2 t2 on t1.id = t2.i
此外,对于直接在SQL中使用cross join的方式,也不一定产生笛卡尔积。比如下述SQL:
-- Spark SQL内部优化过程中选择了SortMergeJoin方式进行处理
select * from test_partition1 t1 cross join test_partition2 t2 on t1.id = t2.id;
但是如果cross join没有指定on条件同样会产生笛卡尔积。
那么如何判断一个SQL是否产生了笛卡尔积呢?
Spark SQL是否产生了笛卡尔积
以join语句不指定on条件产生笛卡尔积的SQL为例:
-- test_partition1和test_partition2是Hive分区表
select * from test_partition1 join test_partition2;
通过Spark UI上SQL一栏查看上述SQL执行图,如下:
可以看出,因为该join语句中没有指定on连接查询条件,导致了CartesianProduct即笛卡尔积。
再来看一下该join语句的逻辑计划和物理计划:
== Parsed Logical Plan ==
'GlobalLimit 1000
+- 'LocalLimit 1000
+- 'Project [*]
+- 'UnresolvedRelation `t`
== Analyzed Logical Plan ==
id: string, name: string, dt: string, id: string, name: string, dt: string
GlobalLimit 1000
+- LocalLimit 1000
+- Project [id#84, name#85, dt#86, id#87, name#88, dt#89]
+- SubqueryAlias `t`
+- Project [id#84, name#85, dt#86, id#87, name#88, dt#89]
+- Join Inner
:- SubqueryAlias `default`.`test_partition1`
: +- HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#84, name#85], [dt#86]
+- SubqueryAlias `default`.`test_partition2`
+- HiveTableRelation `default`.`test_partition2`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#87, name#88], [dt#89]
== Optimized Logical Plan ==
GlobalLimit 1000
+- LocalLimit 1000
+- Join Inner
:- HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#84, name#85], [dt#86]
+- HiveTableRelation `default`.`test_partition2`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#87, name#88], [dt#89]
== Physical Plan ==
CollectLimit 1000
+- CartesianProduct
:- Scan hive default.test_partition1 [id#84, name#85, dt#86], HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#84, name#85], [dt#86]
+- Scan hive default.test_partition2 [id#87, name#88, dt#89], HiveTableRelation `default`.`test_partition2`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#87, name#88], [dt#89]
通过逻辑计划到物理计划,以及最终的物理计划选择CartesianProduct,可以分析得出该SQL最终确实产生了笛卡尔积。
Spark SQL中产生笛卡尔积的处理策略
Spark SQL中主要有ExtractEquiJoinKeys(Broadcast Hash Join、Shuffle Hash Join、Sort Merge Join,这3种是我们比较熟知的Spark SQL join)和Without joining keys(CartesianProduct、BroadcastNestedLoopJoin)join策略。
那么,如何判断SQL是否产生了笛卡尔积就迎刃而解。
在利用Spark SQL执行SQL任务时,通过查看SQL的执行图来分析是否产生了笛卡尔积。如果产生笛卡尔积,则将任务杀死,进行任务优化避免笛卡尔积。
分析Spark SQL的逻辑计划和物理计划,通过程序解析计划推断SQL最终是否选择了笛卡尔积执行策略。如果是,及时提示风险。具体可以参考Spark SQL join策略选择的源码:
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
// --- BroadcastHashJoin --------------------------------------------------------------------
// broadcast hints were specified
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if canBroadcastByHints(joinType, left, right) =>
val buildSide = broadcastSideByHints(joinType, left, right)
Seq(joins.BroadcastHashJoinExec(
leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))
// broadcast hints were not specified, so need to infer it from size and configuration.
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if canBroadcastBySizes(joinType, left, right) =>
val buildSide = broadcastSideBySizes(joinType, left, right)
Seq(joins.BroadcastHashJoinExec(
leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))
// --- ShuffledHashJoin ---------------------------------------------------------------------
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if !conf.preferSortMergeJoin && canBuildRight(joinType) && canBuildLocalHashMap(right)
&& muchSmaller(right, left) ||
!RowOrdering.isOrderable(leftKeys) =>
Seq(joins.ShuffledHashJoinExec(
leftKeys, rightKeys, joinType, BuildRight, condition, planLater(left), planLater(right)))
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if !conf.preferSortMergeJoin && canBuildLeft(joinType) && canBuildLocalHashMap(left)
&& muchSmaller(left, right) ||
!RowOrdering.isOrderable(leftKeys) =>
Seq(joins.ShuffledHashJoinExec(
leftKeys, rightKeys, joinType, BuildLeft, condition, planLater(left), planLater(right)))
// --- SortMergeJoin ------------------------------------------------------------
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if RowOrdering.isOrderable(leftKeys) =>
joins.SortMergeJoinExec(
leftKeys, rightKeys, joinType, condition, planLater(left), planLater(right)) :: Nil
// --- Without joining keys ------------------------------------------------------------
// Pick BroadcastNestedLoopJoin if one side could be broadcast
case j @ logical.Join(left, right, joinType, condition)
if canBroadcastByHints(joinType, left, right) =>
val buildSide = broadcastSideByHints(joinType, left, right)
joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
case j @ logical.Join(left, right, joinType, condition)
if canBroadcastBySizes(joinType, left, right) =>
val buildSide = broadcastSideBySizes(joinType, left, right)
joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
// Pick CartesianProduct for InnerJoin
case logical.Join(left, right, _: InnerLike, condition) =>
joins.CartesianProductExec(planLater(left), planLater(right), condition) :: Nil
case logical.Join(left, right, joinType, condition) =>
val buildSide = broadcastSide(
left.stats.hints.broadcast, right.stats.hints.broadcast, left, right)
// This join could be very slow or OOM
joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
// --- Cases where this strategy does not apply ---------------------------------------------
case _ => Nil
}
10. 具体讲讲Spark SQL/Hive中的一些实用函数
字符串函数
concat
对字符串进行拼接:concat(str1, str2, ..., strN) ,参数:str1、str2...是要进行拼接的字符串。
-- return the concatenation of str1、str2、..., strN
-- SparkSQL
select concat('Spark', 'SQL');
concat_ws
在拼接的字符串中间添加某种分隔符:concat_ws(sep, [str | array(str)]+)。
参数1:分隔符,如 - ;参数2:要拼接的字符串(可多个)
-- return the concatenation of the strings separated by sep
-- Spark-SQL
select concat_ws("-", "Spark", "SQL");
encode
设置编码格式:encode(str, charset)。
参数1:要进行编码的字符串 ;参数2:使用的编码格式,如UTF-8
-- encode the first argument using the second argument character set
select encode("HIVE", "UTF-8");
decode
转码:decode(bin, charset)。
参数1:进行转码的binary ;
参数2:使用的转码格式,如UTF-8
-- decode the first argument using the second argument character set
select decode(encode("HIVE", "UTF-8"), "UTF-8");
format_string / printf
格式化字符串:format_string(strfmt, obj, ...)
-- returns a formatted string from printf-style format strings
select format_string("Spark SQL %d %s", 100, "days");
initcap / lower / upper
initcap:将每个单词的首字母转为大写,其他字母小写。单词之间以空白分隔。
upper:全部转为大写。
lower:全部转为小写。
-- Spark Sql
select initcap("spaRk sql");
-- SPARK SQL
select upper("sPark sql");
-- spark sql
select lower("Spark Sql");
length
返回字符串的长度。
-- 返回4
select length("Hive");
lpad / rpad
返回固定长度的字符串,如果长度不够,用某种字符进行补全。
lpad(str, len, pad):左补全
rpad(str, len, pad):右补全
注意:如果参数str的长度大于参数len,则返回的结果长度会被截取为长度为len的字符串
-- vehi
select lpad("hi", 4, "ve");
-- hive
select rpad("hi", 4, "ve");
-- spar
select lpad("spark", 4, "ve");
trim / ltrim / rtrim
去除空格或者某种字符。
trim(str) / trim(trimStr, str):首尾去除。
ltrim(str) / ltrim(trimStr, str):左去除。
rtrim(str) / rtrim(trimStr, str):右去除。
-- hive
select trim(" hive ");
-- SparkSQL
SELECT ltrim("Sp", "SSparkSQLS") as tmp;
regexp_extract
正则提取某些字符串
-- 2000
select regexp_extract("1000-2000", "(\\d+)-(\\d+)", 2);
regexp_replace
正则替换
-- r-r
select regexp_replace("100-200", "(\\d+)", "r");
repeat
repeat(str, n):复制给定的字符串n次
-- aa
select repeat("a", 2);
instr / locate
返回截取字符串的位置。如果匹配的字符串不存在,则返回0
-- returns the (1-based) index of the first occurrence of substr in str.
-- 6
select instr("SparkSQL", "SQL");
-- 0
select locate("A", "fruit");
space
在字符串前面加n个空格
select concat(space(2), "A");
split
split(str, regex):以某字符拆分字符串 split(str, regex)
-- ["one","two"]
select split("one two", " ");
substr / substring_index
-- k SQL
select substr("Spark SQL", 5);
-- 从后面开始截取,返回SQL
select substr("Spark SQL", -3);
-- k
select substr("Spark SQL", 5, 1);
-- org.apache。注意:如果参数3为负值,则从右边取值
select substring_index("org.apache.spark", ".", 2);
translate
替换某些字符为指定字符
-- The translate will happen when any character in the string matches the character in the `matchingString`
-- A1B2C3
select translate("AaBbCc", "abc", "123");
JSON函数
get_json_object
-- v2
select get_json_object('{"k1": "v1", "k2": "v2"}', '$.k2');
from_json
select tmp.k from (
select from_json('{"k": "fruit", "v": "apple"}','k STRING, v STRING', map("","")) as tmp
);
to_json
-- 可以把所有字段转化为json字符串,然后表示成value字段
select to_json(struct(*)) AS value;
时间函数
current_date / current_timestamp
获取当前时间
select current_date;
select current_timestamp;
从日期时间中提取字段/格式化时间
1)year、month、day、dayofmonth、hour、minute、second
-- 20
select day("2020-12-20");
2)dayofweek(1 = Sunday, 2 = Monday, ..., 7 = Saturday)、dayofye
-- 7
select dayofweek("2020-12-12");
3)weekofyear(date)
/**
* Extracts the week number as an integer from a given date/timestamp/string.
*
* A week is considered to start on a Monday and week 1 is the first week with more than 3 days,
* as defined by ISO 8601
*
* @return An integer, or null if the input was a string that could not be cast to a date
* @group datetime_funcs
* @since 1.5.0
*/
def weekofyear(e: Column): Column = withExpr { WeekOfYear(e.expr) }
-- 50
select weekofyear("2020-12-12");
4)trunc
截取某部分的日期,其他部分默认为01。第二个参数: YEAR、YYYY、YY、MON、MONTH、MM
-- 2020-01-01
select trunc("2020-12-12", "YEAR");
-- 2020-12-01
select trunc("2020-12-12", "MM");
5)date_trunc
参数:YEAR、YYYY、YY、MON、MONTH、MM、DAY、DD、HOUR、MINUTE、SECOND、WEEK、QUARTER
-- 2012-12-12 09:00:00
select date_trunc("HOUR" ,"2012-12-12T09:32:05.359");
6)date_format
按照某种格式格式化时间
-- 2020-12-12
select date_format("2020-12-12 12:12:12", "yyyy-MM-dd");
日期时间转换
1)unix_timestamp
返回当前时间的unix时间戳。
select unix_timestamp();
-- 1609257600
select unix_timestamp("2020-12-30", "yyyy-MM-dd");
2)from_unixtime
将unix epoch(1970-01-01 00:00:00 UTC)中的秒数转换为以给定格式表示当前系统时区中该时刻的时间戳的字符串。
select from_unixtime(1609257600, "yyyy-MM-dd HH:mm:ss");
3)to_unix_timestamp
将时间转化为时间戳。
-- 1609257600
select to_unix_timestamp("2020-12-30", "yyyy-MM-dd");
4)to_date / date
将时间字符串转化为date。
-- 2020-12-30
select to_date("2020-12-30 12:30:00");
select date("2020-12-30");
5)to_timestamp
将时间字符串转化为timestamp。
select to_timestamp("2020-12-30 12:30:00");
6)quarter
从给定的日期/时间戳/字符串中提取季度。
-- 4
select quarter("2020-12-30");
日期、时间计算
1)months_between(end, start)
返回两个日期之间的月数。参数1为截止时间,参数2为开始时间
-- 3.94959677
select months_between("1997-02-28 10:30:00", "1996-10-30");
2)add_months
返回某日期后n个月后的日期。
-- 2020-12-28
select add_months("2020-11-28", 1);
3)last_day(date)
返回某个时间的当月最后一天
-- 2020-12-31
select last_day("2020-12-01");
4)next_day(start_date, day_of_week)
返回某时间后the first date基于specified day of the week。
参数1:开始时间。
参数2:Mon、Tue、Wed、Thu、Fri、Sat、Sun。
-- 2020-12-07
select next_day("2020-12-01", "Mon");
5)date_add(start_date, num_days)
返回指定时间增加num_days天后的时间
-- 2020-12-02
select date_add("2020-12-01", 1);
6)datediff(endDate, startDate)
两个日期相差的天数
-- 3
select datediff("2020-12-01", "2020-11-28");
7)关于UTC时间
-- to_utc_timestamp(timestamp, timezone) - Given a timestamp like '2017-07-14 02:40:00.0', interprets it as a time in the given time zone, and renders that time as a timestamp in UTC. For example, 'GMT+1' would yield '2017-07-14 01:40:00.0'.
select to_utc_timestamp("2020-12-01", "Asia/Seoul") ;
-- from_utc_timestamp(timestamp, timezone) - Given a timestamp like '2017-07-14 02:40:00.0', interprets it as a time in UTC, and renders that time as a timestamp in the given time zone. For example, 'GMT+1' would yield '2017-07-14 03:40:00.0'.
select from_utc_timestamp("2020-12-01", "Asia/Seoul");
常用的开窗函数
开窗函数格式通常满足:
function_name([argument_list])
OVER (
[PARTITION BY partition_expression,…]
[ORDER BY sort_expression, … [ASC|DESC]])
function_name: 函数名称,比如SUM()、AVG()
partition_expression:分区列
sort_expression:排序列
注意:以下举例涉及的表employee中字段含义:name(员工姓名)、dept_no(部门编号)、salary(工资)
cume_dist
如果按升序排列,则统计:小于等于当前值的行数/总行数(number of rows ≤ current row)/(total number of rows)。如果是降序排列,则统计:大于等于当前值的行数/总行数。用于累计统计。
lead(value_expr[,offset[,default]])
用于统计窗口内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)。
lag(value_expr[,offset[,default]])
与lead相反,用于统计窗口内往上第n行值。第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)。
first_value
取分组内排序后,截止到当前行,第一个值。
last_value
取分组内排序后,截止到当前行,最后一个值。
rank
对组中的数据进行排名,如果名次相同,则排名也相同,但是下一个名次的排名序号会出现不连续。比如查找具体条件的topN行。RANK() 排序为 (1,2,2,4)。
dense_rank
dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。当出现名次相同时,则排名序号也相同。而下一个排名的序号与上一个排名序号是连续的。
DENSE_RANK() 排序为 (1,2,2,3)。
SUM/AVG/MIN/MAX
数据:
id time pv
1 2015-04-10 1
1 2015-04-11 3
1 2015-04-12 6
1 2015-04-13 3
1 2015-04-14 2
2 2015-05-15 8
2 2015-05-16 6
结果:
SELECT id,
time,
pv,
SUM(pv) OVER(PARTITION BY id ORDER BY time) AS pv1, -- 默认为从起点到当前行
SUM(pv) OVER(PARTITION BY id ORDER BY time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS pv2, --从起点到当前行,结果同pv1
SUM(pv) OVER(PARTITION BY id) AS pv3, --分组内所有行
SUM(pv) OVER(PARTITION BY id ORDER BY time ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS pv4, --当前行+往前3行
SUM(pv) OVER(PARTITION BY id ORDER BY time ROWS BETWEEN 3 PRECEDING AND 1 FOLLOWING) AS pv5, --当前行+往前3行+往后1行
SUM(pv) OVER(PARTITION BY id ORDER BY time ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS pv6 ---当前行+往后所有行
FROM data;
NTILE
NTILE(n),用于将分组数据按照顺序切分成n片,返回当前切片值。
NTILE不支持ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)。
如果切片不均匀,默认增加第一个切片的分布。
ROW_NUMBER
从1开始,按照顺序,生成分组内记录的序列。
比如,按照pv降序排列,生成分组内每天的pv名次
ROW_NUMBER() 的应用场景非常多,比如获取分组内排序第一的记录。
「PDF」就可以看到阿里云盘下载链接了!

Hi,我是王知无,一个大数据领域的原创作者。 放心关注我,获取更多行业的一手消息。
