
【Spark重点难点】SparkSQL YYDS(上)!
本文已经加入「大数据成神之路PDF版」中提供下载,你可以关注公众号,后台回复:「PDF」即可获取。
《【Spark重点难点01】你从未深入理解的RDD和关键角色》 《【Spark重点难点02】你以为的Shuffle和真正的Shuffle》 《【Spark重点难点03】你的数据存在哪了?》 《【Spark重点难点04】你的代码跑起来谁说了算?(内存管理)》
DataFrame来源
注意:所谓的高阶函数指的是,指的是形参为函数的函数,或是返回类型为函数的函数。
> 例如:我们在WordCount程序中调用flatMap算子:
lineRDD.flatMap(line => line.split(" "))
flatMap的入参其实是一个函数。
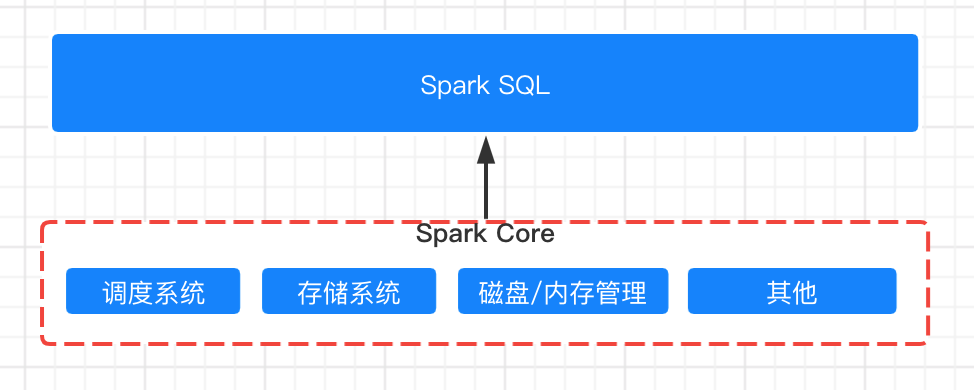
Spark Core和Spark SQL的关系
DataFrame的创建方式
createDataFrame & toDF
createDataFrame方法
import org.apache.spark.sql.types._
val schema = StructType(List(
StructField("name", StringType, nullable = false),
StructField("age", IntegerType, nullable = false),
StructField("birthday", DateType, nullable = false)
))
val rdd = spark.sparkContext.parallelize(Seq(
Row("小明", 18, java.sql.Date.valueOf("1990-01-01")),
Row("小芳", 20, java.sql.Date.valueOf("1999-02-01"))
))
val df = spark.createDataFrame(rdd, schema)
df.show()
RDD[Row],其中的 Row 是 org.apache.spark.sql.Row,因此,对于类型为 RDD[(String, Int)]的 rdd,我们需要把它转换为RDD[Row]。df.show()函数可以将数据进行输出:+--------------+-------------+-----------+
|name |age |birthday |
+--------------+-------------+-----------+
|小明 | 18| 1990-01-01|
|小芳 | 20| 1999-02-01|
+--------------+-------------+-----------+
toDF方法
import spark.implicits._
val df = Seq(
("小明", 18, java.sql.Date.valueOf("1990-01-01")),
("小芳", 20, java.sql.Date.valueOf("1999-02-01"))
).toDF("name", "age", "birthday")
df.show()
+--------------+-------------+-----------+
|name |age |birthday |
+--------------+-------------+-----------+
|小明 | 18| 1990-01-01|
|小芳 | 20| 1999-02-01|
+--------------+-------------+-----------+
val rdd = spark.sparkContext.parallelize(List(1,2,3,4,5))
val df = rdd.map(x=>(x,x^2)).toDF("a","b")
df.show()
通过文件系统创建DataFrame
https://docs.databricks.com/data/data-sources/index.html

小明,18
小芳,20
val spark = SparkSession.builder()
.appName("csv reader")
.master("local")
.getOrCreate()
val result = spark.read.format("csv")
.option("delimiter", ",")
.option("header", "true")
.option("nullValue", "\\N")
.option("inferSchema", "true")
.load("path/demo.csv")
result.show()
result.printSchema()
通过其他数据源创建DataFrame
val url = "jdbc:mysql://localhost:3306/test"
val df = spark.read
.format("jdbc")
.option("url", url)
.option("dbtable", "test")
.option("user", "admin")
.option("password", "admin")
.load()
df.show()
+---+----+----+
| id|user|age|
+---+----+----+
| 1| 小明| 18|
| 2| 小芳| 20|
+---+----+----+
常用语法和算子
https://spark.apache.org/docs/3.2.0/api/sql/index.html
单行查询
var userDF = List((1, "张三", true, 18, 15000, 1))
.toDF("id", "name", "sex", "age", "salary", "dept")
userDF.createTempView("t_employee")
val sql = "select * from t_employee where name = '张三'"
spark.sql(sql).show()
分组查询
var userDF= List( (1,"张三",true,18,15000,1),
(2,"李四",false,18,12000,1),
(3,"王五",false,18,16000,2)
) .toDF("id","name","sex","age","salary","dept")
//构建视图
userDF.createTempView("t_employee")
val sql=
"""
|select dept ,avg(salary) as avg_slalary from t_employee
|group by dept order by avg_slalary desc
""".stripMargin
spark.sql(sql).show()
+----+-----------+
|dept|avg_slalary|
+----+-----------+
| 2| 16000.0|
| 1| 13500.0|
+----+-----------+
开窗函数
// 开窗函数
var df=List(
(1,"zs",true,1,15000),
(2,"ls",false,2,18000),
(3,"ww",false,2,14000),
(4,"zl",false,1,18000),
(5,"win7",false,1,16000)
).toDF("id","name","sex","dept","salary")
df.createTempView("t_employee")
val sql=
"""
|select id,name,salary,dept,
|count(id) over(partition by dept order by salary desc) as rank,
|(count(id) over(partition by dept order by salary desc rows between current row and unbounded following) - 1) as low_than_me,
|avg(salary) over(partition by dept rows between unbounded preceding and unbounded following) as avg_salary,
|avg(salary) over() as all_avg_salary
|from t_employee t1 order by dept desc
""".stripMargin
spark.sql(sql).show()
https://mask0407.blog.csdn.net/article/details/106716575
总结

 我们点开一个文件夹后:
我们点开一个文件夹后:
Hi,我是王知无,一个大数据领域的原创作者。 放心关注我,获取更多行业的一手消息。

评论