
DataFrame,SparkSQL
小编推荐
来源:子雨大数据
http://dblab.xmu.edu.cn/blog
【版权声明】博客内容由厦门大学数据库实验室拥有版权,未经允许,请勿转载!
内容:运行原理,RDD设计,DAG,安装与使用
第4章 DataFrame,SparkSQL
4.1 Spark SQL简介 http://dblab.xmu.edu.cn/blog/1717-2/
(1)、从Shark说起
Shark的设计导致了两个问题:
一是执行计划优化完全依赖于Hive,不方便添加新的优化策略;
二是因为Spark是线程级并行,而MapReduce是进程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的打了补丁的Hive源码分支。
(2)、Spark SQL设计
Spark SQL的架构如图16-12所示,在Shark原有的架构上重写了逻辑执行计划的优化部分,解决了Shark存在的问题。Spark SQL在Hive兼容层面仅依赖HiveQL解析和Hive元数据,也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责。
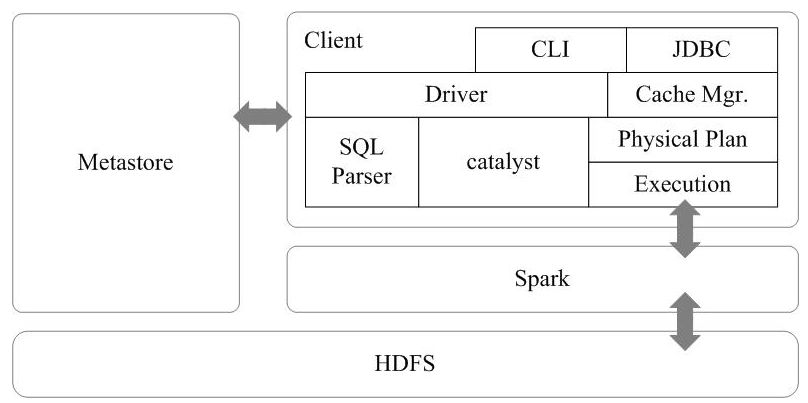
Spark SQL增加了SchemaRDD(即带有Schema信息的RDD),使用户可以在Spark SQL中执行SQL语句,数据既可以来自RDD,也可以来自Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据。Spark SQL目前支持Scala、Java、Python三种语言,支持SQL-92规范。从Spark1.2 升级到Spark1.3以后,Spark SQL中的SchemaRDD变为了DataFrame,DataFrame相对于SchemaRDD有了较大改变,同时提供了更多好用且方便的API,如图16-13所示。
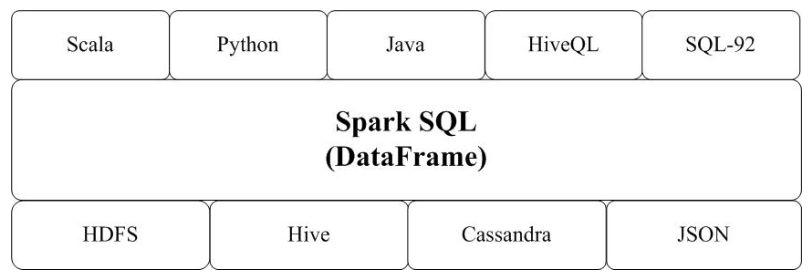
Spark SQL可以很好地支持SQL查询,一方面,可以编写Spark应用程序使用SQL语句进行数据查询,另一方面,也可以使用标准的数据库连接器(比如JDBC或ODBC)连接Spark进行SQL查询,这样,一些市场上现有的商业智能工具(比如Tableau)就可以很好地和Spark SQL组合起来使用,从而使得这些外部工具借助于Spark SQL也能获得大规模数据的处理分析能力。
4.2 DataFrame与RDD的区别 http://dblab.xmu.edu.cn/blog/1718-2/
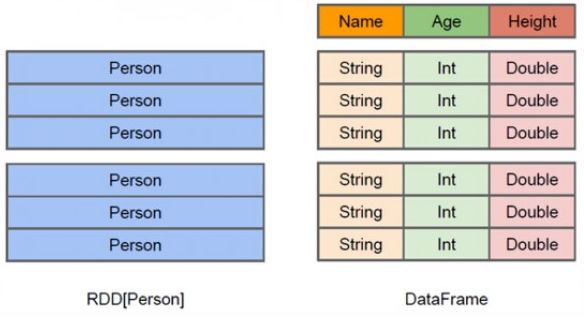
从上面的图中可以看出DataFrame和RDD的区别:
(1)RDD是分布式的 Java对象的集合,比如,RDD[Person]是以Person为类型参数,但是,Person类的内部结构对于RDD而言却是不可知的。
(2)DataFrame是一种以RDD为基础的分布式数据集,也就是分布式的Row对象的集合(每个Row对象代表一行记录),提供了详细的结构信息,也就是我们经常说的模式(schema),Spark SQL可以清楚地知道该数据集中包含哪些列、每列的名称和类型。
和RDD一样,DataFrame的各种变换操作也采用惰性机制,只是记录了各种转换的逻辑转换路线图(是一个DAG图),不会发生真正的计算,这个DAG图相当于一个逻辑查询计划,最终,会被翻译成物理查询计划,生成RDD DAG,按照之前介绍的RDD DAG的执行方式去完成最终的计算得到结果。
4.3 DataFrame的创建 http://dblab.xmu.edu.cn/blog/1719-2/
首先,请找到样例数据。 Spark已经为我们提供了几个样例数据,就保存在“主目录/resources/”这个目录下,这个目录下有两个样例数据people.json和people.txt。
people.json文件的内容如下:
{"name":"Michael"}{"name":"Andy", "age":30}{"name":"Justin", "age":19}
people.txt文件的内容如下:
Michael, 29Andy, 30Justin, 19
下面我们就介绍如何从people.json文件中读取数据并生成DataFrame并显示数据(从people.txt文件生成DataFrame需要后面将要介绍的另外一种方式)。
(1)、 引入 pyspark 库
# 引入 pyspark 库from pyspark.sql import SparkSession
(2)、SparkSession 导入数据
spark=SparkSession.builder.getOrCreate()df = spark.read.json("../resources/people.json")df.show()
+----+-------+| age| name|+----+-------+|null|Michael|| 30| Andy|| 19| Justin|+----+-------+
(3)、SparkSession 常用操作介绍
# 打印模式信息df.printSchema()
root|-- age: long (nullable = true)|-- name: string (nullable = true)
# 选择多列,并对 age+1df.select(df.name,df.age + 1).show()
+-------+---------+| name|(age + 1)|+-------+---------+|Michael| null|| Andy| 31|| Justin| 20|+-------+---------+
# 条件过滤,筛选出 age > 20 的数据df.filter(df.age > 20 ).show()
+---+----+|age|name|+---+----+| 30|Andy|+---+----+
# 分组聚合,分组统计df.groupBy("age").count().show()
+----+-----+| age|count|+----+-----+| 19| 1||null| 1|| 30| 1|+----+-----+
# 分组聚合,分组求和df.groupBy("age").sum().show()
+----+--------+| age|sum(age)|+----+--------+| 19| 19||null| null|| 30| 30|+----+--------+
# 排序## 递降df.sort(df.age.desc()).show()## 递增df.sort(df.age.asc()).show()
+----+-------+| age| name|+----+-------+| 30| Andy|| 19| Justin||null|Michael|+----+-------++----+-------+| age| name|+----+-------+|null|Michael|| 19| Justin|| 30| Andy|+----+-------+
#多列排序df.sort(df.age.desc(), df.name.asc()).show()
+----+-------+| age| name|+----+-------+| 30| Andy|| 19| Justin||null|Michael|+----+-------+
#对列进行重命名df.select(df.name.alias("username"),df.age).show()
+--------+----+|username| age|+--------+----+| Michael|null|| Andy| 30|| Justin| 19|+--------+----+
4.4 从RDD转换得到DataFrame http://dblab.xmu.edu.cn/blog/1720-2/
Spark官网提供了两种方法来实现从RDD转换得到DataFrame:
第一种方法是,利用反射来推断包含特定类型对象的RDD的schema,适用对已知数据结构的RDD转换;
第二种方法是,使用编程接口,构造一个schema并将其应用在已知的RDD上。
from pyspark.sql.types import Rowfrom pyspark import SparkContextsc = SparkContext( 'local', 'test')
from pyspark.sql import SparkSessionspark = SparkSession(sc)
def f(x):rel = {}rel['name'] = x[0]rel['age'] = x[1]return relpeopleRDD = sc.textFile("../resources/people.txt").map(lambda line : line.split(',')).map(lambda x: Row(**f(x)))peopleDF = peopleRDD.toDF()
peopleDF.createOrReplaceTempView("people") #必须注册为临时表才能供下面的查询使用personsDF = spark.sql("select * from people")personsDF.show()personsDF.rdd.map(lambda t : "Name:"+t[0]+","+"Age:"+t[1]).collect()
+---+-------+|age| name|+---+-------+| 29|Michael|| 30| Andy|| 19| Justin|+---+-------+['Name: 29,Age:Michael', 'Name: 30,Age:Andy', 'Name: 19,Age:Justin']
(2)、使用编程方式定义RDD模式
使用createDataFrame(rdd, schema)编程方式定义RDD模式。
from pyspark.sql.types import Rowfrom pyspark.sql.types import StructTypefrom pyspark.sql.types import StructFieldfrom pyspark.sql.types import StringTypefrom pyspark import SparkContextsc = SparkContext( 'local', 'test')from pyspark.sql import SparkSessionspark = SparkSession(sc)
# 生成 RDDpeopleRDD = sc.textFile("../resources/people.txt")# 定义一个模式字符串schemaString = "name age"# 根据模式字符串生成模式fields = list(map( lambda fieldName : StructField(fieldName, StringType(), nullable = True), schemaString.split(" ")))schema = StructType(fields)# 从上面信息可以看出,schema描述了模式信息,模式中包含name和age两个字段
rowRDD = peopleRDD.map(lambda line : line.split(',')).map(lambda attributes : Row(attributes[0], attributes[1]))在上面的代码中,peopleRDD.map(lambda line : line.split(‘,’))作用是对people这个RDD中的每一行元素都进行解析。比如,people这个RDD的第一行是:
Michael, 29peopleDF = spark.createDataFrame(rowRDD, schema)# 必须注册为临时表才能供下面查询使用peopleDF.createOrReplaceTempView("people")
results = spark.sql("SELECT * FROM people")results.rdd.map( lambda attributes : "name: " + attributes[0]+","+"age:"+attributes[1]).collect()
['name: Michael,age: 29', 'name: Andy,age: 30', 'name: Justin,age: 19']这行内容经过peopleRDD.map(lambda line : line.split(‘,’)).操作后,就得到一个集合{Michael,29}。后面经过map(lambda attributes : Row(attributes[0], attributes[1]))操作时,这时的p就是这个集合{Michael,29},这时p[0]就是Micheael,p[1]就是29,map(lambda attributes : Row(attributes[0], attributes[1]))就会生成一个Row对象,这个对象里面包含了两个字段的值,这个Row对象就构成了rowRDD中的其中一个元素。因为people有3行文本,所以,最终,rowRDD中会包含3个元素,每个元素都是org.apache.spark.sql.Row类型。实际上,Row对象只是对基本数据类型(比如整型或字符串)的数组的封装,本质就是一个定长的字段数组。 peopleDF = spark.createDataFrame(rowRDD, schema),这条语句就相当于建立了rowRDD数据集和模式之间的对应关系,从而我们就知道对于rowRDD的每行记录,第一个字段的名称是schema中的“name”,第二个字段的名称是schema中的“age”。
(3)、把RDD保存成文件
这里介绍如何把RDD保存成文本文件,后面还会介绍其他格式的保存。
1) 第一种保存方式
peopleDF = spark.read.format("json").load("../resources/people.json")peopleDF.select("name", "age").write.format("csv").save("../resources/newpeople.csv")
可以看出,这里使用select(“name”, “age”)确定要把哪些列进行保存,然后调用write.format(“csv”).save ()保存成csv文件。在后面小节中,我们还会介绍其他保存方式。
另外,write.format()支持输出 json,parquet, jdbc, orc, libsvm, csv, text等格式文件,如果要输出文本文件,可以采用write.format(“text”),但是,需要注意,只有select()中只存在一个列时,才允许保存成文本文件,如果存在两个列,比如select(“name”, “age”),就不能保存成文本文件。
可以看到 resources 这个目录下面有个newpeople.csv文件夹(注意,不是文件),这个文件夹中包含下面两个文件:
part-r-00000-33184449-cb15-454c-a30f-9bb43faccac1.csv
_SUCCESS不用理会_SUCCESS这个文件,只要看一下part-r-00000-33184449-cb15-454c-a30f-9bb43faccac1.csv这个文件,可以用vim编辑器打开这个文件查看它的内容,该文件内容如下:
Michael,
Andy,30
Justin,19因为people.json文件中,Michael这个名字不存在对应的age,所以,上面第一行逗号后面没有内容。
如果我们要再次把newpeople.csv中的数据加载到RDD中,可以直接使用newpeople.csv目录名称,而不需要使用part-r-00000-33184449-cb15-454c-a30f-9bb43faccac1.csv 文件,如下:
textFile = sc.textFile("../resources/newpeople.csv")textFile.collect()
['Michael,""', 'Andy,30', 'Justin,19']2) 第二种保存方式
进入pyspark执行下面命令:
peopleDF = spark.read.format("json").load("../resources/people.json")peopleDF.rdd.saveAsTextFile("../resources/newpeople.txt")
可以看出,我们是把DataFrame转换成RDD,然后调用saveAsTextFile()保存成文本文件。在后面小节中,我们还会介绍其他保存方式。
可以看到 resources 这个目录下面有个 newpeople.txt 文件夹(注意,不是文件),这个文件夹中包含下面两个文件:
part-00000
_SUCCESS不用理会_SUCCESS这个文件,只要看一下part-00000这个文件,可以用vim编辑器打开这个文件查看它的内容,该文件内容如下:
[null,Michael]
[30,Andy]
[19,Justin]如果我们要再次把newpeople.txt中的数据加载到RDD中,可以直接使用newpeople.txt目录名称,而不需要使用part-00000文件,如下:
textFile = sc.textFile("../resources/newpeople.txt")textFile.collect()
["Row(age=None, name='Michael')","Row(age=30, name='Andy')","Row(age=19, name='Justin')"]