
并发容器详解,深入底层的透彻剖析
点击上方 Java学习之道,选择 设为星标
来源: cnblogs.com/lijizhi/p/13360827.html
作者: 2JZ
Part1HashMap、ConcurrentHashMap
HashMap常见的不安全问题及原因
非原子操作
++ modCount 等非原子操作存在且没有任何加锁机制会导致线程不安全问题;
扩容取值
扩容期间会创建新的table在数据转储期间,可能会有取到null的可能;
碰撞丢失
多线程情况下,若同时对一个bucket 进行put操作可能会出现覆盖情况;
可见性问题
HashMap中没有可见性volatile关键字修饰,多线程情况下不能保证可见性;
死循环
JDK1.7 扩容期间,头插法也可能导致出现循环链表,即NodeA.next = NodeB ; NodeB.next = NodeA 在取值时则会发生死循环;
ConcurrentHashMap在JDK1.8中的升级
Java 7 版本的 ConcurrentHashMap
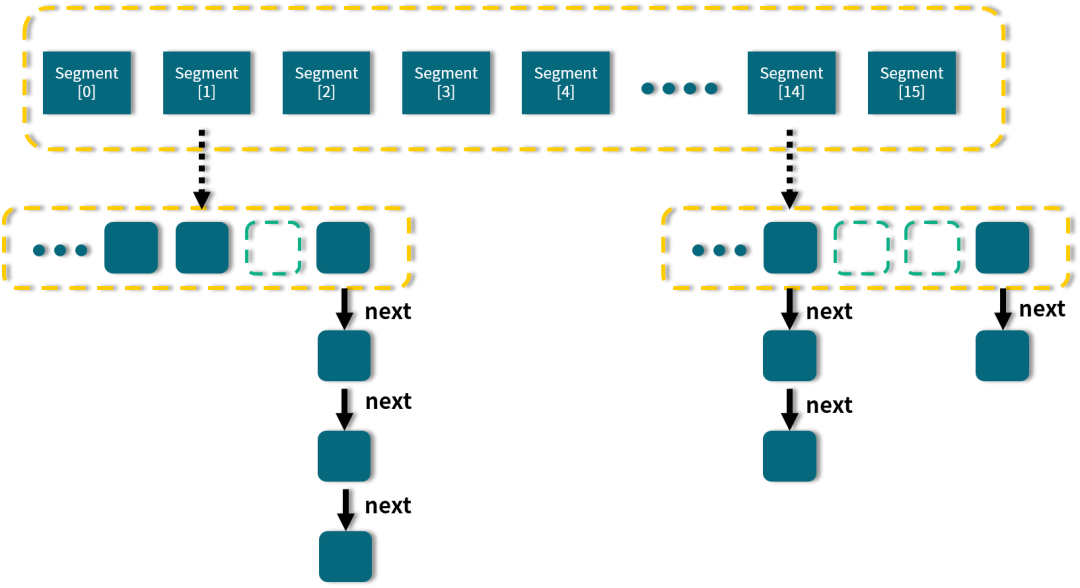
从图中我们可以看出,在 ConcurrentHashMap 内部进行了 Segment 分段,Segment 继承了 ReentrantLock,可以理解为一把锁,各个 Segment 之间都是相互独立上锁的,互不影响分段锁。相比于之前的 Hashtable 每次操作都需要把整个对象锁住而言,大大提高了并发效率。因为它的锁与锁之间是独立的,而不是整个对象只有一把锁。
每个 Segment 的底层数据结构与 HashMap 类似的HashEntry(所以1.7中的put操作需要进行两次Hash,先找到Segment再找到HashEntry,并使用 tryLock + 自旋的方式尝试插入数据),仍然是数组和链表组成的拉链法结构。默认有 0~15 共 16 个 Segment,所以最多可以同时支持 16 个线程并发操作(操作分别分布在不同的 Segment 上)。16 这个默认值可以在初始化的时候设置为其他值,但是一旦确认初始化以后,是不可以扩容的。
获取Map的size时,依次执行两种方案,尝试不加锁获取两次,若不变则说明size准确;否则执行方案二 加锁情况下直接获取size;
Java 8 版本的 ConcurrentHashMap
在 Java 8 中,几乎完全重写了 ConcurrentHashMap,代码量从原来 Java 7 中的 1000 多行,变成了现在的 6000 多行,取消了Segment,使用 Node [] + 链表 + 红黑树,放弃了ReentrantLock的使用采用了`Synchronized + CAS + volatile(Node 的 value属性) 锁机制能适应更高的并发和更高效的锁机制,也依赖于Java团队对Synchronized锁的优化。
获取Map的size时,sumCount函数在每次操作时已经记录好了,所以直接返回;但既然是高并发容器,size并没有多大意义,瞬时值;
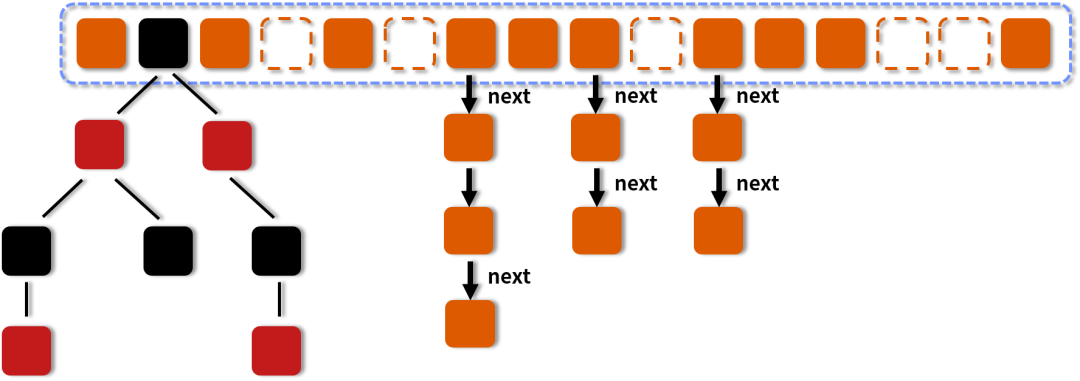
图中的节点有三种类型。
第一种是最简单的,空着的位置代表当前还没有元素来填充。第二种就是和 HashMap 非常类似的拉链法结构,在每一个槽中会首先填入第一个节点,但是后续如果计算出相同的 Hash 值,就用链表的形式往后进行延伸。第三种结构就是红黑树结构,这是 Java 7 的 ConcurrentHashMap 中所没有的结构,在此之前我们可能也很少接触这样的数据结构。当第二种情况的链表长度大于某一个阈值(默认为 8),且同时满足一定的容量要求的时候,ConcurrentHashMap 便会把这个链表从链表的形式转化为红黑树的形式,目的是进一步提高它的查找性能。所以,Java 8 的一个重要变化就是引入了红黑树的设计,由于红黑树并不是一种常见的数据结构,所以我们在此简要介绍一下红黑树的特点。
红黑树是每个节点都带有颜色属性的自平衡的二叉查找树,颜色为红色或黑色,红黑树的本质是对二叉查找树 BST 的一种平衡策略,我们可以理解为是一种平衡二叉查找树,查找效率高,会自动平衡,防止极端不平衡从而影响查找效率的情况发生。
由于自平衡的特点,即左右子树高度几乎一致,所以其查找性能近似于二分查找,时间复杂度是 O(log(n)) 级别;反观链表,它的时间复杂度就不一样了,如果发生了最坏的情况,可能需要遍历整个链表才能找到目标元素,时间复杂度为 O(n),远远大于红黑树的 O(log(n)),尤其是在节点越来越多的情况下,O(log(n)) 体现出的优势会更加明显。
红黑树的一些其他特点:
每个节点要么是红色,要么是黑色,但根节点永远是黑色的。
红色节点不能连续,也就是说,红色节点的子和父都不能是红色的。
从任一节点到其每个叶子节点的路径都包含相同数量的黑色节点。
正是由于这些规则和要求的限制,红黑树保证了较高的查找效率,所以现在就可以理解为什么 Java 8 的 ConcurrentHashMap 要引入红黑树了。好处就是避免在极端的情况下冲突链表变得很长,在查询的时候,效率会非常慢。而红黑树具有自平衡的特点,所以,即便是极端情况下,也可以保证查询效率在 O(log(n))。
事实上,链表长度超过 8 就转为红黑树的设计,更多的是为了防止用户自己实现了不好的哈希算法时导致链表过长,从而导致查询效率低,而此时转为红黑树更多的是一种保底策略,用来保证极端情况下查询的效率。
通常如果 hash 算法正常的话,那么链表的长度也不会很长,那么红黑树也不会带来明显的查询时间上的优势,反而会增加空间负担。所以通常情况下,并没有必要转为红黑树,所以就选择了概率非常小,小于千万分之一概率,也就是长度为 8 的概率,把长度 8 作为转化的默认阈值。
所以如果平时开发中发现 HashMap 或是 ConcurrentHashMap 内部出现了红黑树的结构,这个时候往往就说明我们的哈希算法出了问题,需要留意是不是我们实现了效果不好的 hashCode 方法,并对此进行改进,以便减少冲突。
源码分析
putVal方法,关键词:CAS、helpTransfer、synchronized、addCount
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) {
throw new NullPointerException();
}
//计算 hash 值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K, V>[] tab = table; ; ) {
Node<K, V> f;
int n, i, fh;
//如果数组是空的,就进行初始化
if (tab == null || (n = tab.length) == 0) {
tab = initTable();
}
// 找该 hash 值对应的数组下标
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//如果该位置是空的,就用 CAS 的方式放入新值
if (casTabAt(tab, i, null,
new Node<K, V>(hash, key, value, null))) {
break;
}
}
//hash值等于 MOVED 代表在扩容
else if ((fh = f.hash) == MOVED) {
tab = helpTransfer(tab, f);
}
//槽点上是有值的情况
else {
V oldVal = null;
//用 synchronized 锁住当前槽点,保证并发安全
synchronized (f) {
if (tabAt(tab, i) == f) {
//如果是链表的形式
if (fh >= 0) {
binCount = 1;
//遍历链表
for (Node<K, V> e = f; ; ++binCount) {
K ek;
//如果发现该 key 已存在,就判断是否需要进行覆盖,然后返回
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent) {
e.val = value;
}
break;
}
Node<K, V> pred = e;
//到了链表的尾部也没有发现该 key,说明之前不存在,就把新值添加到链表的最后
if ((e = e.next) == null) {
pred.next = new Node<K, V>(hash, key,
value, null);
break;
}
}
}
//如果是红黑树的形式
else if (f instanceof TreeBin) {
Node<K, V> p;
binCount = 2;
//调用 putTreeVal 方法往红黑树里增加数据
if ((p = ((TreeBin<K, V>) f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent) {
p.val = value;
}
}
}
}
}
if (binCount != 0) {
//检查是否满足条件并把链表转换为红黑树的形式,默认的 TREEIFY_THRESHOLD 阈值是 8
if (binCount >= TREEIFY_THRESHOLD) {
treeifyBin(tab, i);
}
//putVal 的返回是添加前的旧值,所以返回 oldVal
if (oldVal != null) {
return oldVal;
}
break;
}
}
}
addCount(1L, binCount);
return null;
}
putVal方法中会逐步根据当前槽点是未初始化、空、扩容、链表、红黑树等不同情况做出不同的处理。当第一次put 会对数组进行初始化,bucket为空则CAS操作赋值,不为空则判断是链表还是红黑树进行赋值操作,若此时数组正在扩容则调用helpTransfer进行多线程并发扩容操作,最后返回oldValue 并对操作调用addCount记录(size相关);
getVal源码分析
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
//计算 hash 值
int h = spread(key.hashCode());
//如果整个数组是空的,或者当前槽点的数据是空的,说明 key 对应的 value 不存在,直接返回 null
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
//判断头结点是否就是我们需要的节点,如果是则直接返回
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//如果头结点 hash 值小于 0,说明是红黑树或者正在扩容,就用对应的 find 方法来查找
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
//遍历链表来查找
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
get过程:
计算 Hash 值,并由此值找到对应的bucket;
如果数组是空的或者该位置为 null,那么直接返回 null 就可以了;
如果该位置处的节点刚好就是我们需要的,直接返回该节点的值;
如果该位置节点是红黑树或者正在扩容,就用 find 方法继续查找;
否则那就是链表,就进行遍历链表查找。
总结
数据结构:Java 7 采用 Segment 分段锁来实现,而 Java 8 中的 ConcurrentHashMap 使用数组 + 链表 + 红黑树
并发度:Java 7 中,每个 Segment 独立加锁,最大并发个数就是 Segment 的个数,默认是 16。但是到了 Java 8 中,锁粒度更细,理想情况下 table 数组元素的个数(也就是数组长度)就是其支持并发的最大个数,并发度比之前有提高。
并发原理:Java 7 采用 Segment 分段锁来保证安全,而 Segment 是继承自 ReentrantLock。Java 8 中放弃了 Segment 的设计,采用 Node + CAS + synchronized 保证线程安全。
Hash碰撞:Java 7 在 Hash 冲突时,会使用拉链法,也就是链表的形式。Java 8 先使用拉链法,在链表长度超过一定阈值时,将链表转换为红黑树,来提高查找效率。
1CopyOnWriteArrayList / Set
其实在 CopyOnWriteArrayList 出现之前,我们已经有了 ArrayList 和 LinkedList 作为 List 的数组和链表的实现,而且也有了线程安全的 Vector 和 Collections.synchronizedList() 可以使用。
Vector和HashTable类似仅仅是对方法增加synchronized 上对象锁,并发效率比较低;并且,前面这几种 List 在迭代期间不允许编辑,如果在迭代期间进行添加或删除元素等操作,则会抛出 ConcurrentModificationException 异常,这样的特点也在很多情况下给使用者带来了麻烦。所以从 JDK1.5 开始,Java 并发包里提供了使用 CopyOnWrite 机制实现的并发容器 CopyOnWriteArrayList 作为主要的并发 List,CopyOnWrite 的并发集合还包括 CopyOnWriteArraySet,其底层正是利用 CopyOnWriteArrayList 实现的。所以今天我们以 CopyOnWriteArrayList 为突破口,来看一下 CopyOnWrite 容器的特点。
适用场景
读快写慢
在很多应用场景中,读操作可能会远远多于写操作。比如,有些系统级别的信息,往往只需要加载或者修改很少的次数,但是会被系统内所有模块频繁的访问。对于这种场景,我们最希望看到的就是读操作可以尽可能的快,而写即使慢一些也没关系。
读多写少
黑名单是最典型的场景,假如我们有一个搜索网站,用户在这个网站的搜索框中,输入关键字搜索内容,但是某些关键字不允许被搜索。这些不能被搜索的关键字会被放在一个黑名单中,黑名单并不需要实时更新,可能每天晚上更新一次就可以了。当用户搜索时,会检查当前关键字在不在黑名单中,如果在,则提示不能搜索。这种读多写少的场景也很适合使用 CopyOnWrite 集合。
读写规则
读写锁的规则
读写锁的思想是:读读共享、其他都互斥(写写互斥、读写互斥、写读互斥),原因是由于读操作不会修改原有的数据,因此并发读并不会有安全问题;而写操作是危险的,所以当写操作发生时,不允许有读操作加入,也不允许第二个写线程加入。
对读写锁规则的升级
CopyOnWriteArrayList 的思想比读写锁的思想又更进一步。为了将读取的性能发挥到极致,CopyOnWriteArrayList 读取是完全不用加锁的,更厉害的是,写入也不会阻塞读取操作,也就是说你可以在写入的同时进行读取,只有写入和写入之间需要进行同步,也就是不允许多个写入同时发生,但是在写入发生时允许读取同时发生。这样一来,读操作的性能就会大幅度提升。
特点
CopyOnWrite的含义
从 CopyOnWriteArrayList 的名字就能看出它是满足 CopyOnWrite 的 ArrayList,CopyOnWrite 的意思是说,当容器需要被修改的时候,不直接修改当前容器,而是先将当前容器进行 Copy,复制出一个新的容器 (和MySQL中的快照读机制类似),然后修改新的容器,完成修改之后,再将原容器的引用指向新的容器。这样就完成了整个修改过程。
这样做的好处是,CopyOnWriteArrayList 利用了“数组不变性”原理,因为容器每次修改都是创建新副本,所以对于旧容器来说,其实是不可变的,也是线程安全的,无需进一步的同步操作。我们可以对 CopyOnWrite 容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素,也不会有修改。
CopyOnWriteArrayList 的所有修改操作(add,set等)都是通过创建底层数组的新副本来实现的,所以 CopyOnWrite 容器也是一种读写分离的思想体现,读和写使用不同的容器。
迭代期间允许修改集合内容
我们知道 ArrayList 在迭代期间如果修改集合的内容,会抛出 ConcurrentModificationException 异常。让我们来分析一下 ArrayList 会抛出异常的原因。
在 ArrayList 源码里的 ListItr 的 next 方法中有一个 checkForComodification 方法,代码如下:
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
这里会首先检查 modCount 是否等于 expectedModCount。modCount 是保存修改次数,每次我们调用 add、remove 或 trimToSize 等方法时它会增加,expectedModCount 是迭代器的变量,当我们创建迭代器时会初始化并记录当时的 modCount。后面迭代期间如果发现 modCount 和 expectedModCount 不一致,就说明有人修改了集合的内容,就会抛出异常。而CopyOnWriteArrayList不会抛异常,参见源码分析COWIterator;
缺点
这些缺点不仅是针对 CopyOnWriteArrayList,其实同样也适用于其他的 CopyOnWrite 容器:
内存占用问题
因为 CopyOnWrite 的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,这一点会占用额外的内存空间。
在元素较多或者复杂的情况下,复制的开销很大
复制过程不仅会占用双倍内存,还需要消耗 CPU 等资源,会降低整体性能。
脏读问题
由于 CopyOnWrite 容器的修改是先修改副本,所以这次修改对于其他线程来说,并不是实时能看到的,只有在修改完之后才能体现出来。如果你希望写入的的数据马上能被其他线程看到,CopyOnWrite 容器是不适用的。
源码分析
数据结构
/** 可重入锁对象 */
final transient ReentrantLock lock = new ReentrantLock();
/** CopyOnWriteArrayList底层由数组实现,volatile修饰,保证数组的可见性 */
private transient volatile Object[] array;
/**
* 得到数组
*/
final Object[] getArray() {
return array;
}
/**
* 设置数组
*/
final void setArray(Object[] a) {
array = a;
}
/**
* 初始化CopyOnWriteArrayList相当于初始化数组
*/
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
`
(javascript:void(0); "复制代码")[](https://common.cnblogs.com/images/copycode.gif)
这个类中首先会有一个 ReentrantLock 锁,用来保证修改操作的线程安全。下面被命名为 array 的 Object[] 数组是被 volatile 修饰的,可以保证数组的可见性,这正是存储元素的数组,同样,我们可以从 getArray()、setArray 以及它的构造方法看出,CopyOnWriteArrayList 的底层正是利用数组实现的,这也符合它的名字。
add方法
(javascript:void(0); "复制代码")[](https://common.cnblogs.com/images/copycode.gif)
`
public boolean add(E e) {
// 加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 得到原数组的长度和元素
Object[] elements = getArray();
int len = elements.length;
// 复制出一个新数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 添加时,将新元素添加到新数组中
newElements[len] = e;
// 将volatile Object[] array 的指向替换成新数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
上面的步骤实现了 CopyOnWrite 的思想:写操作是在原来容器的拷贝上进行的,并且在读取数据的时候不会锁住 list。而且可以看到,如果对容器拷贝操作的过程中有新的读线程进来,那么读到的还是旧的数据,因为在那个时候对象的引用还没有被更改。
get方法
public E get(int index) {
return get(getArray(), index);
}
final Object[] getArray() {
return array;
}
private E get(Object[] a, int index) {
return (E) a[index];
}
get方法十分普通,没有任何锁相关内容,主要是保证读取效率;
迭代器 COWIterator 类
这个迭代器有两个重要的属性,分别是 Object[] snapshot 和 int cursor。其中 snapshot 代表数组的快照,也就是创建迭代器那个时刻的数组情况,而 cursor 则是迭代器的游标。迭代器的构造方法如下:
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
可以看出,迭代器在被构建的时候,会把当时的 elements 赋值给 snapshot,而之后的迭代器所有的操作都基于 snapshot 数组进行的,比如:
public E next() {
if (! hasNext())
throw new NoSuchElementException();
return (E) snapshot[cursor++];
}
在 next 方法中可以看到,返回的内容是 snapshot 对象,所以,后续就算原数组被修改,这个 snapshot 既不会感知到,也不会影响执行;
送书活动
首先,感谢北京大学出版社为 "Java学习之道" 提供的书籍赞助,非常感谢!后续公众号头条推文,1周至少会有1-2次的文末送书活动,大家记得看完文章后,多多参与送书哈,混脸熟也能中奖!
《Python网络爬虫开发从入门到精通》
《Python网络爬虫开发从入门到精通》坚持以实例为主,理论为辅的路线,从 Python 基础、爬虫开发常用网络请求库,到爬虫框架使用和分布式爬虫设计,以及最后的数据存储、分析、实战训练等,覆盖了爬虫项目开发阶段的整个生命周期。
可点击下方链接直接购买
免费获取方法:
6月16日前,公众号后台回复 【 java学习 】即可参与活动!!!
▲扫码回复「java学习」抽奖品
没加小编微信的建议先加一下小编微信,方便中奖之后安排发货和领

