
深入剖析MobileNet和它的变种
最近在看轻量级网络的东西,发现这篇总结的非常的好,因此就翻译过来!总结各种变种,同时原理图非常的清晰,希望能给大家一些启发,如果觉得不错欢迎三连哈!
Introduction
在本文中,我概述了高效CNN模型(如MobileNet及其变体)中使用的组成部分(building blocks),并解释了它们如此高效的原因。特别地,我提供了关于如何在空间和通道域进行卷积的直观说明。
在高效的模型中使用的组成部分
在解释具体的高效CNN模型之前,我们先检查一下高效CNN模型中使用的组成部分的计算量,看看卷积在空间和通道域中是如何进行的。
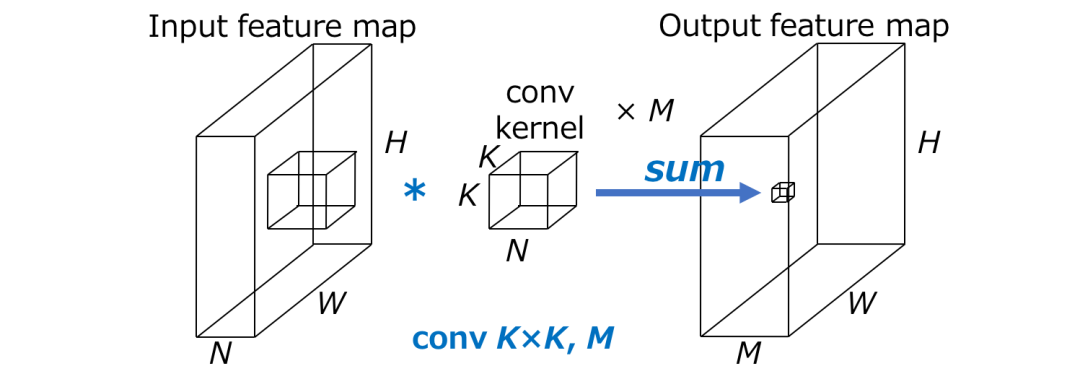
假设 H x W 为输出feature map的空间大小,N为输入通道数,K x K为卷积核的大小,M为输出通道数,则标准卷积的计算量为 HWNK²M 。
这里重要的一点是,标准卷积的计算量与(1)输出特征图H x W的空间大小,(2)卷积核K的大小,(3)输入输出通道的数量N x M成正比。
当在空间域和通道域进行卷积时,需要上述计算量。通过分解这个卷积,可以加速 CNNs,如下图所示。
卷积
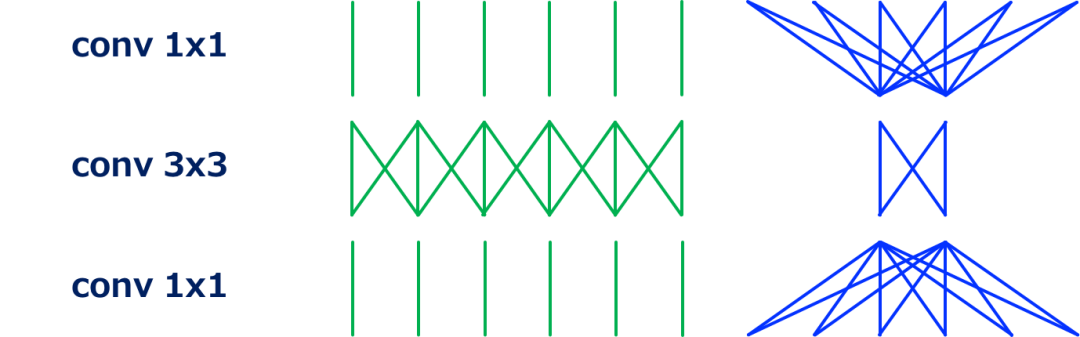
首先,我提供了一个直观的解释,关于空间和通道域的卷积是如何对进行标准卷积的,它的计算量是HWNK²M 。
我连接输入和输出之间的线,以可视化输入和输出之间的依赖关系。直线数量大致表示空间和通道域中卷积的计算量。

例如,最常用的卷积——conv3x3,可以如上图所示。我们可以看到,输入和输出在空间域是局部连接的,而在通道域是全连接的。

接下来,如上所示用于改变通道数的conv1x1,或pointwise convolution。由于kernel的大小是1x1,所以这个卷积的计算代价是 HWNM,计算量比conv3x3降低了1/9。这种卷积被用来“混合”通道之间的信息。
分组卷积(Grouped Convolution)
分组卷积是卷积的一种变体,将输入的feature map的通道分组,对每个分组的通道独立地进行卷积。
假设 G 表示组数,分组卷积的计算量为 HWNK²M/G,计算量变成标准卷积的1/G。

在conv3x3 而且 G=2的情况。我们可以看到,通道域中的连接数比标准卷积要小,说明计算量更小。

在 conv3x3,G=3的情况下,连接变得更加稀疏。

在 conv1x1,G=2的情况下,conv1x1也可以被分组。这种类型的卷积被用于ShuffleNet中。

在 conv1x1,G=3的情况.
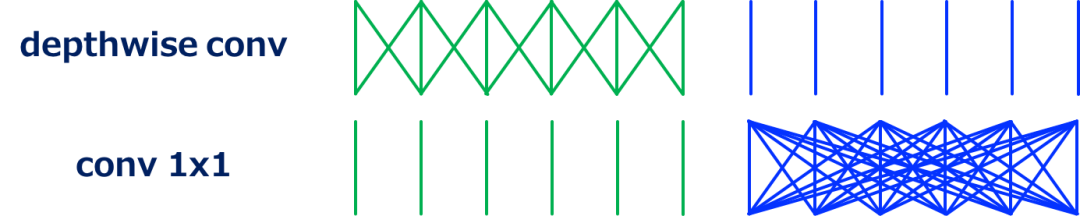
深度可分离卷积(Depthwise Convolution)
在深度卷积中,对每个输入通道分别进行卷积。它也可以定义为分组卷积的一种特殊情况,其中输入和输出通道数相同,G等于通道数。

如上所示,depthwise convolution 通过省略通道域中的卷积,大大降低了计算量。
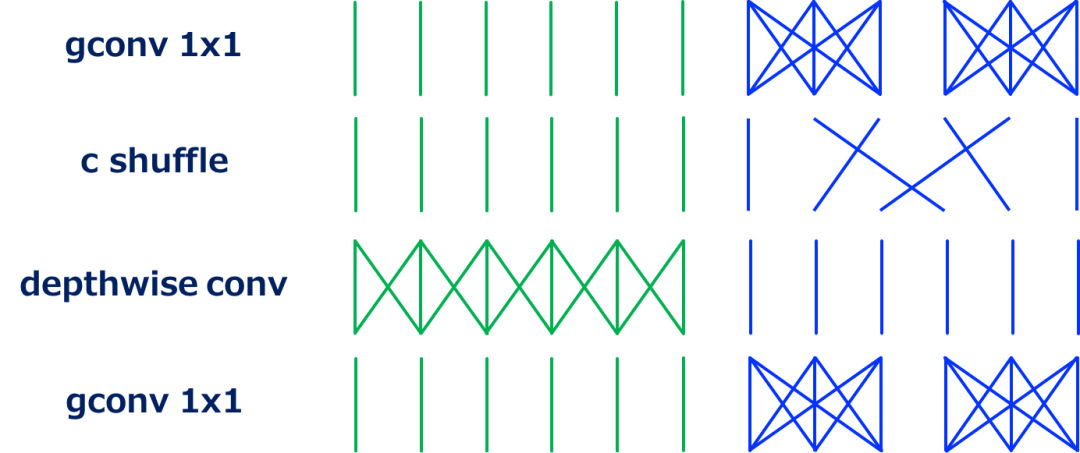
Channel Shuffle
Channel shuffle是一种操作(层),它改变 ShuffleNet 中使用的通道的顺序。这个操作是通过张量reshape和 transpose 来实现的。
更准确地说,让GN ' (=N) 表示输入通道的数量,首先将输入通道的维数reshape 为(G, N '),然后将(G, N ')转置为(N ', G),最后将其flatten 成与输入相同的形状。这里G表示分组卷积的组数,在ShuffleNet中与channel shuffle层一起使用。
虽然ShuffleNet的计算代价不能用乘加操作(MACs)的数量来定义,但应该有一些开销。

G=2时的channel shuffle 情况。卷积不执行,只是改变了通道的顺序。

这种情况下打乱的通道数 G=3
Efficient Models
下面,对于高效的CNN模型,我将直观地说明为什么它们是高效的,以及如何在空间和通道域进行卷积。
ResNet (Bottleneck Version)
ResNet 中使用的带有bottleneck 架构的残差单元是与其他模型进行进一步比较的良好起点。
如上所示,具有bottleneck架构的残差单元由conv1x1、conv3x3、conv1x1组成。第一个conv1x1减小了输入通道的维数,降低了随后的conv3x3的计算量。最后的conv1x1恢复输出通道的维数。
ResNeXt
ResNeXt是一个高效的CNN模型,可以看作是ResNet的一个特例,将conv3x3替换为成组的conv3x3。通过使用有效的分组conv,与ResNet相比,conv1x1的通道减少率变得适中,从而在相同的计算代价下获得更好的精度。

MobileNet (Separable Conv)
MobileNet是一个可分离卷积模块的堆叠,由depthwise conv和conv1x1 (pointwise conv)组成。
可分离卷积在空间域和通道域独立执行卷积。这种卷积分解显著降低了计算量,从 HWNK²M 降低到HWNK² (depthwise) + HWNM (conv1x1), HWN(K² + M) 。一般情况下,M>>K(如K=3和M≥32),减小率约为1/8-1/9。
这里重要的一点是,计算量的bottleneck现在是conv1x1!
ShuffleNet
ShuffleNet的动机是如上所述,conv1x1是可分离卷积的瓶颈。虽然conv1x1已经是有效的,似乎没有改进的空间,分组conv1x1可以用于此目的!
上图说明了用于ShuffleNet的模块。这里重要的building block是channel shuffle层,它在分组卷积中对通多在组间的顺序进行“shuffles”。如果没有channel shuffle,分组卷积的输出在组之间就不会被利用,导致精度下降。
MobileNet-v2
MobileNet-v2采用类似ResNet中带有bottleneck架构残差单元的模块架构;用深度可分离卷积(depthwise convolution)代替conv3x3,是残差单元的改进版本。
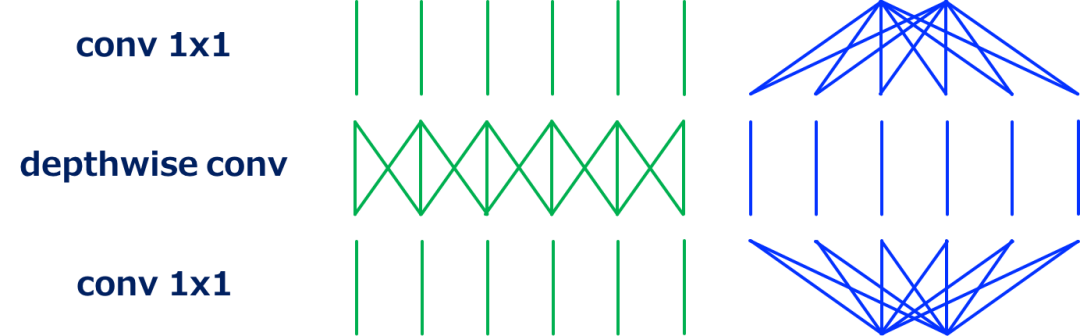
从上面可以看到,与标准的 bottleneck 架构相反,第一个conv1x1增加了通道维度,然后执行depthwise conv,最后一个conv1x1减少了通道维度。
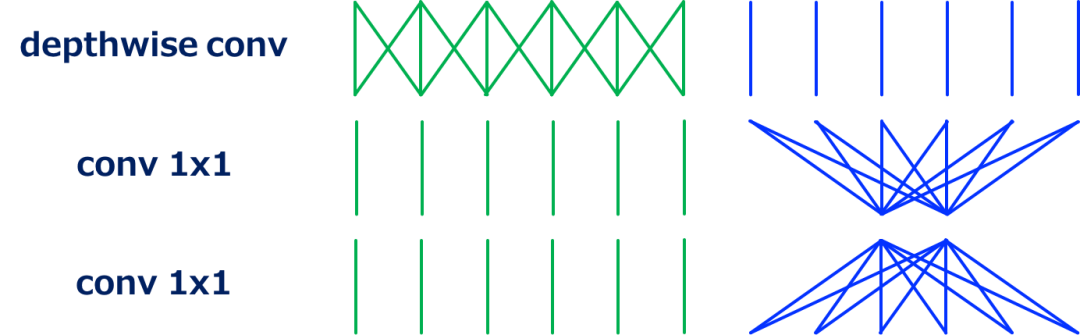
通过如上所述对building blocks 进行重新排序,并将其与MobileNet-v1(可分离的conv)进行比较,我们可以看到这个体系结构是如何工作的(这种重新排序不会改变整个模型体系结构,因为MobileNet-v2是这个模块的堆叠)。
也就是说,上述模块可以看作是可分离卷积的一个改进版本,其中可分离卷积中的单个conv1x1被分解为两个conv1x1。让T表示通道维数的扩展因子,两个 conv1x1 的计算量为 2HWN²/T ,而可分离卷积下的conv1x1的计算量为 HWN²。在[5]中,使用T = 6,将 conv1x1 的计算成本降低了3倍(一般为T/2)。
FD-MobileNet
最后,介绍 Fast-Downsampling MobileNet (FD-MobileNet)[10]。在这个模型中,与MobileNet相比,下采样在较早的层中执行。这个简单的技巧可以降低总的计算成本。其原因在于传统的向下采样策略和可分离变量的计算代价。
从VGGNet开始,许多模型采用相同的下采样策略:执行向下采样,然后将后续层的通道数增加一倍。对于标准卷积,下采样后计算量不变,因为根据定义得 HWNK²M 。而对于可分离变量,下采样后其计算量减小;由 HWN(K² + M) 降为 H/2 W/2 2N(K² + 2M) = HWN(K²/2 + M)。当M不是很大时(即较早的层),这是相对占优势的。
下面是对全文的总结

References
[1] M. Lin, Q. Chen, and S. Yan, “Network in Network,” in Proc. of ICLR, 2014.
[2] L. Sifre, “Rigid-motion Scattering for Image Classification, Ph.D. thesis, 2014.
[3] L. Sifre and S. Mallat, “Rotation, Scaling and Deformation Invariant Scattering for Texture Discrimination,” in Proc. of CVPR, 2013.
[4] F. Chollet, “Xception: Deep Learning with Depthwise Separable Convolutions,” in Proc. of CVPR, 2017.
[5] X. Zhang, X. Zhou, M. Lin, and J. Sun, “ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices,” in arXiv:1707.01083, 2017.
[6] K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” in Proc. of CVPR, 2016.
[7] S. Xie, R. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated Residual Transformations for Deep Neural Networks,” in Proc. of CVPR, 2017.
[8] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications,” in arXiv:1704.04861, 2017.
[9] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L. Chen, “MobileNetV2: Inverted Residuals and Linear Bottlenecks,” in arXiv:1801.04381v3, 2018.
往期精彩:
数学推导+纯Python实现机器学习算法23:CRF条件随机场