
深入剖析分布式事务一致性
点击下方“IT牧场”,选择“设为星标”

概述
一致性指什么
Atomicity(原子性):一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复到事务开始前的状态,就像这个事务从来没有执行过一样。 Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。完整性包括外键约束、应用定义的等约束不会被破坏。 Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。 Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
无法做到强一致
目前在跨库、跨服务的分布式实际应用中,尚未看到有强一致性的方案。
我们来看看一致性级别最高的XA事务,是否是强一致的,我们以跨行转账(在这里,我们以跨库更新AB来模拟)作为例子来说明,下面是一个XA事务的时序图: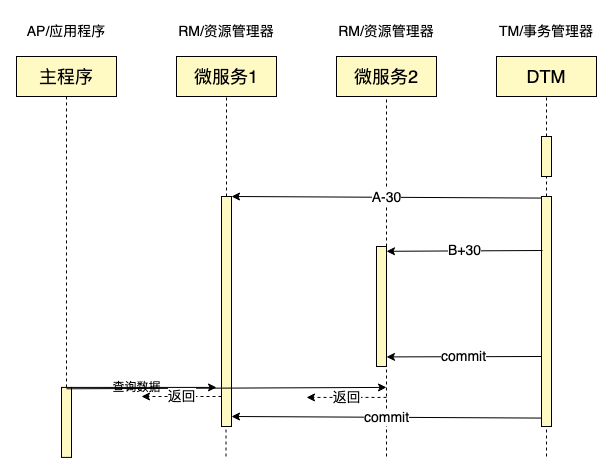
在这个时序图中,我们在如图所示的时间点发起查询,那么我们查到的数据,将是A+B+30,不等于A+B,不符合强一致的要求。
理论上的强一致性
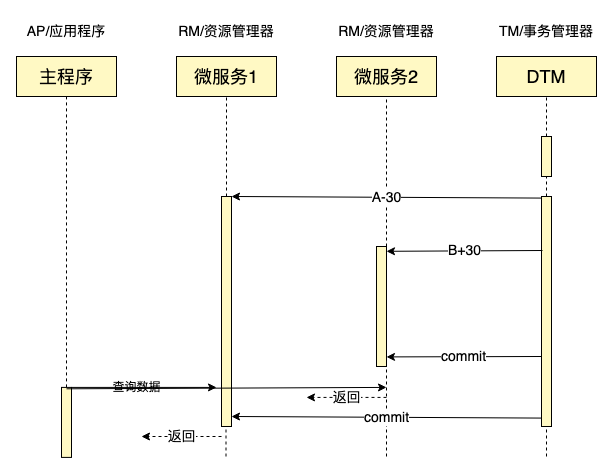
这种情况下,查到结果等于A+B,但是又有另一些场景出现了问题,如下图所示:
对于查询,也采用XA事务,并且查询数据时,采用select for update的方式,所有数据查完之后,再xa commit 为了避免死锁,需要将涉及到的数据库排序,访问数据都必须要按照相同的数据库顺序来写入和查询

在T0时间查询,那么修改一定发生在查询全部完成之后,所以查询得到结果A+B
在T1,T2,T3查询,那么查询结果返回一定全部发生在修改完成之后,所以查询得到结果也是A+B
很明显这种理论上的强一致,效率极低,所有有数据交集的数据库事务都是串行执行,而且还需要按照特定的顺序查询/修改数据,因此成本极高,几乎无法应用在生产中。
NewSQL的强一致性
实现跨服务但不跨库的分布式事务一致性,会相对简单一些,其中一种方式就是实现XA事务中的TMRESUME选项(因为最终只有一个xa commit,不会出现两个xa commit中间的不一致时间窗口)。 实现跨数据库的分布式事务一致性,会困难很多,因为各个数据库的内部版本机制都不一样,想要协同非常困难。
弱一致性的分类
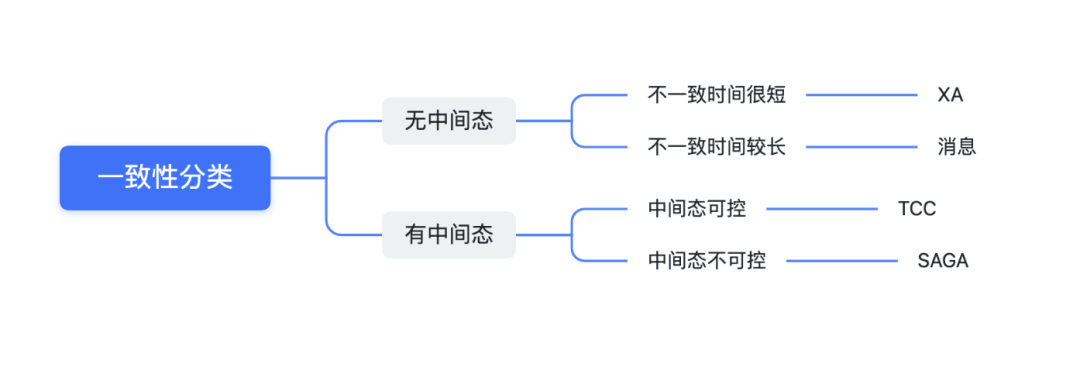
无中间态:数据只有两个状态,事务前和事务后,没有其他第三种状态。XA、消息这两种都是这种
有中间态:数据有中间态,例如TCC的Try,数据状态和事务前事务后都不一样;SAGA也有中间态,假如一个SAGA事务执行正向操作后数据为W,又回滚了,那么W也与事务前事务后的状态不同。
XA:XA虽然不是强一致,但是XA的一致性是多种分布式事务中,一致性最好的,因为他处于不一致的状态时间很短,只有一部分分支开始commit,但还没有全部commit的这个时间窗口,数据是不一致的。因为数据库的commit操作耗时,通常是10ms内,因此不一致的窗口期很短。
消息:消息型在第一个操作完成后,在所有操作完成之前,这个时间窗口是不一致的,持续时长一般比XA更久。
TCC:TCC的中间态,通常可控,可以自定义。通常情况下,这部分数据不展示给用户,因此一致性比后面的SAGA要好。
SAGA:SAGA如果发生回滚,而子事务中正向操作修改的数据会被用户看到,可能给用户带来较差的体验,因此一致性是最差的。
CAP理论中的一致性
CAP中的强一致性是指用户在分布式系统中写完之后,立刻去读,如果能够像本地读写那样,读到最新版本,那么是强一致性。 分布式事务中的强一致性,是指事务进行的过程中,用户读取的数据始终满足业务约束,目前在实际应用中的方案,都无法做到强一致。
总结
作者:叶东富
来源:segmentfault.com/a/1190000041106277
版权申明:内容来源网络,仅供分享学习,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
干货分享
最近将个人学习笔记整理成册,使用PDF分享。关注我,回复如下代码,即可获得百度盘地址,无套路领取!
•001:《Java并发与高并发解决方案》学习笔记;•002:《深入JVM内核——原理、诊断与优化》学习笔记;•003:《Java面试宝典》•004:《Docker开源书》•005:《Kubernetes开源书》•006:《DDD速成(领域驱动设计速成)》•007:全部•008:加技术群讨论
加个关注不迷路
喜欢就点个"在看"呗^_^