
【爬虫、算法】基于Dijkstra算法的武汉地铁路径规划!
前言
最近爬取了武汉地铁线路的信息,通过调用高德地图的api 获得各个站点的进度和纬度信息,使用Dijkstra算法对路径进行规划。
1.数据爬取
首先是需要获得武汉各个地铁的地铁站信息,通过爬虫爬取武汉各个地铁站点的信息,并存储到xlsx文件中
武汉地铁线路图,2021最新武汉地铁线路图,武汉地铁地图-武汉本地宝wh.bendibao.com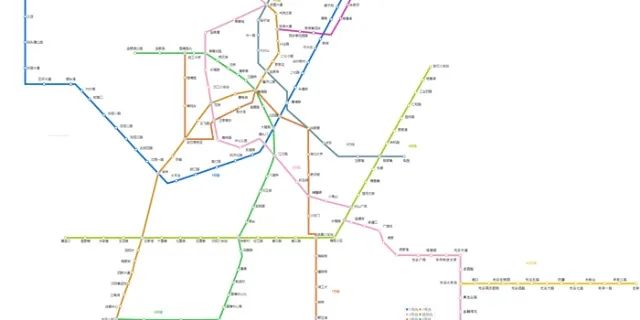
方法:requests、BeautifulSoup、pandas
import requests
from bs4 import BeautifulSoup
import pandas as pd
def spyder():
#获得武汉的地铁信息
url='http://wh.bendibao.com/ditie/linemap.shtml'
user_agent='Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
headers = {'User-Agent': user_agent}
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, 'lxml')
all_info = soup.find_all('div', class_='line-list')
df=pd.DataFrame(columns=['name','site'])
for info in all_info:
title=info.find_all('div',class_='wrap')[0].get_text().split()[0].replace('线路图','')
station_all=info.find_all('a',class_='link')
for station in station_all:
station_name=station.get_text()
temp={'name':station_name,'site':title}
df =df.append(temp,ignore_index=True)
df.to_excel('./subway.xlsx',index=False)
我们将爬取的地铁信息保存到excel文件中
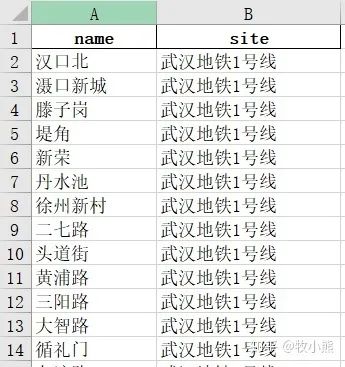
如果要做路径规划的话,我们还需要知道地铁站的位置信息
因此我们选择了高德地图的api接口
2.高德地图api接口配置
高德开放平台 | 高德地图 APIlbs.amap.com? 链接:https://link.zhihu.com/?target=https%3A//lbs.amap.com/%3Fref%3Dhttps%3A//console.amap.com)
首先我们注册账号
选择为个人开发者
填写个人信息...
注册成功后,我们来登陆高德地图api
选择我的应用
创建新应用
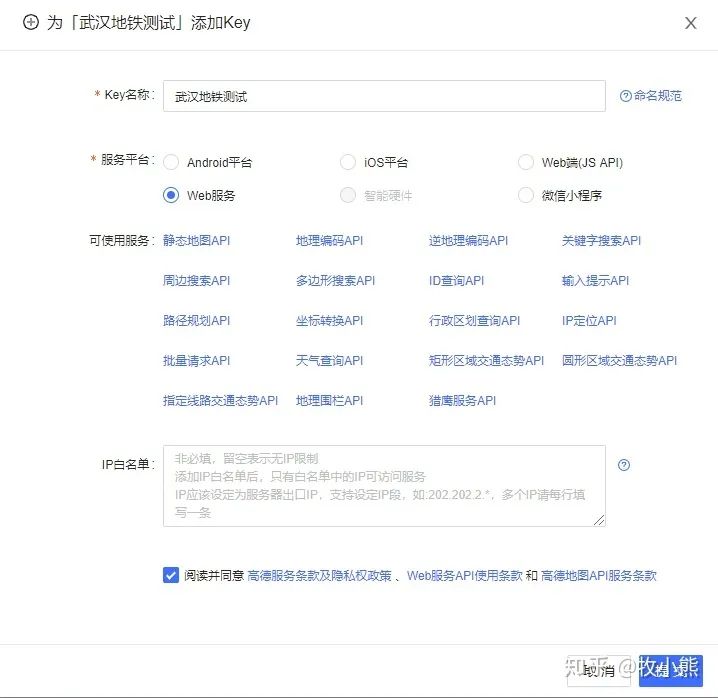
选择web服务

这个时候高德地图就给你了一个key
3.得到地铁站的经度和纬度
配置一个get_location函数区访问高德地图的api 然后返回经度和纬度
def get_location(keyword,city):
#获得经纬度
user_agent='Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
headers = {'User-Agent': user_agent}
url='http://restapi.amap.com/v3/place/text?key='+keynum+'&keywords='+keyword+'&types=&city='+city+'&children=1&offset=1&page=1&extensions=all'
data = requests.get(url, headers=headers)
data.encoding='utf-8'
data=json.loads(data.text)
result=data['pois'][0]['location'].split(',')
return result[0],result[1]
keyword是你要查询的地址,city代表城市
我们这里city就设置为武汉
我们边爬取地铁站信息 边获得经度和纬度
于是得到了改进版的爬虫
def spyder():
#获得武汉的地铁信息
print('正在爬取武汉地铁信息...')
url='http://wh.bendibao.com/ditie/linemap.shtml'
user_agent='Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11'
headers = {'User-Agent': user_agent}
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, 'lxml')
all_info = soup.find_all('div', class_='line-list')
df=pd.DataFrame(columns=['name','site'])
for info in tqdm(all_info):
title=info.find_all('div',class_='wrap')[0].get_text().split()[0].replace('线路图','')
station_all=info.find_all('a',class_='link')
for station in station_all:
station_name=station.get_text()
longitude,latitude=get_location(station_name,'武汉')
temp={'name':station_name,'site':title,'longitude':longitude,'latitude':latitude}
df =df.append(temp,ignore_index=True)
df.to_excel('./subway.xlsx',index=False)
4.得到地铁站之间的距离并构建图
计算各个地铁站的信息,并生成地铁站网络
现在我们得到了地铁站的经度和纬度 可以通过geopy.distance这个包来计算2点之间的距离
from geopy.distance import geodesic
print(geodesic((纬度,经度), (纬度,经度)).m) #计算两个坐标直线距离
当然高德地图api也同样提供了计算距离的接口
我们来配置计算距离的函数
输入经度和纬度就可以计算距离
def compute_distance(longitude1,latitude1,longitude2,latitude2):
#计算2点之间的距离
user_agent='Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
headers = {'User-Agent': user_agent}
url='http://restapi.amap.com/v3/distance?key='+keynum+'&origins='+str(longitude1)+','+str(latitude1)+'&destination='+str(longitude2)+','+str(latitude2)+'&type=1'
data=requests.get(url,headers=headers)
data.encoding='utf-8'
data=json.loads(data.text)
result=data['results'][0]['distance']
return result
那么接下来就构建地铁站之间的图网络
因为爬取地铁站信息比较耗时,我们将制作好的图网络保存为pickle文件方便以后使用
def get_graph():
print('正在创建pickle文件...')
data=pd.read_excel('./subway.xlsx')
#创建点之间的距离
graph=defaultdict(dict)
for i in range(data.shape[0]):
site1=data.iloc[i]['site']
if i0]-1:
site2=data.iloc[i+1]['site']
#如果是共一条线
if site1==site2:
longitude1,latitude1=data.iloc[i]['longitude'],data.iloc[i]['latitude']
longitude2,latitude2=data.iloc[i+1]['longitude'],data.iloc[i+1]['latitude']
name1=data.iloc[i]['name']
name2=data.iloc[i+1]['name']
distance=compute_distance(longitude1,latitude1,longitude2,latitude2)
graph[name1][name2]=distance
graph[name2][name1]=distance
output=open('graph.pkl','wb')
pickle.dump(graph,output)
5.得到当前位置距离最近的地铁站
我们要去找距离最近的地铁站 首先是获得位置的坐标
然后将当前的坐标遍历所有地铁站 找到最近的地铁站
longitude1,latitude1=get_location(site1,'武汉')
longitude2,latitude2=get_location(site2,'武汉')
data=pd.read_excel('./subway.xlsx')
定义get_nearest_subway函数来寻找最近的地铁站
def get_nearest_subway(data,longitude1,latitude1):
#找最近的地铁站
longitude1=float(longitude1)
latitude1=float(latitude1)
distance=float('inf')
nearest_subway=None
for i in range(data.shape[0]):
site1=data.iloc[i]['name']
longitude=float(data.iloc[i]['longitude'])
latitude=float(data.iloc[i]['latitude'])
temp=geodesic((latitude1,longitude1), (latitude,longitude)).m
if temp distance=temp
nearest_subway=site1
return nearest_subway
通过遍历地铁站的距离找到了最近的上车点和下车点
6.使用Dijkstra算法对地铁线路进行规划
Dijkstra算法是求最短路径的经典算法
Dijkstra算法主要特点是从起始点开始,采用贪心算法的策略,每次遍历到始点距离最近且未访问过的顶点的邻接节点,直到扩展到终点为止。
首先是读取构建的图信息
def subway_line(start,end):
file=open('graph.pkl','rb')
graph=pickle.load(file)
#创建点之间的距离
#现在我们有了各个地铁站之间的距离存储在graph
#创建节点的开销表,cost是指从start到该节点的距离
costs={}
parents={}
parents[end]=None
for node in graph[start].keys():
costs[node]=float(graph[start][node])
parents[node]=start
#终点到起始点距离为无穷大
costs[end]=float('inf')
#记录处理过的节点list
processed=[]
shortest_path=dijkstra(start,end,graph,costs,processed,parents)
return shortest_path
构建dijkstra算法
#计算图中从start到end的最短路径
def dijkstra(start,end,graph,costs,processed,parents):
#查询到目前开销最小的节点
node=find_lowest_cost_node(costs,processed)
#使用找到的开销最小节点,计算它的邻居是否可以通过它进行更新
#如果所有的节点都在processed里面 就结束
while node is not None:
#获取节点的cost
cost=costs[node] #cost 是从node 到start的距离
#获取节点的邻居
neighbors=graph[node]
#遍历所有的邻居,看是否可以通过它进行更新
for neighbor in neighbors.keys():
#计算邻居到当前节点+当前节点的开销
new_cost=cost+float(neighbors[neighbor])
if neighbor not in costs or new_cost costs[neighbor]=new_cost
#经过node到邻居的节点,cost最少
parents[neighbor]=node
#将当前节点标记为已处理
processed.append(node)
#下一步继续找U中最短距离的节点 costs=U,processed=S
node=find_lowest_cost_node(costs,processed)
#循环完成 说明所有节点已经处理完
shortest_path=find_shortest_path(start,end,parents)
shortest_path.reverse()
return shortest_path
#找到开销最小的节点
def find_lowest_cost_node(costs,processed):
#初始化数据
lowest_cost=float('inf') #初始化最小值为无穷大
lowest_cost_node=None
#遍历所有节点
for node in costs:
#如果该节点没有被处理
if not node in processed:
#如果当前的节点的开销比已经存在的开销小,那么久更新该节点为最小开销的节点
if costs[node] lowest_cost=costs[node]
lowest_cost_node=node
return lowest_cost_node
#找到最短路径
def find_shortest_path(start,end,parents):
node=end
shortest_path=[end]
#最终的根节点为start
while parents[node] !=start:
shortest_path.append(parents[node])
node=parents[node]
shortest_path.append(start)
return shortest_path
7.将所有的函数封装
构建main文件将整个流程封装起来
def main(site1,site2):
if not os.path.exists('./subway.xlsx'):
spyder()
if not os.path.exists('./graph.pkl'):
get_graph()
longitude1,latitude1=get_location(site1,'武汉')
longitude2,latitude2=get_location(site2,'武汉')
data=pd.read_excel('./subway.xlsx')
#求最近的地铁站
start=get_nearest_subway(data,longitude1,latitude1)
end=get_nearest_subway(data,longitude2,latitude2)
shortest_path=subway_line(start,end)
if site1 !=start:
shortest_path.insert(0,site1)
if site2 !=end:
shortest_path.append(site2)
print('路线规划为:','-->'.join(shortest_path))
if __name__ == '__main__':
global keynum
keynum='' #输入自己的key
main('华中农业大学','东亭')
比方我想去东亭,想坐地铁过去
我们看看通过规划的地铁线路
路线规划为:华中农业大学-->野芷湖-->板桥-->湖工大-->建安街-->瑞安街-->武昌火车站-->梅苑小区-->中南路-->洪山广场-->楚河汉街-->青鱼嘴-->东亭
我们来看看高德地图给我们的规划

不得了,一模一样~
8.可以继续完善的点
这个项目我们只做了地铁的相关信息,没有引入公交的信息加入道路线规划中,因此后续可以爬取武汉的公交线路进行地铁、公交混合线路规划
同时给出的规划信息只有文字描述,没有显示在地图上不够直观,我们可以进行flask的部署将规划的线路显示在地图上,更加不容易出错~
9.项目源码
https://pan.baidu.com/s/1dmstu7PlF12Bdgk9QTjsPA 提取码:r8es
往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码: