
MSRA、北大的女娲:图像视频生成的大一统模型
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
新智元 编辑:好困 小咸鱼 LRS
【新智元导读】微软亚洲研究院、北京大学强强联合提出了一个可以同时覆盖语言、图像和视频的统一多模态预训练模型——NÜWA(女娲),直接包揽8项SOTA。其中,NÜWA更是在文本到图像生成中完虐OpenAI DALL-E。








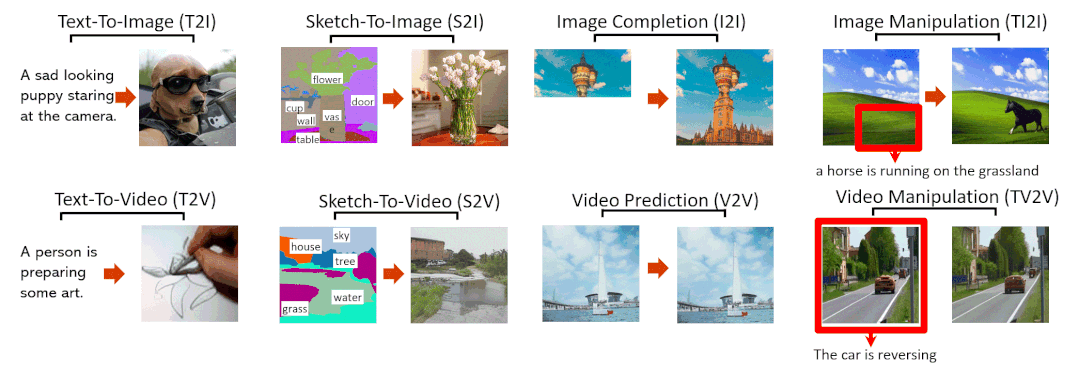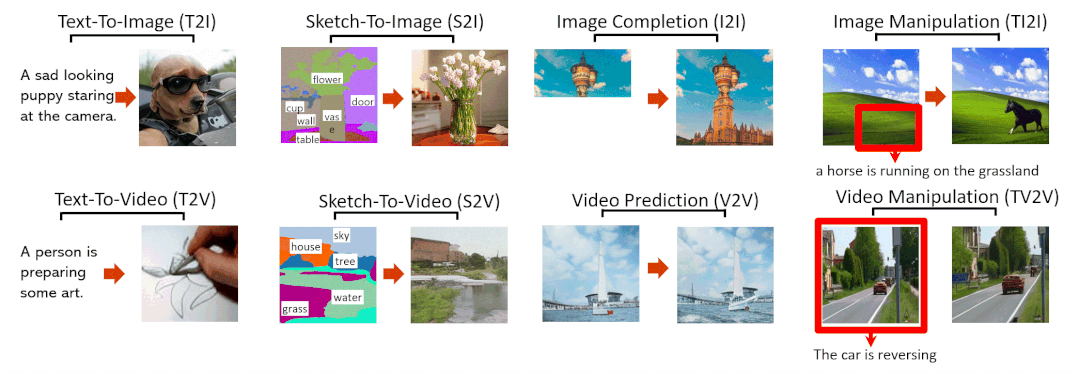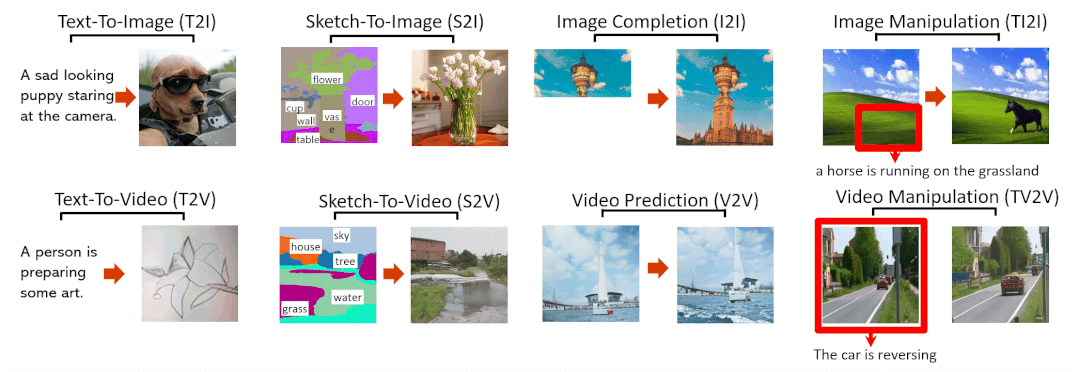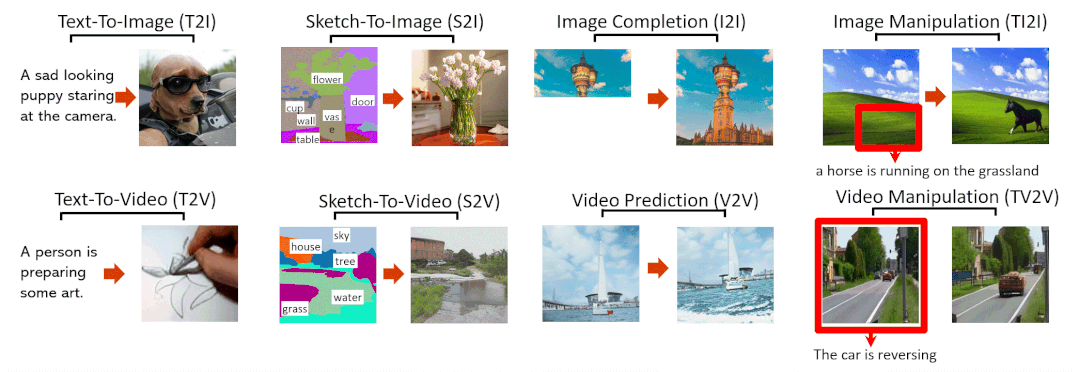
8大SOTA效果抢先看
8大SOTA效果抢先看
文字转图像(Text-To-Image,T2I)

草图转图像(SKetch-to-Image,S2I)

图像补全(Image Completion,I2I)

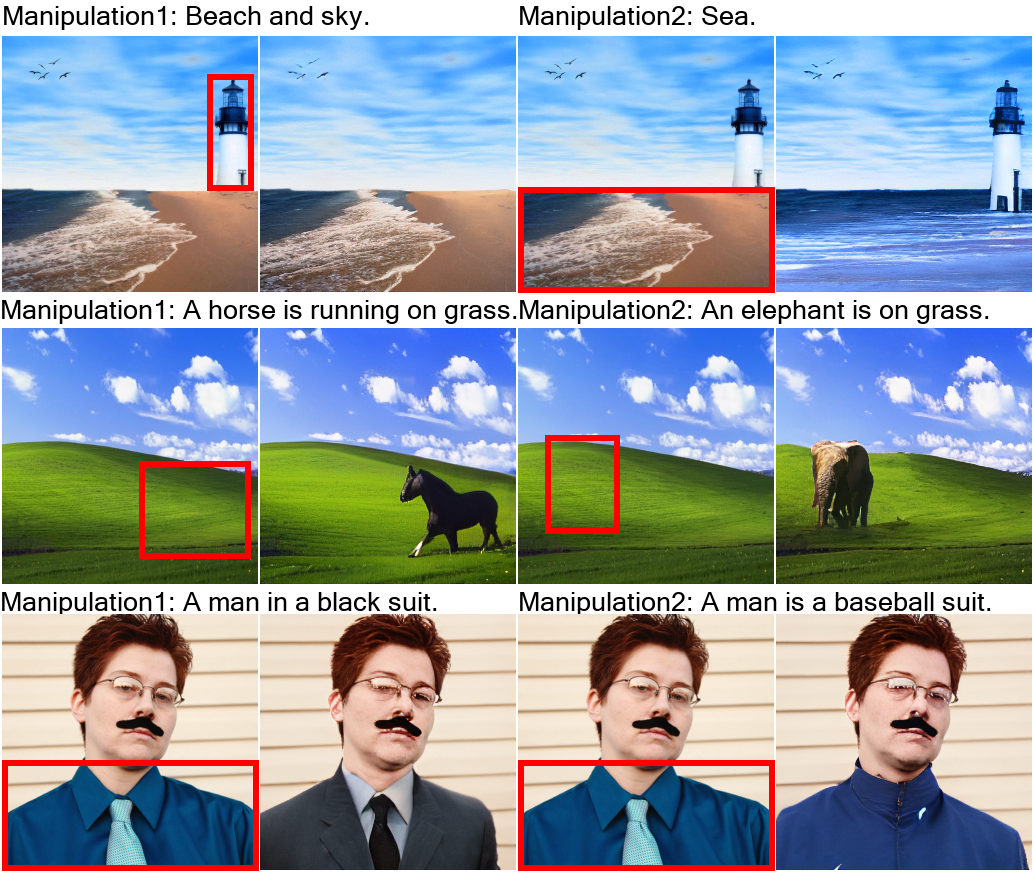
用文字指示修改图像(Text-Guided Image Manipulation,TI2I)
文字转视频(Text-to-Video,T2V)
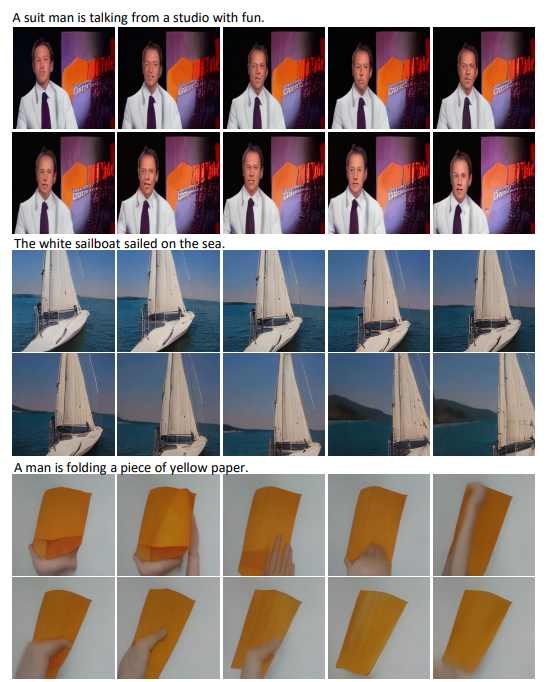
视频预测(Video Prediction,V2V)

草图转视频(Sketch-to-Video,S2V)

用文字指示修改视频(Text-Guided Video Manipulation,TV2V)

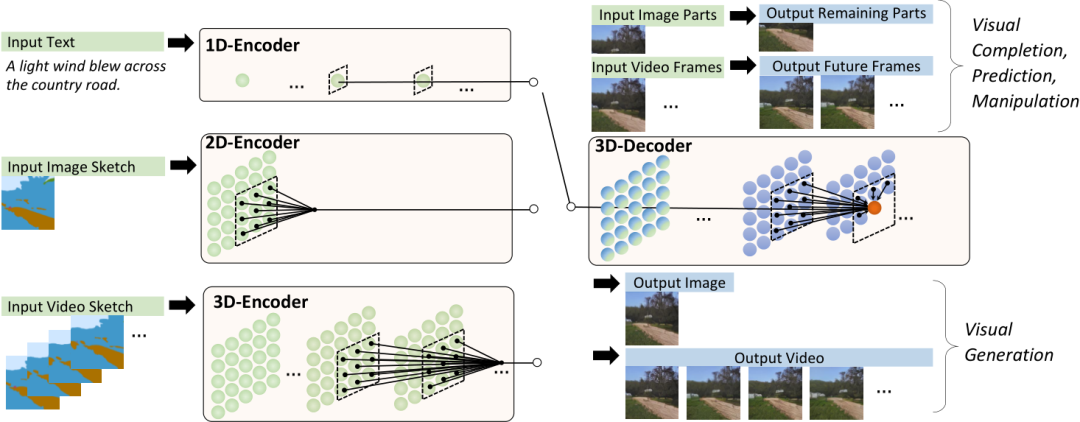
NÜWA为啥这么牛?
NÜWA为啥这么牛?
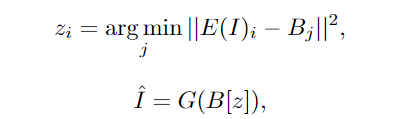

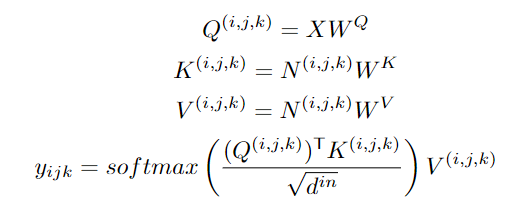
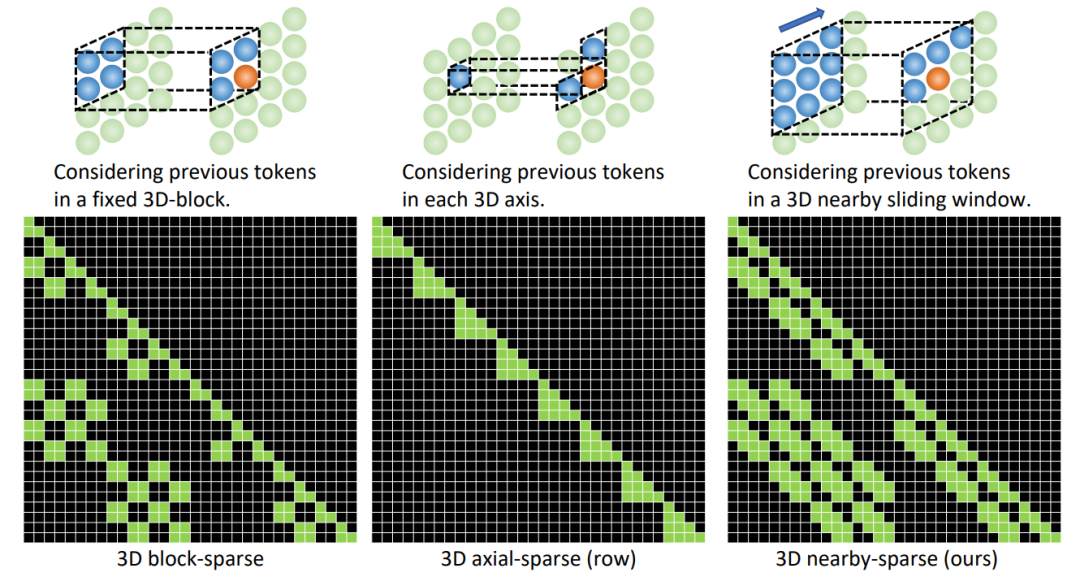
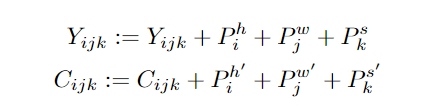
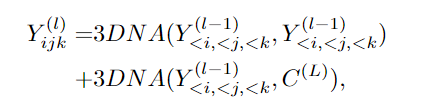
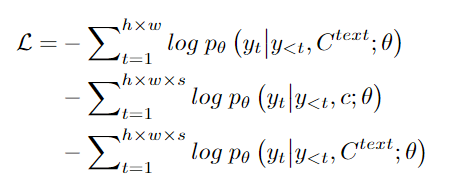
实验结果
实验结果
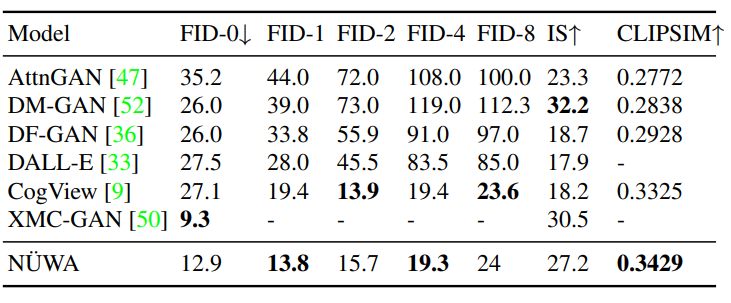
文本转图像(T2I)

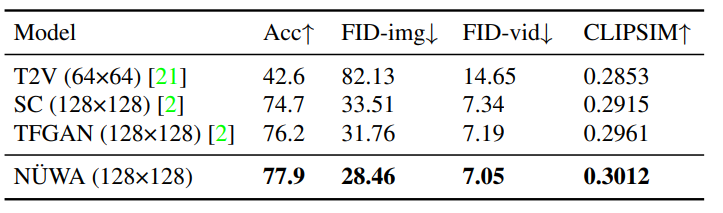
文本转视频(T2V)

图像补全(I2I)

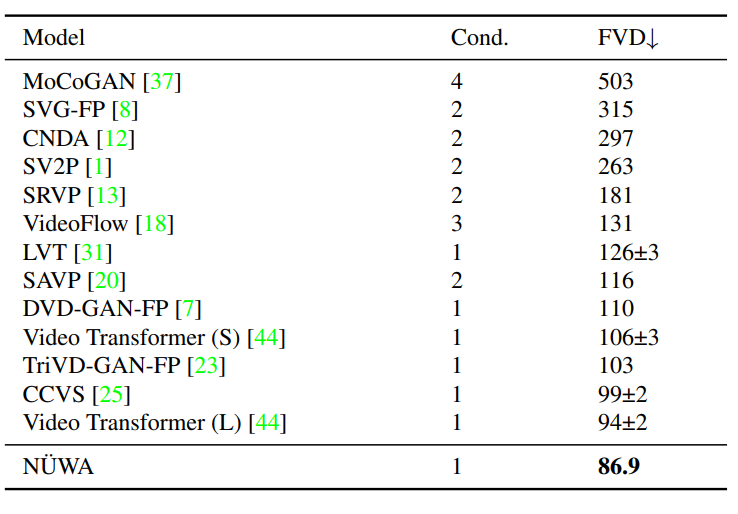
视频预测(V2V)
草图转图像(S2I)

用文本引导图像修改(TI2I)

结论
结论
P.S. 本文截图由ReadPaper自动截取生成(还挺好用,狗头)。
参考资料:
https://arxiv.org/abs/2111.12417
https://github.com/microsoft/NUWA
猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
评论