
ICCV2021 | MIMO-UNet:重新思考CTF方案达成去模糊新高度
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达

arXiv:2108.05054
code: https://github.com/chosj95/MIMO-UNet
Abstract
Coarse-to-fine(CTF)策略已被广泛应用到图像去模糊领域,常规方法通常通过堆叠多尺度输入的子网络渐进提升提升输出图像的锐利度。比如DeepBlur、SRN所采用的处理策略。
面向快速而精确的去模糊模型设计,我们对CTF策略进行了回顾并提出了一种多输入多输出UNet架构:MIMO-UNet。所提方案具有三个截然不同的特性:
MIMO-UNet单编码器的多尺度图像输入设计缓解了训练的难度;
MIMO-UNet单解码器的多尺度图像输出方式以单U形网络模仿了级联UNet架构;
非对称的特征融合更够更高效的合并多尺度特征。
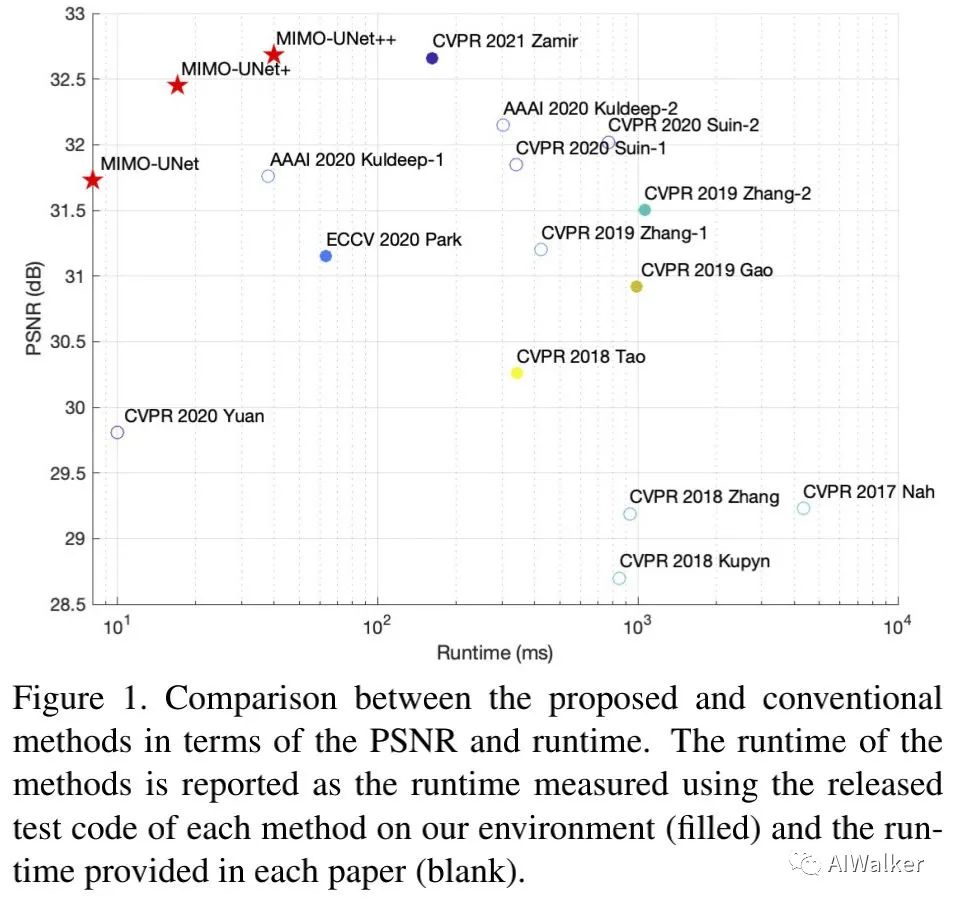
GoPro与RealBlur数据集上的实验结果表明:在模型性能与计算复杂方面,所提方案均取得了优于SOTA方案的性能。从下图可以看到:所提方案取得了最佳的性能-复杂度均衡。
Method
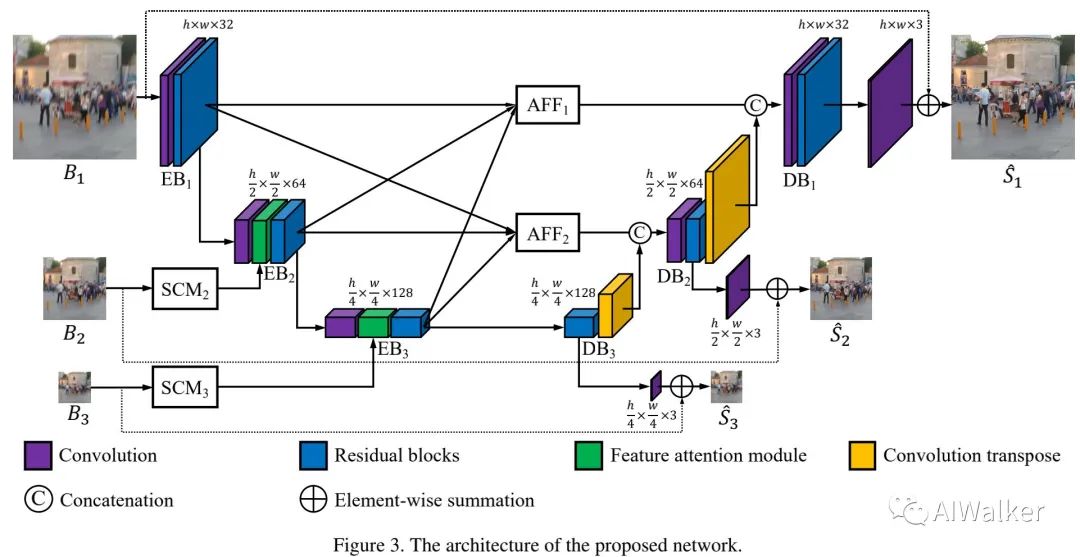
上图给出了本文所提MIMO-UNet架构示意图,它在UNet的基础上改进而来,通过充分利用多尺度特征达到高效去模糊的目的。MIMO-UNet的编码器与解码器分别包含三个编码模块(encoder blocks, EBs)与解码模块(decoder blocks, DBs)。接下来,我们将对图中的不同模块进行介绍,比如MISE,MOSD,AFF。
Multi-input single encoder
已有研究表明:多尺度图像输入可以更好的处理图像中不同程度的模糊。该思想已被广泛用于DeepBlur、SRN、PSS-NSC等方案。
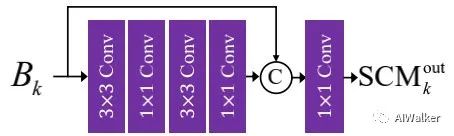
在MIMO-UNet架构中,它从下采样模糊图像中提取特征然后进行不同尺度特征合并。我们首先采用SCM(见上图)从下采样图像中提取特征,考虑到高效性,我们堆叠两次提取特征,然后与输入concat,最后再通过卷积提取特征。注:表示第级SCM的输出。
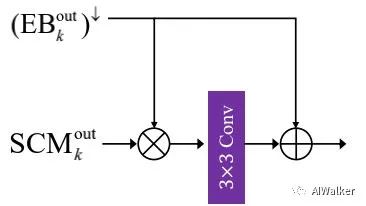
在与融合方面,我们先对执行stride=2的卷积得到。此时,与具有相同的尺寸,我们采用FAM(见上图)进行自适应融合,融合后的特征将通过8个改进残差模块更进一步处理。注:相比常规特征融合方法,FAM具有更好的性能提升。
Multi-output single decoder
在MIMO-UNet架构中,不同DBs具有不同尺寸的特征,这些多尺度特征可以用于模仿多个堆叠子网络。我们对每个DB添加了临时监督信息,每级图像重建过程描述如下:
Asymmetric feature fusion
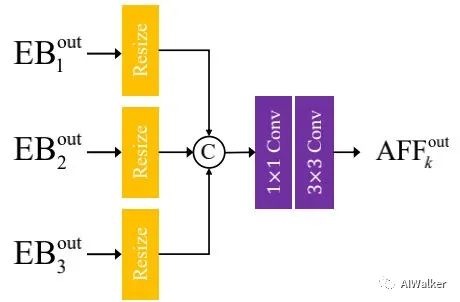
常规的CTF方案采用粗粒度特征对细粒度特征进行更新,而并未使用细粒度特征对粗粒度特征进行更新。为缓解该问题,本文构建了上图的AFF特征融合架构。一级与二级AFF模块定义如下:
Loss function
在损失函数方面,本文采用了常规的L1损失与频域损失,分别定义如下:
Experiments
训练数据选用了GoPro与RealBlur两个数据集,分别训练了3000与1000epoch。
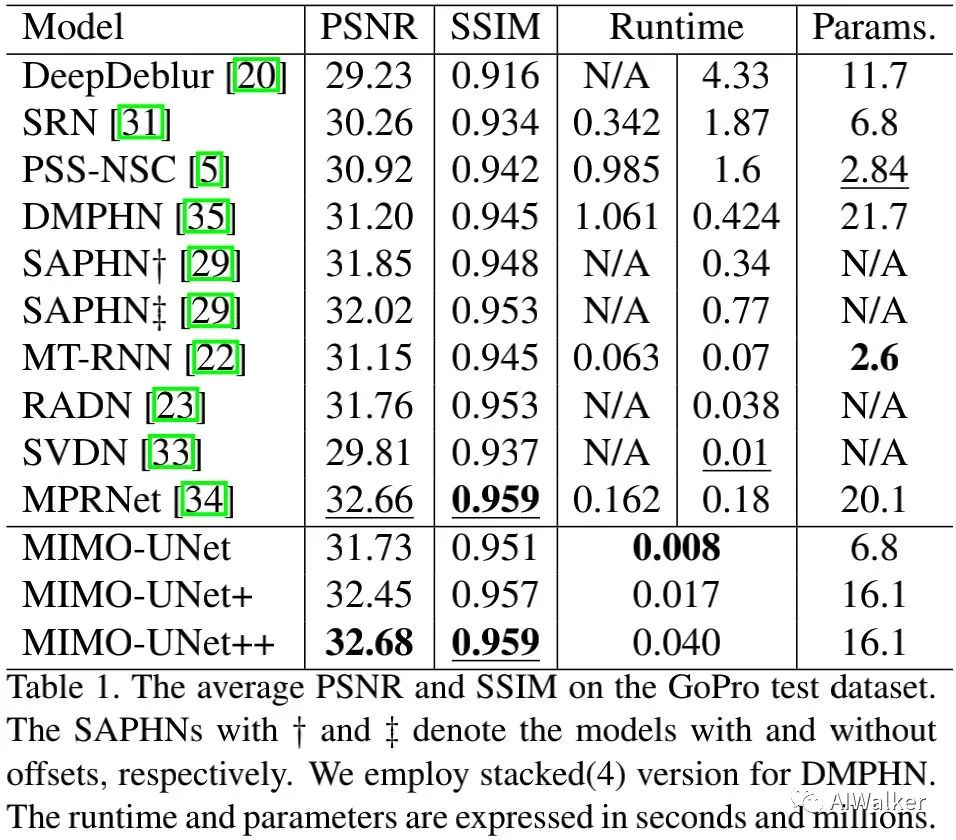
上表比较不同方案在GoPro数据集上的性能,从中可以看到:
相比SRN、PSS-NSC、DMPHN,MIMO-UNet+推理速度更快,精度更高;
相比MPRNet,MIMO-UNet++推理速度快4倍,指标高0.02dB;

上图为GoPro数据集上不同方案的视觉效果对比,很明显:所提方案生成结果更清晰锐利。
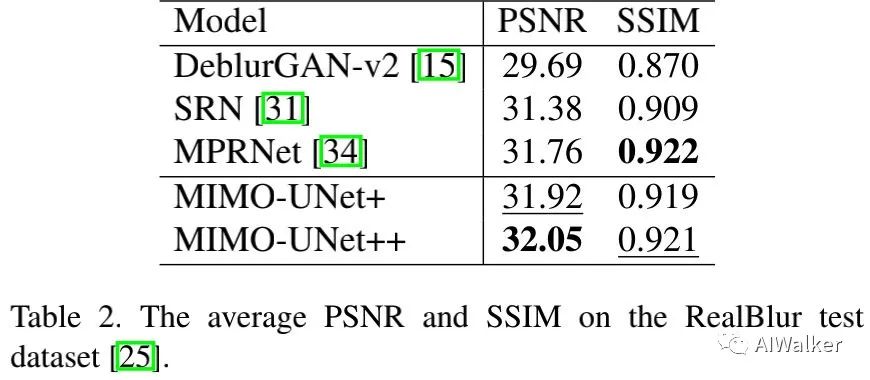
上表为RealBlur数据集上的性能对比,可以看到:MIMO-UNet++取得了最佳PSNR指标 。

上图为RealBlur数据集上不同方案的视觉效果对比,毋庸置疑,所提方案视觉效果肯定更好咯。
Ablation Study

上表比较了不同特征融合方法的性能,可以看到:本文所提FAM具有更高的PSNR指标 。
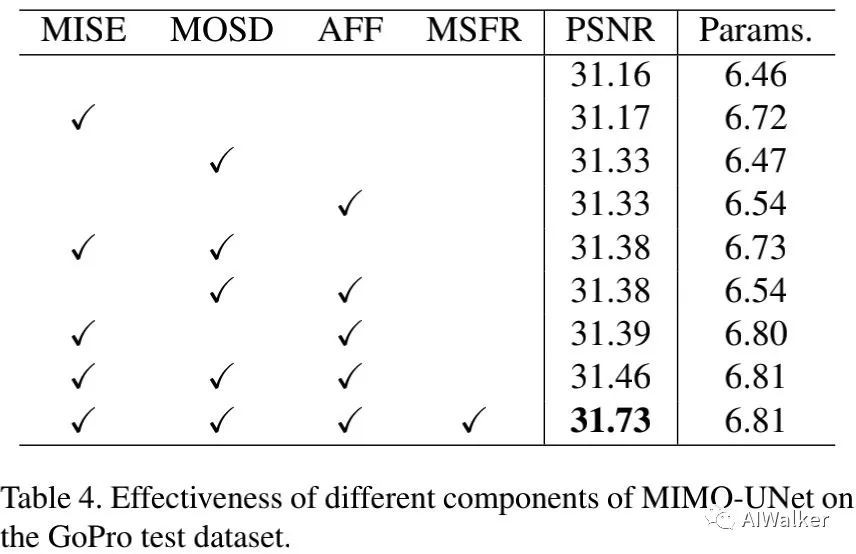
上表对比了不同模块对于性能的影响,可以看到:
相比基线模型,MSOD带来了0.17dB指标提升;
相比基线模型,MISE带来的性能提升非常少,仅有0.01dB;
当MISE与MSOD组合使用时,MISE可以带来额外的0.05dB指标提升;
相比基线模型,AFF可以带来0.17dB指标提升,MISE与AFF组合使用时性能提升可达到0.23dB;
当MISE、MOSD以及AFF组合使用时,性能提升高达0.3dB;
当引入MSFR损失后,模型性能可以得到额外的0.27dB提升;
相比基线模型,融合上述模块与损失后的模型性能提升高达0.57dB 。
个人思考
虽然笔者以low-level为主,对deblurring这块的方案也还算了解,但确实没有深入思考过其内在的一些东西,比如coarse-to-fine机制,再比如它与SR的关键区别所在。
从以往看到的方案来看,自从DeepBlur首次提出以来,deblurring领域的优秀方案几乎都采用了coarse-to-fine机制,不同方案的区别大多在block层面,较少涉及coarse-to-fine机制的改进。
本文则对coarse-to-fine机制进行了思考,从多尺度特征融合、多尺度输入、多尺度输出等角度进行了探索,进而得到了具有高效率、高性能的deblurring方案。
最后吐槽一下:这篇论文的code已经开源,但code实现写的真心让人看的火大!code风格让人看的痛苦。
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
