
Transformer竟在图神经网络的ImageNet大赛中屠榜?
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!

AI圈可太 TM 魔幻了!
就在昨天刚结束的KDD Cup 2021 和OGB 官方联合举办的第一届图神经网络竞赛OGB Large-Scale Challenge中,来自微软亚洲研究院(MSRA)和大连理工的团队力压DeepMind、百度等队伍,夺得图预测任务赛道第一名。

各位看官,您猜怎么着?
AI 科技评论发现在这场号称“地表最强图神经网络”之争的国际权威竞赛中,获得第一名的模型不是图神经网络模型,反而是 Transformer 模型?

兜兜转转又是你,Transformer 你是要上天吗?之前你从NLP强势跨界到CV,这次又是在图神经网络拿了个冠军,你是什么都能参与一脚吗?国足要是有你这精神该多好啊!
这究竟是肿么一回事呢?
我们先从这次KDD Cup 2021 和OGB 官方联合举办的大赛说起。
其中KDD Cup大赛大家都很熟悉了,它是由SIGKDD主办的数据挖掘研究领域的国际顶级赛事,从1997年开始,每年举办一次,是目前数据挖掘领域最具影响力的赛事。该比赛同时面向企业界和学术界,云集了世界数据挖掘界的顶尖专家、学者。
而今年,KDD Cup与OGB (Open Graph Benchmark)团队联合举办了第一届OGB-LSC比赛,提供来自真实世界的超大规模图数据。
在比赛的三个赛道中,图预测任务最受人瞩目(另外两个赛道为节点预测和关系预测):本次图预测任务发布了有史以来最大的有标注图数据集PCQM4M-LSC, 其中包含超过3,800,000个有标注分子图 (作为对比,ImageNet挑战赛包含1,000,000张标注图片,而在此之前最大的有标注图数据集大小不过约450,000个有标注分子图)。
另外根据本次大赛承办方,斯坦福大学Jure Leskovec教授回应,本次大赛总共有全球 500 多个顶尖高校和实验室队伍参赛,因此,无论是从参赛规模还是赛题难度上来讲,本届OGB-LSC竞赛都堪称为图神经网络领域的第一届「ImageNet」挑战赛。

赛题介绍
本次图预测竞赛的任务是对给定的2D结构分子图,预测由 DFT 计算的分子性质,如 HOMO-LUMO 能带隙。DFT (density functional theory, 密度泛函理论)基于量子物理力场,可以精确地预测多种分子性质。
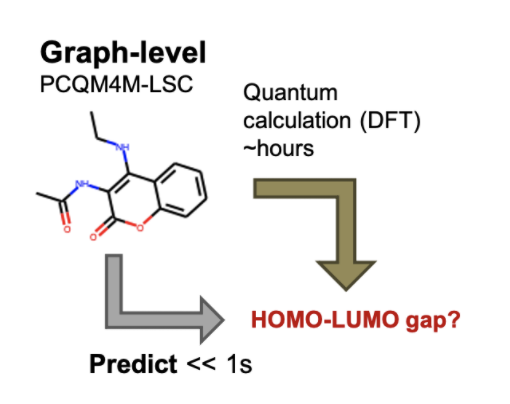
然而,DFT的计算开销过于巨大,往往一个小分子的计算便需要耗费几个小时。因此,使用快速而准确的机器学习模型来近似DFT是非常热门的研究方向,并且有广泛的应用,如药物发现、材料发现等。

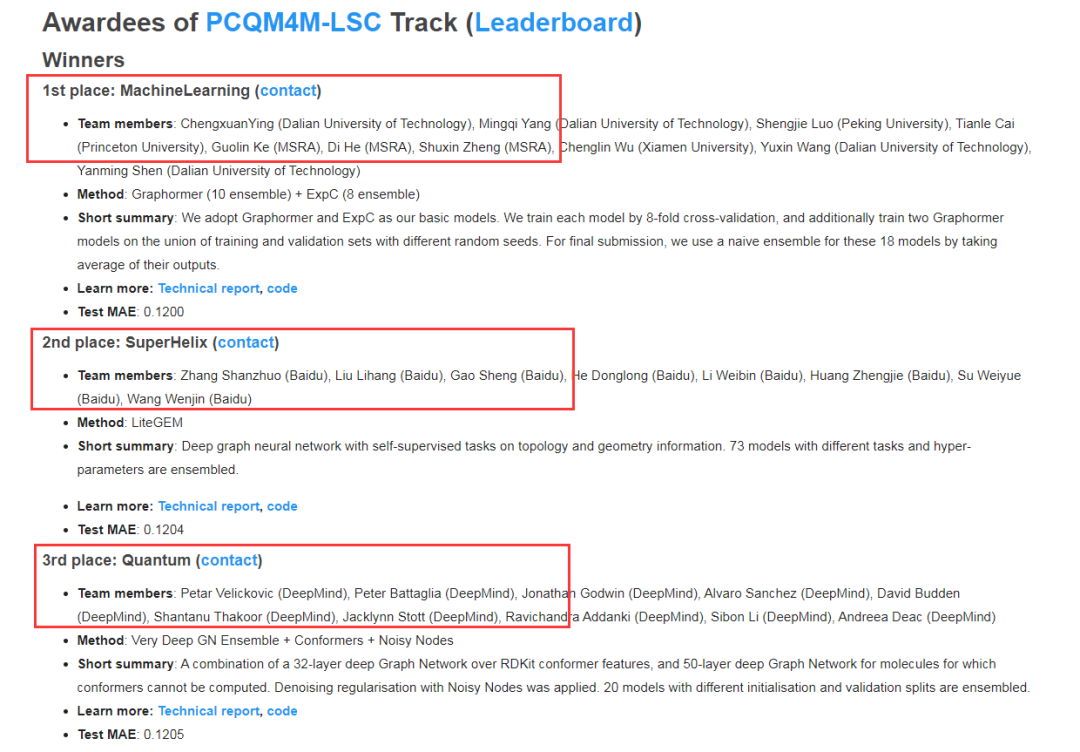
在此次比赛中,与其他队伍基于图神经网络的解决方案不同,来自MSRA机器学习组的研究员和实习生们直接使用 Transformer 模型对分子图数据进行处理,并力压DeepMind、百度、阿里巴巴蚂蚁金服等强劲对手,取得第一名的佳绩。
以下是该赛道榜单排名:
Transformer模型最早在NLP任务中被使用,并且逐渐在Speech、CV等任务中成为主流。然而,在图学习的领域各项任务的排行榜上,依然是传统图神经网络占据着主流。
但是谁又规定一定得是图神经网络才能做图学习呢?

所以说有意思的来了,在大连理工大学,普林斯顿大学,北京大学及微软亚洲研究院最新的论文《Do Transformers Really Perform Bad for Graph Representation?》中,研究人员们证明了Transformer实际上是表达能力更强的图神经网络,并且主流的图神经网络模型(GCN, GIN, GraphSage)可以看作是Transformer的特例!

论文地址:https://arxiv.org/abs/2106.05234
然而,过往将Transformer模型用到图结构数据的工作,表现并不尽人意,公认的图预测任务排行榜上依旧被传统GNN的变种们霸占着。
例如,此前最大的有标注图预测数据集OGBG-MolPCBA任务要求给定化学分子结构预测其60余种性质。在OGBG-MolPCBA的排行榜上并没有Transformer的身影。
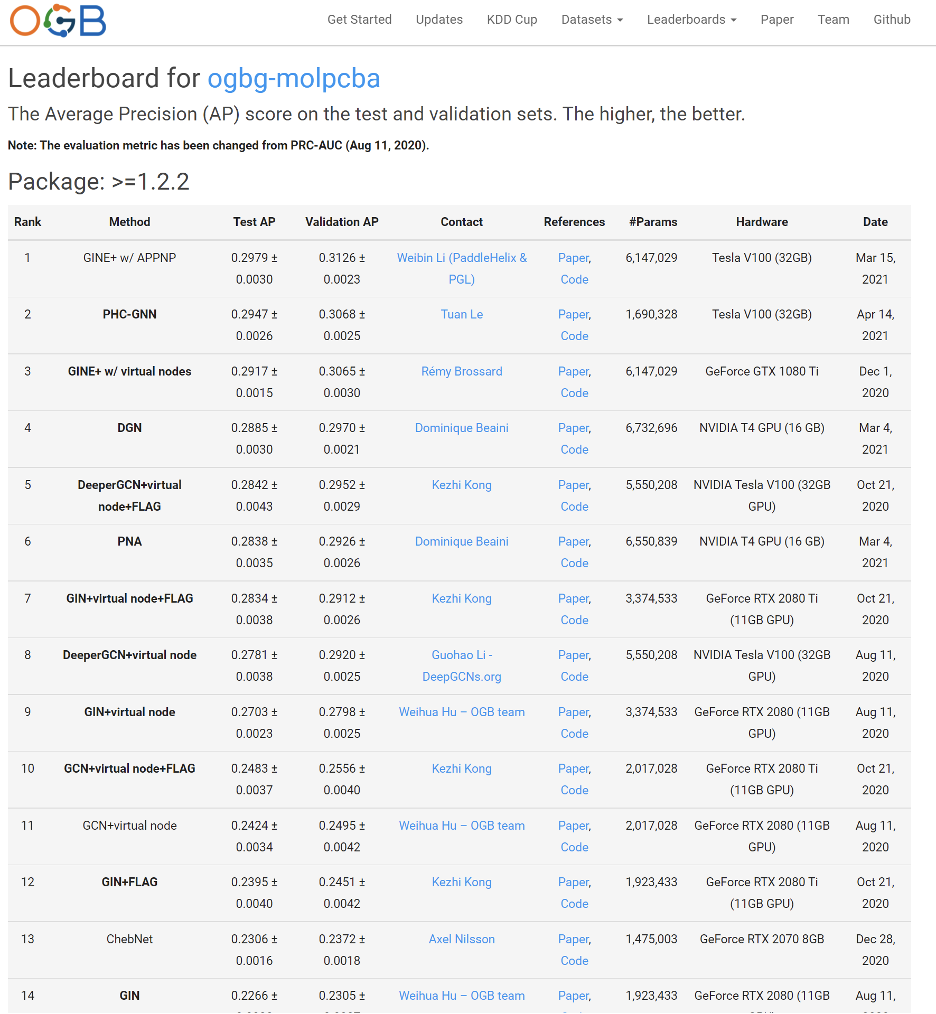
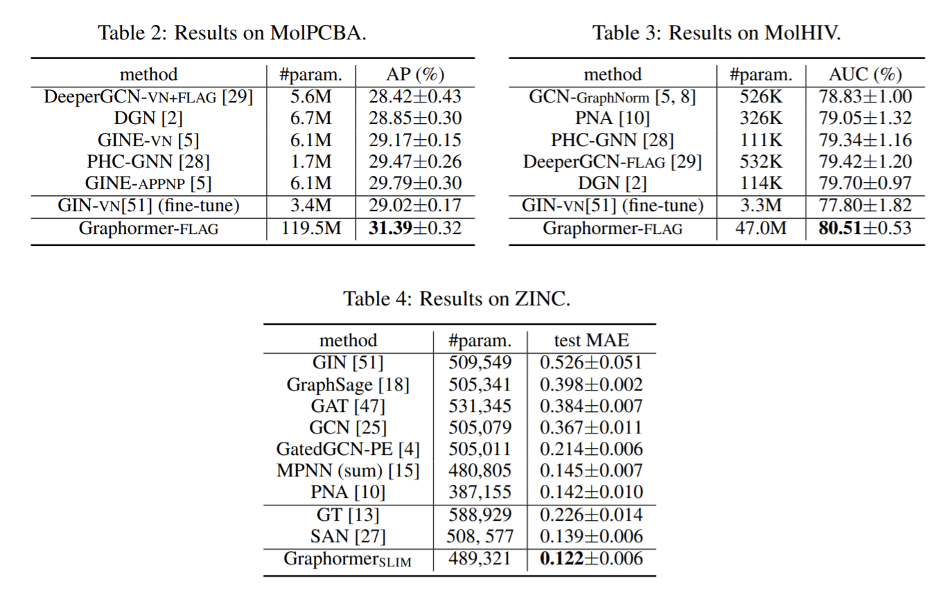
此前最好的结果来自于GINE,在测试集上的AP指标为29.79%,而MSRA的研究人员和实习生们将Transformer模型应用到此数据集后,得到了31.39%的AP准确率。同时本次工作的研究人员们也在其他多个图预测排行榜中(OGB-LSC, OGB, Benchmarking-GNN)取得了最优成绩。
那么将Transfomer成功应用于图数据的关键难点在哪里呢?
作者们发现关键问题在于如何补回Transformer模型的自注意力层丢失掉的图结构信息!不同于序列数据(NLP, Speech)或网格数据(CV),图的结构信息是图数据特有的属性,且对图的性质预测起着重要的作用。
基于此,研究人员们在图预测任务上提出了Graphormer模型 —— 一个标准的Transformer模型,并且带有三种结构信息编码(中心性编码Centrality Encoding、空间编码Spatial Encoding以及边编码Edge Encoding),帮助Graphormer模型编码图数据的结构信息。
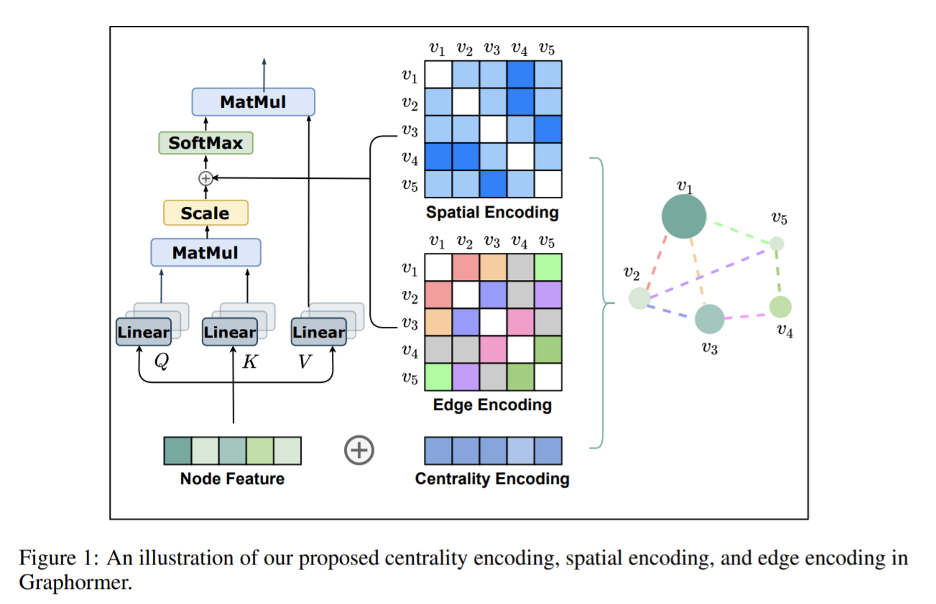
具体来讲,将Transformer模型应用到图数据时,其最主要的运算集中在自注意力层计算节点特征之间的相关性作为注意力机制的权重。然而对于图数据来说,衡量节点之间相关性的因素并不仅仅取决于节点特征,还包括了节点自身在图结构中的重要性(如社交网络中的名人节点),节点之间的空间关系(如六度空间理论)以及节点之间连边的特征(如边的距离、边的流量等)。
因此,MSRA的研究人员们在Graphormer模型中为以上几种信息设计了简洁而高效的编码来表示图数据的结构信息,并在自注意力层计算相关权重时引入三种结构编码,由此成功的将Transformer结构应用到了图数据上。
更多内容细节可以参看原论文。
AI科技评论一向是国内报道 AI 学术科技前沿最早的媒体,这次也不会落后,为了弄清楚这个Graphormer模型背后都有哪些故事,我们编辑部特地联系并专访到了此次比赛MSRA团队的负责人——主管研究员郑书新博士。
AI科技评论:首先恭喜你们夺冠,能简单介绍一下Graphormer模型诞生的始末吗?你们从什么时候开始研究图神经网络的?
郑书新:非常感谢,取得最终的成绩离不开每一位队员的努力,以及很多朋友们的帮助。其实以前我们并不做GNN,相反Transformer和预训练做的多一些,但其实把Transformer应用到图数据的想法很早就有了。
在我们最新一篇PLP(Programming Language Processing)方向的ICML2021论文《How could Neural Networks understand Programs?》中,我们观察到一个很有意思的现象:
因为程序语言是天然具有两种结构的数据,即序列数据(程序文本)及图数据(控制流图等),因此在尝试理解程序语义时,研究人员们很明显地分为了两派:Transformer流派和GNN流派。Transformer流派的好处在于模型强大的表达能力,而GNN流派的优势在于可以捕捉图上的结构信息。
所以为了博采众长,我们当时采用的做法是使用Transformer模型,并设计了控制流编码来引入程序的图结构信息。
AI科技评论:你们是如何参与到这场比赛中的呢?
郑书新:参加KDD Cup也非常偶然。我记得在比赛注册截止日前几天,我们的一位实习生同学应承轩跑来跟我讲想参加这次的比赛,并用Transformer模型来做分子性质预测。
当时觉得虽然这次的比赛赛题很难,并且我们在图数据上的经验着实不算多,但考虑到此次比赛的题目很有实际的应用价值,我们一拍即合,当即开始组队报名参加比赛 (此处给承轩同学打个广告 ,他希望今年能申请到机器学习方向尤其是图数据方向的博士学位攻读)。
,他希望今年能申请到机器学习方向尤其是图数据方向的博士学位攻读)。
AI科技评论:祝承轩同学申请到心仪的实验室。请问如何理解 Transformer实际上是表达能力更强的图神经网络?以及主流的图神经网络模型(GCN, GIN, GraphSage)可以看作是Transformer的特例?
郑书新:上文已经对graphormer做了一定介绍,此外,我们还发现,在使用了结构编码后,当为模型选择适当的参数时,Transformer就可以表示主流的图神经网络,既GCN, GIN, GraphSage等可以看作Transformer的特例。
例如,令邻居节点的空间编码为0,其余节点的空间编码为负无穷,并让W_Q=W_K=0,W_K为单位矩阵,那么自注意力层的Softmax操作就可以恢复GNN中的MEAN aggregation操作。
AI科技评论:Graphormer是为了分子性质预测任务专门设计的吗?在其他领域有哪些应用?
郑书新:并不是。Graphormer中应用到的structural encodings都具有一般性,可以在任何一种图数据中应用。分子性质预测本身是非常有应用价值的问题,是很多前沿、热门领域的基础问题,例如药物分子发现、新型材料等等、蛋白质分子建模等等。此外,图数据的应用也广泛存在在我们的生活中,例如社交网络、知识图谱、时空预测、程序理解、自动驾驶点云等等,我们也期待Graphormer能在这些领域有所建树,大放异彩。
AI科技评论:此次你们在分子性质预测使用的数据集PCQM4M-LSC上夺冠的分数为0.1200 MAE,这是一个很好的分数吗?可以说GNN已经取代量子化学的方法了吗?
郑书新:还远远远远没有到取代的地步,还有很长的路要走。
这次比赛的单位是eV (电子伏),目前对于给定分子2D结构预测HOMO-LUMO energy gap 的误差最低能达到0.12eV左右,而给定DFT计算的3D结构能达到0.01eV左右。
虽然基于人工智能的方法可以让很多应用例如药物发现、材料发现等的过程大幅加速,但更多的还处在粗筛、辅助层面。而真正要取代传统的计算化学方法如DFT等,则至少要达到化学精度1kcal/mol = 0.043eV 左右(即通过化学实验计算方法也会存在的误差)。因此,从0.12eV到0.043eV还有很长的路要走。
不过就像CNN在ImageNet比赛中第一次崭露头角(2012年)一样,经过了学术界近十年的努力,ImageNet的Top 1 准确率已经从60%提升到了今天的90%。我相信,在学术圈的共同努力推动下,人工智能算法在计算化学、计算物理、可持续发展等众多交叉学科领域中将会扮演越来越重要的角色!
至此,Transformer自统治了NLP、Speech 与CV后,又在Graph数据上取得了惊人的效果。所以,Transformer在Graph上的应用前景有可能取代GNN吗?
作者也在文章最后指出了未来Transformer在图数据上应用需解决的一些问题,包括如何降低Graphormer的时间复杂度等。
这一点至于未来究竟如何,让我们拭目以待~
但是,文章之外,笔者真的想吐槽一句:Transformer ,求求你做个人吧!

看到Transformer这次在图领域取得了巨大成功,卷积&MLP模型又会在之后来凑一波热闹吗?
卷积&MLP模型内心会不会想对Transformer说一句:杀掉你, 我上我也行 

从局外人的角度说一句,兄弟模型们,格局要大啊,AI早晚会大一统的。

最后说一下本论文已开源且有视频讲解,如下:
代码地址:https://github.com/microsoft/Graphormer
视频讲解:https://www.youtube.com/watch?v=xQ5ltOOxoFg
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
