
记一次 Netty 堆外内存泄露排查过程
这篇文章对于排查使用了 netty 引发的堆外内存泄露问题,有一定的通用性,希望对你有所启发
背景
最近在做一个基于 websocket 的长连中间件,服务端使用实现了 socket.io 协议(基于websocket协议,提供长轮询降级能力) 的 netty-socketio 框架,该框架为 netty 实现,鉴于本人对 netty 比较熟,并且对比同样实现了 socket.io 协议的其他框架,这个框架的口碑要更好一些,因此选择这个框架作为底层核心。
任何开源框架都避免不了 bug 的存在,我们在使用这个开源框架的时候,就遇到一个堆外内存泄露的 bug,鉴于对 netty 比较熟,于是接下来便想挑战一下,找出那只臭虫(bug),接下来便是现象和排查过程,想看结论的同学可以直接拉到最后总结。
现象
某天早上突然收到告警,nginx 服务端大量5xx

我们使用 nginx 作为服务端 websocket 的七层负载,5xx爆发通常表明服务端不可用。由于目前 nginx 告警没有细分具体哪台机器不可用,接下来,到 cat(点评美团统一监控平台)去检查一下整个集群的各项指标,发现如下两个异常
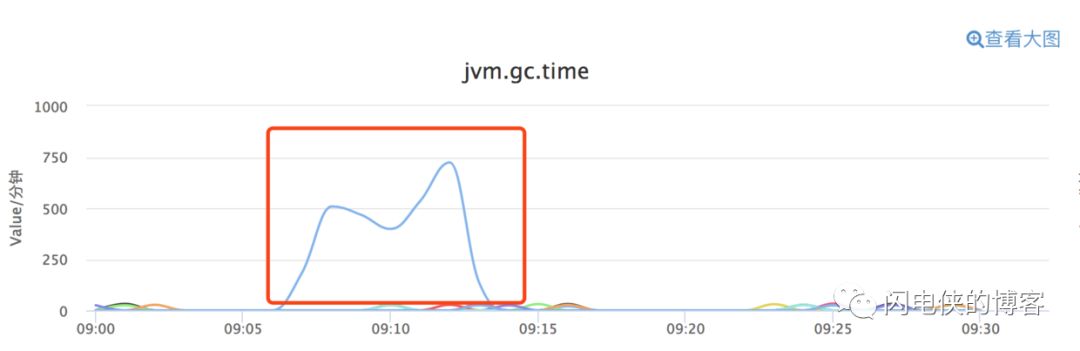
某台机器在同一时间点爆发 gc,同一时间,jvm 线程阻塞

接下来,便开始漫长的 堆外内存泄露排查之旅行。
排查过程
阶段1: 怀疑是log4j2
线程被大量阻塞,首先想到的是定位哪些线程被阻塞,最后查出来是 log4j2 狂打日志导致 netty 的 nio 线程阻塞(由于没有及时保留现场,所以截图缺失),nio 线程阻塞之后,我们的服务器无法处理客户端的请求,对nginx来说是5xx。
接下来,查看 log4j2 的配置文件
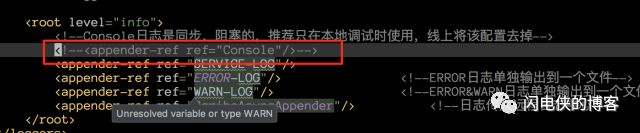
发现打印到控制台的这个 appender 忘记注释掉了,所以我初步猜测是因为这个项目打印的日志过多,而 log4j2 打印到控制台是同步阻塞打印的,接下来,把线上所有机器的这行注释掉,以为大功告成,没想到,过不了几天,5xx告警又来敲门了,看来,这个问题没那么简单。
阶段2:可疑日志浮现
接下来,只能硬着头皮去查日志,查看故障发生点前后的日志,发现了一处可疑的地方
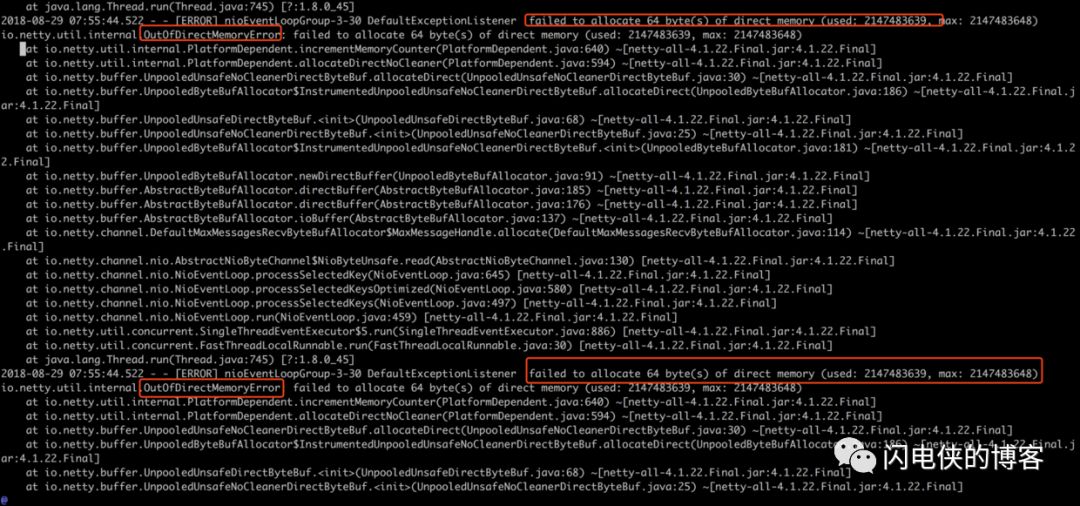
在极短的时间内,狂打 failed to allocate64(bytes)of direct memory(...)日志(瞬间十几个日志文件,每个日志文件几百M),日志里抛出一个 netty 自己封装的 OutOfDirectMemoryError,说白了,就是堆外内存不够用了,netty 一直在喊冤。
堆外内存泄露,我去,听到这个名词就有点沮丧,因为这个问题的排查就像 c 语言内存泄露一样难以排查,首先想到的是,在 OOM 爆发之前,查看有无异常,然后查遍了 cat 上与机器相关的所有指标,查遍了 OOM 日志之前的所有日志,均未发现任何异常!这个时候心里开始骂了……
阶段3:定位OOM源
但是没办法,只能看着这堆讨厌的 OOM 日志发着呆,妄图答案能够蹦到眼前。一筹莫展之际,突然一道光在眼前一闪而过,在 OOM 下方的几行日志变得耀眼起来(为啥之前就没想认真查看日志?估计是被堆外内存泄露这几个词吓怕了吧==),这几行字是 ....PlatformDepedeng.incrementMemory()...。我去,原来,堆外内存是否够用,是 netty 这边自己统计的,那是不是可以找到统计代码,找到统计代码之后我们就可以看到 netty 里面的对外内存统计逻辑了?于是,接下来翻翻代码,找到这段逻辑,在 PlatformDepedent 这个类里面
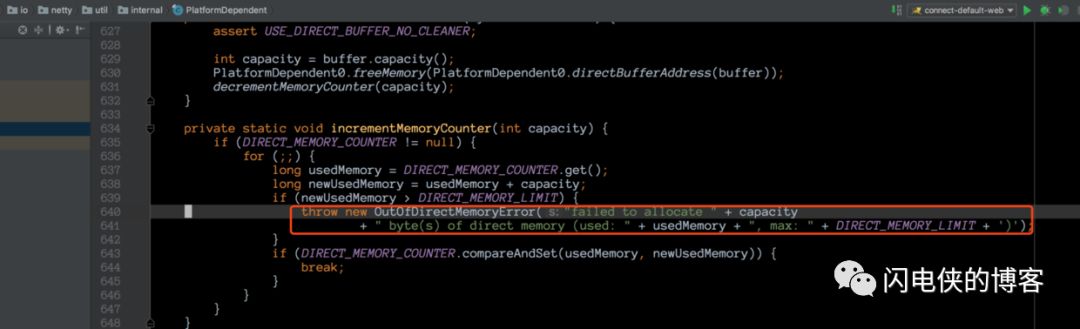
这个地方,是一个对已使用堆外内存计数的操作,计数器为 DIRECT_MEMORY_COUNTER,如果发现已使用内存大于堆外内存的上限(用户自行指定),就抛出一个自定义 OOM Error,异常里面的文本内容正是我们在日志里面看到的。
接下来,验证一下是否这个函数是在堆外内存分配的时候被调用
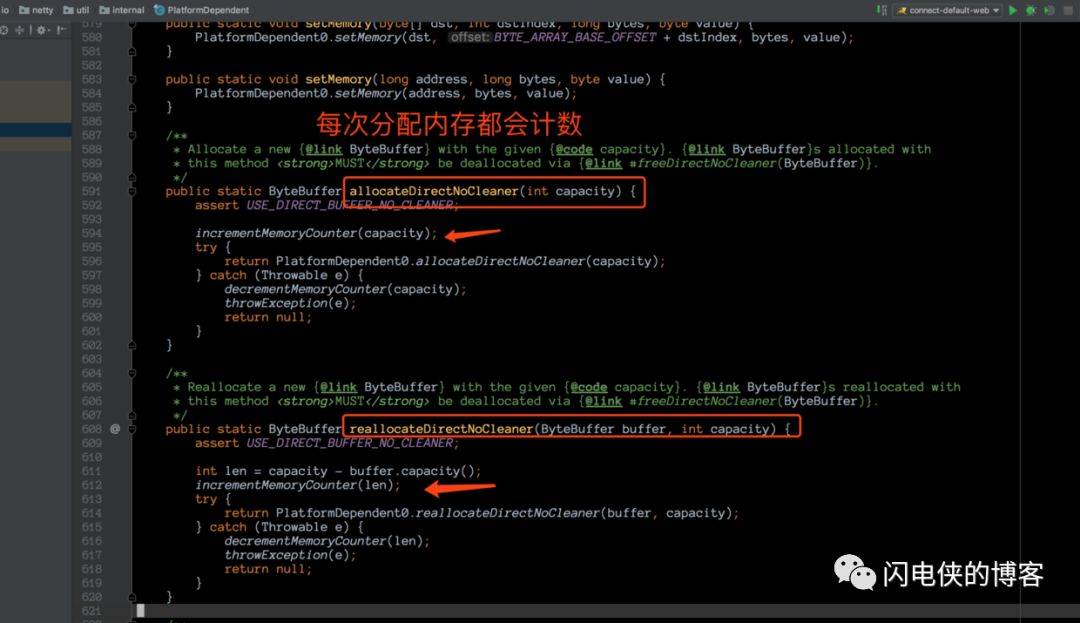
果然,在 netty 每次分配堆外内存之前,都会计数,想到这,思路开始慢慢清晰起来,心情也开始变好。
阶段4:反射进行堆外内存监控
既然 cat 上关于堆外内存的监控没有任何异常(应该是没有统计准确,一直维持在 1M),而这边我们又确认堆外内存已快超过上限,并且已经知道 netty 底层是使用哪个字段来统计的,那么接下来要做的第一件事情,就是反射拿到这个字段,然后我们自己统计 netty 使用堆外内存的情况。

堆外内存统计字段是 DIRECT_MEMORY_COUNTER,我们可以通过反射拿到这个字段,然后定期check这个值,就可以监控 netty 堆外内存的增长情况。

我们通过反射拿到这个字段,然后每隔一秒打印,我为什么要这样做?
因为,通过我们前面的分析,在爆发大量 OOM 现象之前,没有任何可疑的现象,那么只有两种情况,一种是突然某个瞬间分配了大量的堆外内存导致OOM,一种是堆外内存缓慢增长,到达某个点之后,最后一根稻草将机器压垮。这段代码加上去之后,打包上线。
阶段5:到底是缓慢增长还是瞬间飙升?
代码上线之后,初始内存为 16384k(16M),这是因为线上我们使用了池化堆外内存,默认一个 chunk 为16M,不必过于纠结。

没过一会,内存就开始缓慢飙升,并且没有释放的迹象,20几分钟之后,内存如下
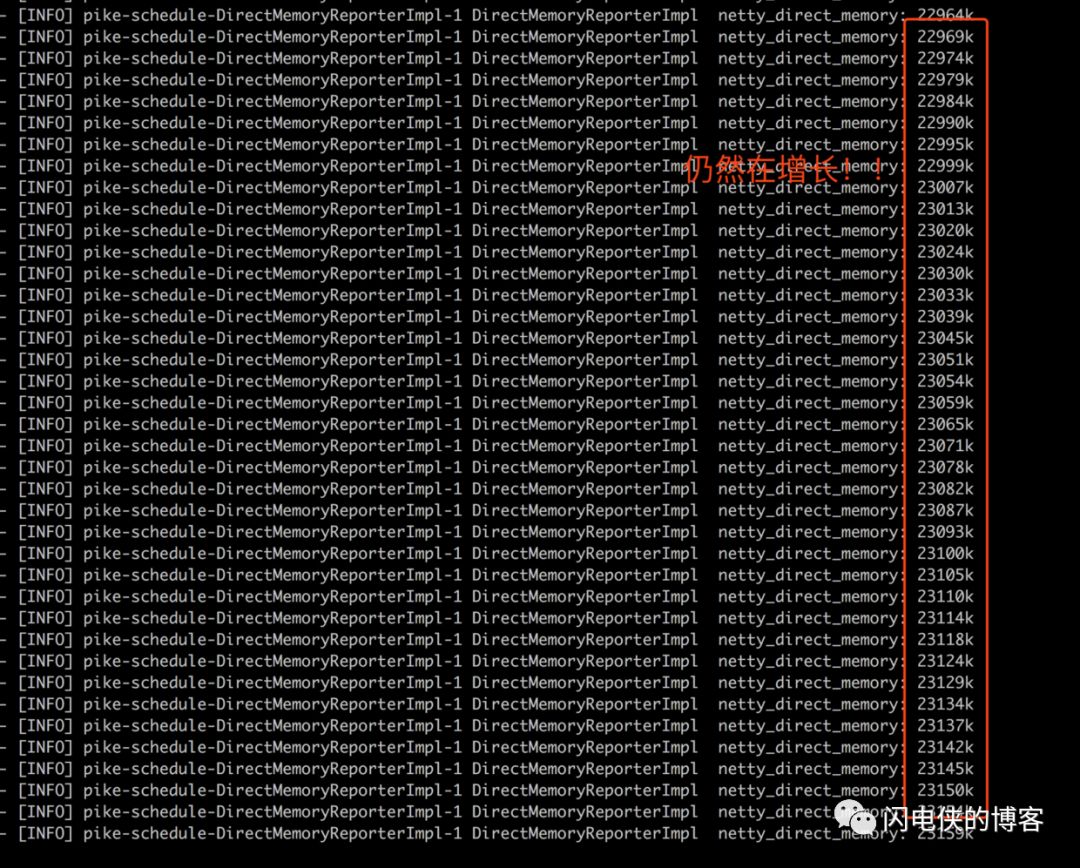
到了这里,猜测可能是前面提到的第二种情况,也就是内存缓慢增长造成的 OOM,由于内存实在增长太慢,于是调整机器负载权重为其他机器的两倍,但是仍然是以几K级别在增长,这天刚好是周五,索性就过他个一个周末再开看。
过完一个愉快的周末之后,到公司第一时间便是连上跳板机,登录线上机器,开始 tail -f 继续查看日志,输完命令之后,怀着期待的心情重重的敲下了回车键
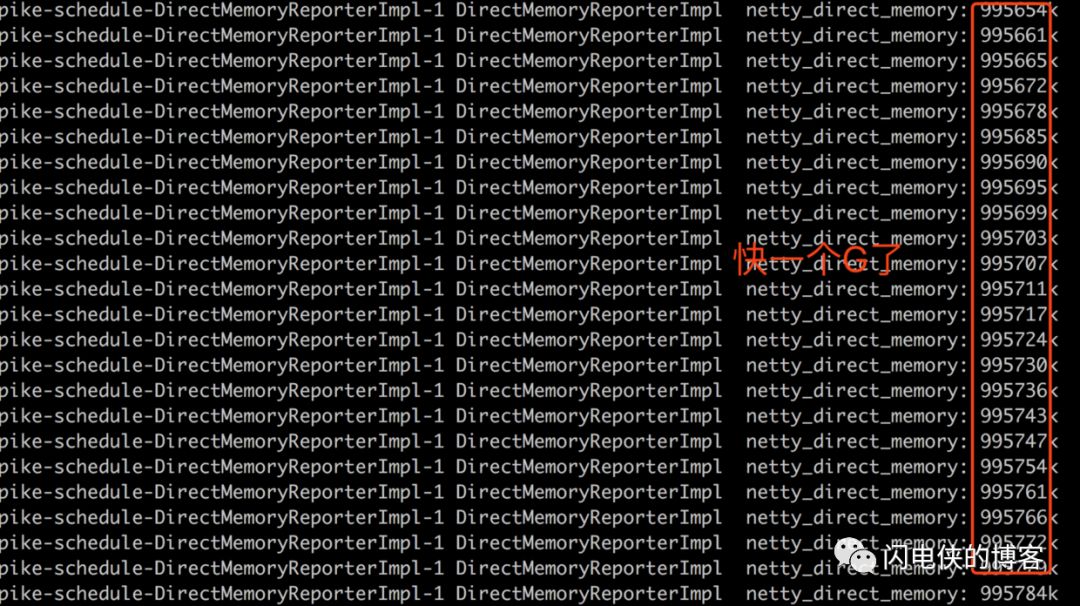
果然不出所料,内存一直在缓慢增长,一个周末的时间,堆外内存已经飙到快一个 G 了,这个时候,我竟然想到了一句成语:只要功夫深,铁杵磨成针!虽然堆外内存几个K几个K的在增长,但是只要一直持续下去,总有把内存打爆的时候(线上堆外内存上限设置的是2G)。
到了这里,我又开始自问自答了:内存为啥会缓慢增长,伴随着什么而增长?因为我们的应用是面向用户端的websocket,那么,会不会是每一次有用户进来,交互完之后,然后离开,内存都会增长一些,然后不释放呢?带着这个疑问,我开始线下模拟。
阶段6:线下模拟
本地起好服务,把监控堆外内存的单位改为以B为单位(因为本地流量较小,打算一次一个客户端连接),另外,本地也使用非池化内存(内存数字较小,容易看出问题),这样,服务端启动之后,控制台打印信息如下
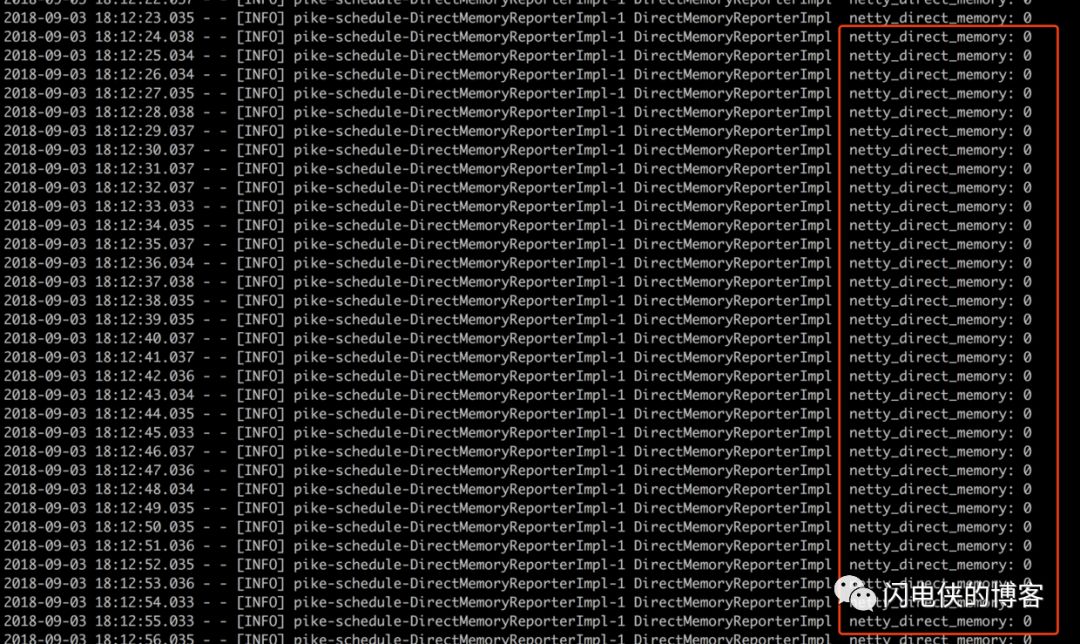
在没有客户端接入的时候,堆外内存一直是0,在意料之中。接下来,怀着着无比激动的心情,打开浏览器,然后输入网址,开始我们的模拟之旅。
我们的模拟流程是:新建一个客户端链接->断开链接->再新建一个客户端链接->再断开链接
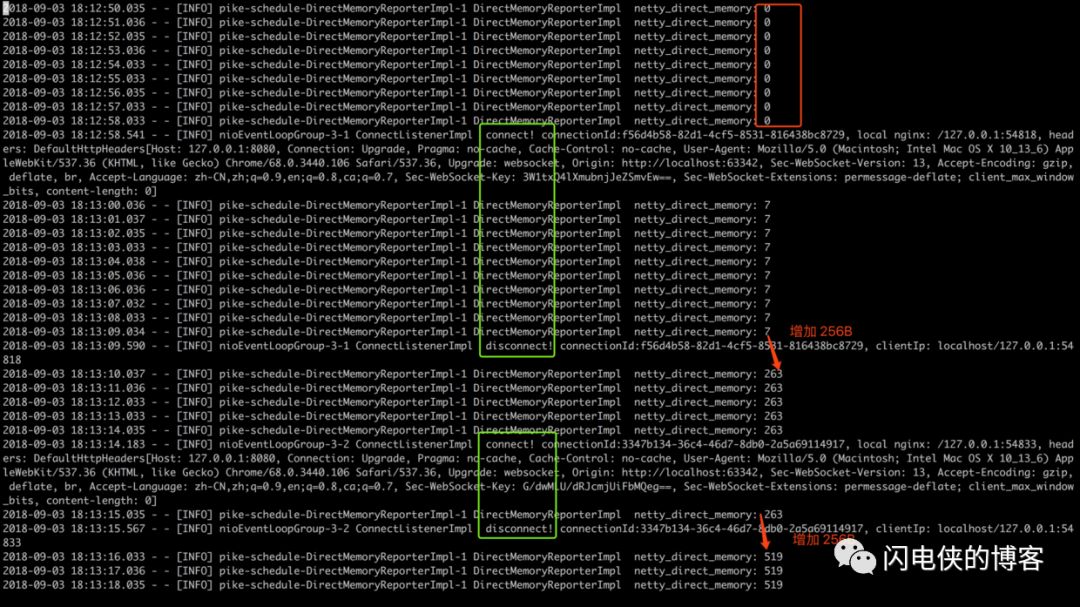
如上图所示,一次 connect 和 disconnect 为一次连接的建立与关闭,上图绿色框框的日志分别是两次连接的生命周期。我们可以看到,内存每次都是在连接被关闭的的时候暴涨 256B 然后不释放,到了这里,问题进一步缩小,肯定是连接被关闭的时候,触发了框架的一个bug,这个bug在触发之前分配了 256B 的内存,然后bug触发,内存没有释放。问题缩小之后,接下来开始撸源码捉虫!
阶段7:线下排查
接下来,我将本地服务重启,开始完整的线下排查过程。将目光定位到 netty-socketio 这个框架的 disconnect 事件(客户端websocket连接关闭的时候回调用到这里),基本上可以确定是在 disconnect 事件前后申请的内存没有释放
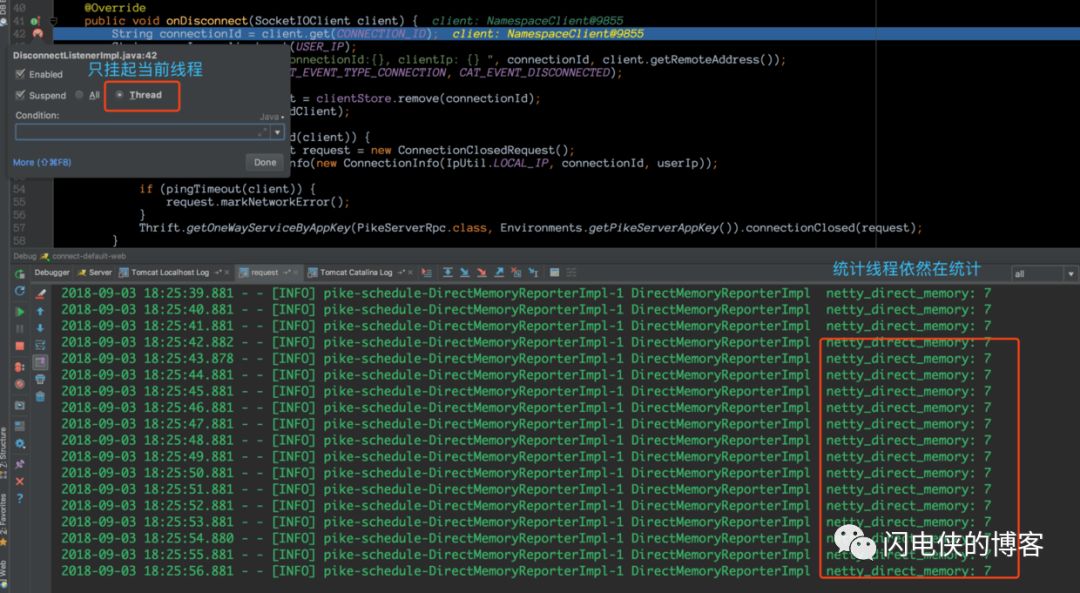
这里,在使用 idea debug的时候,要选择只挂起当前线程,这样我们在单步跟踪的时候,控制台仍然可以看到堆外内存统计线程在打印日志。
客户端连接上之后然后关闭,断点进入到 onDisconnect 回调,我特意在此多停留了一会,发现控制台内存并没有飙升(7B这个内存暂时没有去分析,只需要知道,客户端连接断开之后,我们断点hold住,内存还未开始涨),接下来,神奇的一幕出现了,我将断点放开,让程序跑完
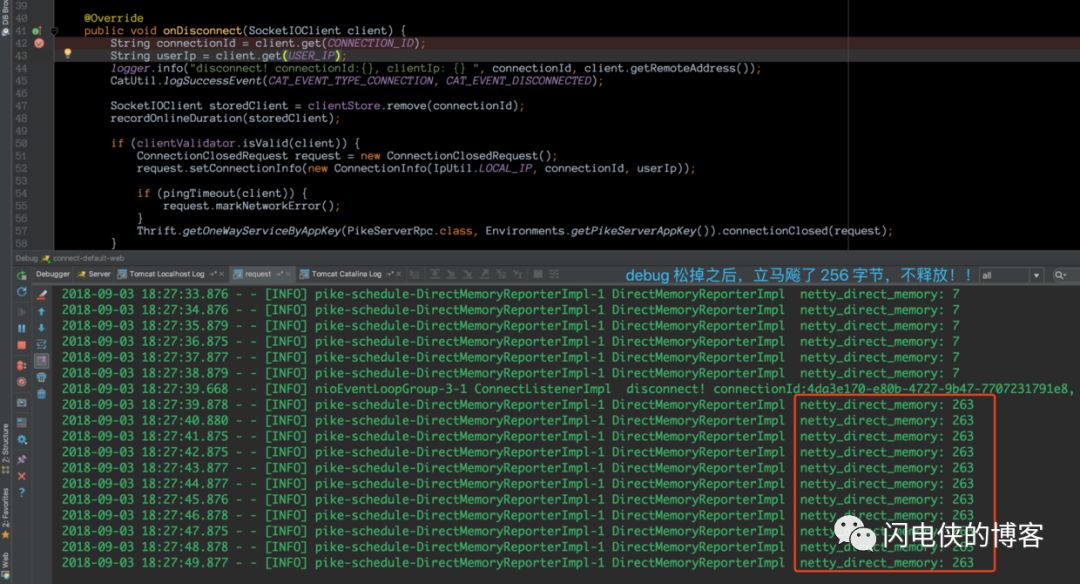
debug 松掉之后,内存立马飙升了!!这个时候我已经知道,这只臭虫飞不了多远了。在 debug 的时候,挂起的是当前线程,那么肯定是当前线程某个地方申请了堆外内存,然后没有释放,接下来,快马加鞭,深入源码。
每一次单步调试,我都会观察控制台的内存飙升的情况,很快,我们来到了这个地方

在这一行没执行之前,控制台的内存依然是 263B,然后,当执行完这一行之后,立马从 263B涨到519B(涨了256B)
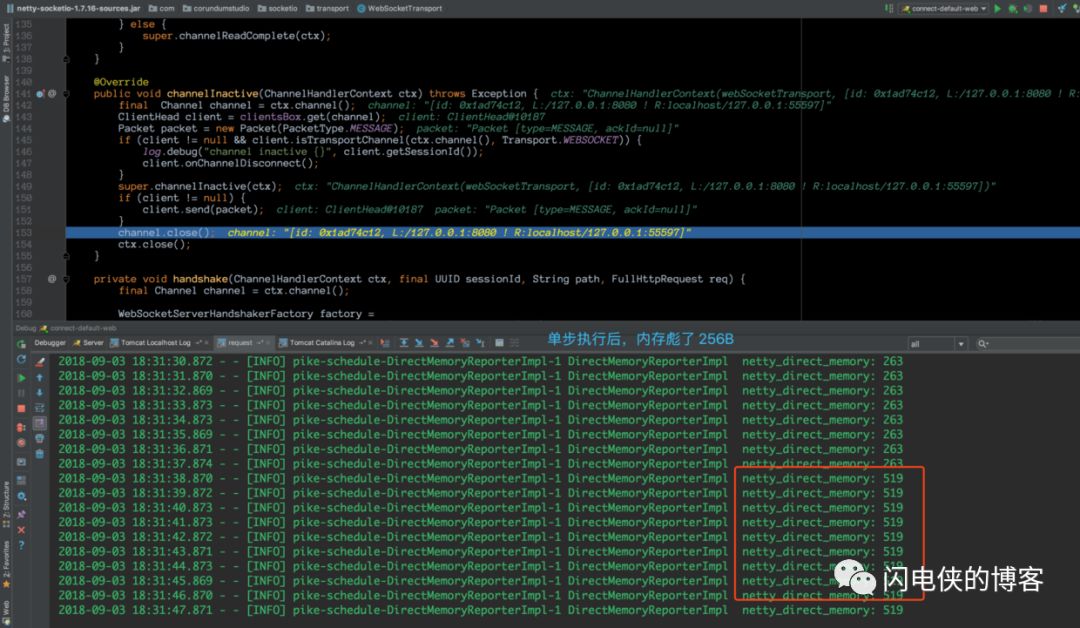
于是,bug的范围进一步缩小,我将本次程序跑完,释然后客户端再来一次连接,断点打在 client.send()这行, 然后关闭客户端连接,之后直接进入到这个方法,随后的过程有点长,因为与 netty 的时间传播机制有关,这里就省略了,最后,我跟到了如下代码, handleWebsocket
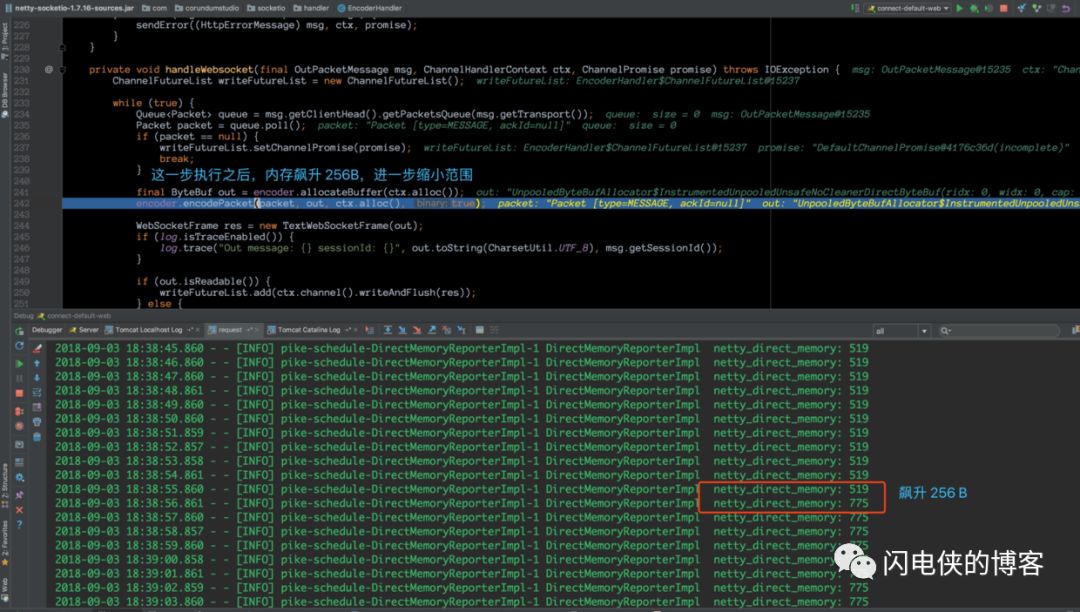
在这个地方,我看了一处非常可疑的地方,在上图的断点上一行,调用 encoder 分配了一段内存,调用完之后,我们的控制台立马就彪了 256B,所以,我怀疑肯定是这里申请的内存没有释放,他这里接下来调用 encoder.encodePacket() 方法,猜想是把数据包的内容以二进制的方式写到这段 256B的内存,接下来,我跟到这段 encode 代码,单步执行之后,定位到这行代码
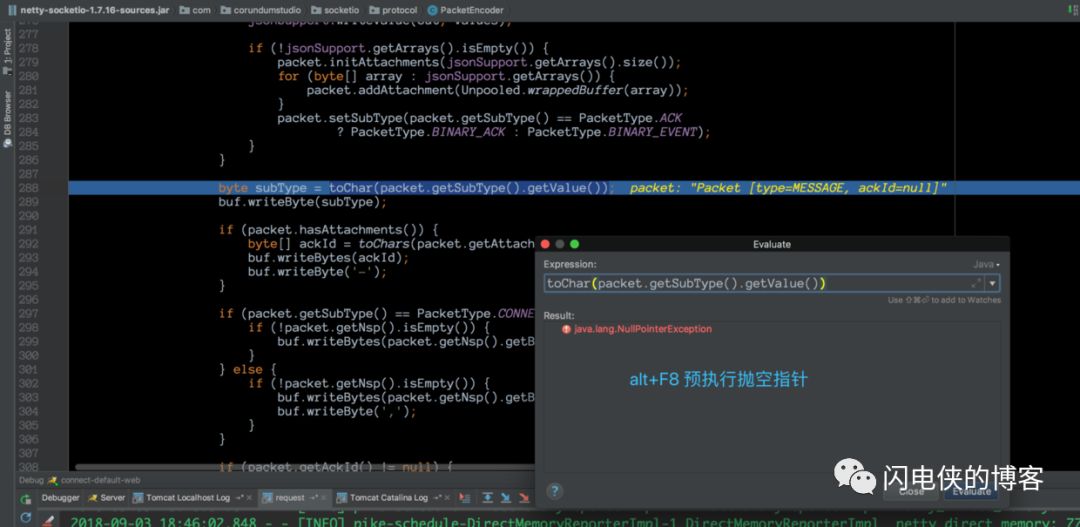
这段代码是把 packet 里面一个字段的值转换为一个 char,然而,当我使用 idea 预执行的时候,却抛出类一个愤怒的 NPE!!也就是说,框架申请到一段内存之后,在encoder的时候,自己GG了,自己给自己挖了个NPE的深坑,最后导致内存无法释放(最外层有堆外内存释放逻辑,现在无法执行到了),然后越攒越多,越攒越多,直到最后一根稻草,堆外内存就这样爆了,这里的源码有兴趣的读者可以自己去分析一下,限于篇幅原因,这里就不再分析了。
阶段8:bug解决
bug既然已经找到,接下来便要解决了,这里只需要解决这个NPE异常,就可以fix掉,我们的目标就是,让这个 subType 字段不为空,我们先通过 idea 的线程调用栈定位到这个 packet 是在哪个地方定义的
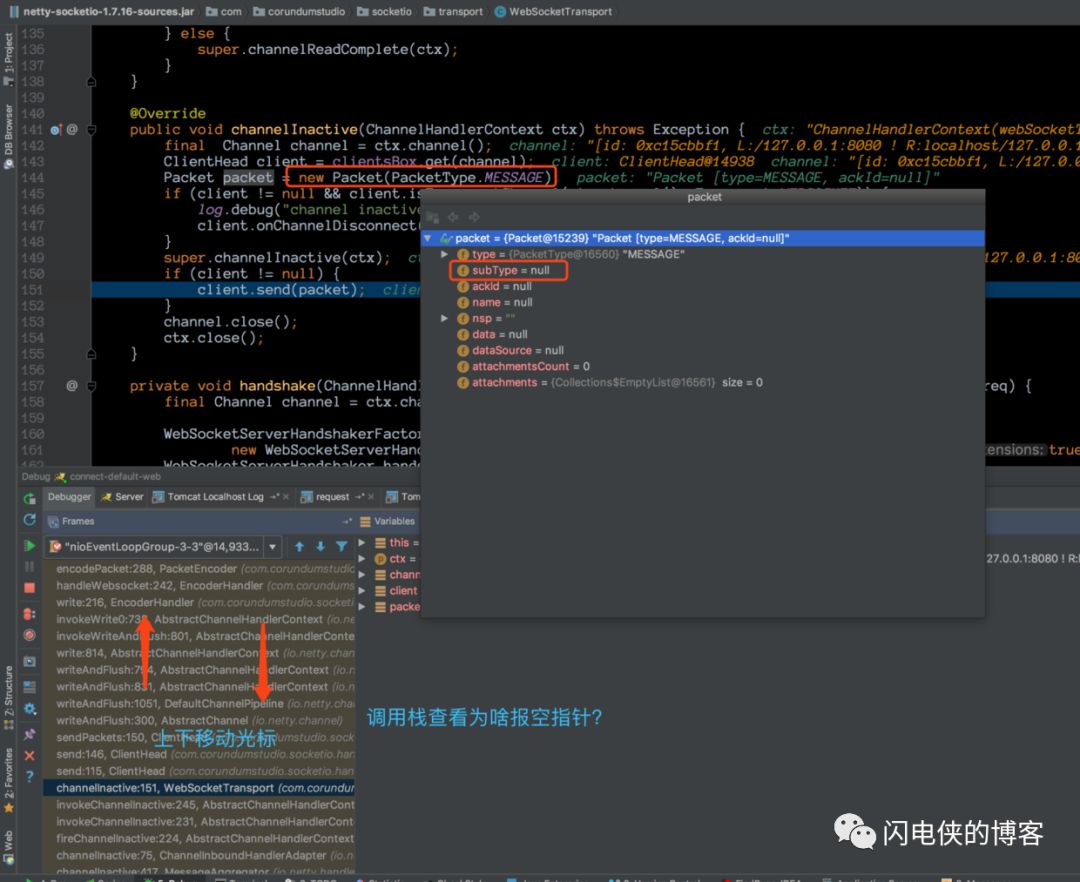
我们找到 idea 的 debugger 面板,眼睛盯着 packet 这个对象不放,然后上线移动光标,便光速定位到,原来,定义 packet 对象这个地方在我们前面的代码其实已经出现过,我们查看了一下 subType 这个字段,果然是null,接下来,解决bug很容易。
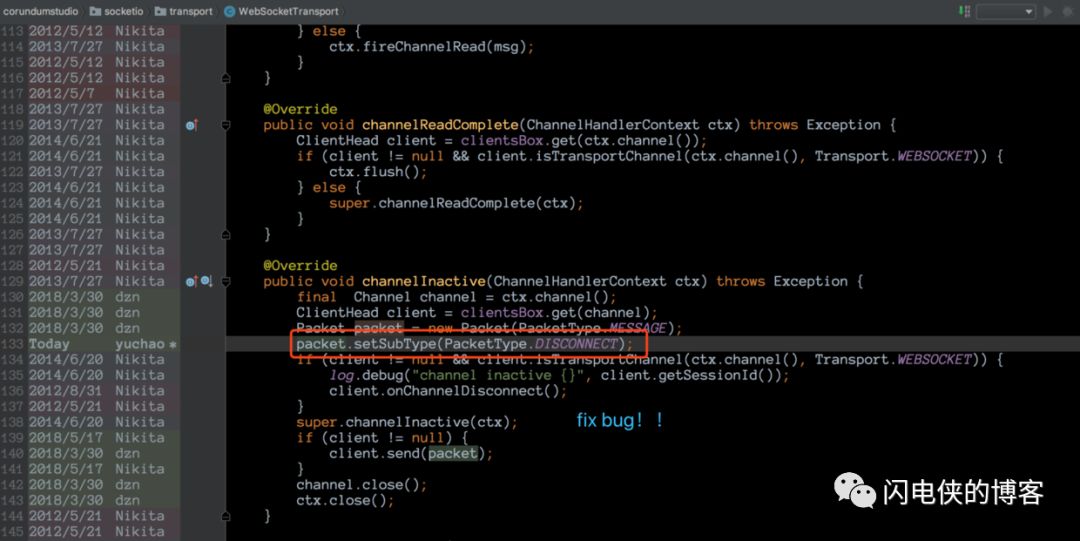
我们给这个字段赋值即可,由于这里是连接关闭事件,所以,我给他指定了一个名为 DISCONNECT 的字段(改日深入去研究socket.io的协议),反正这个bug是在连接关闭的时候触发的,就粗暴一点了 !==。
解决这个bug的过程是:将这个框架的源码下载到本地,然后加上这一行,最后,我重新build一下,pom 里改改名字,推送到我们公司的仓库,这样,我项目就可以直接使用了。
改完bug之后,习惯性地去github上找到引发这段bug的commit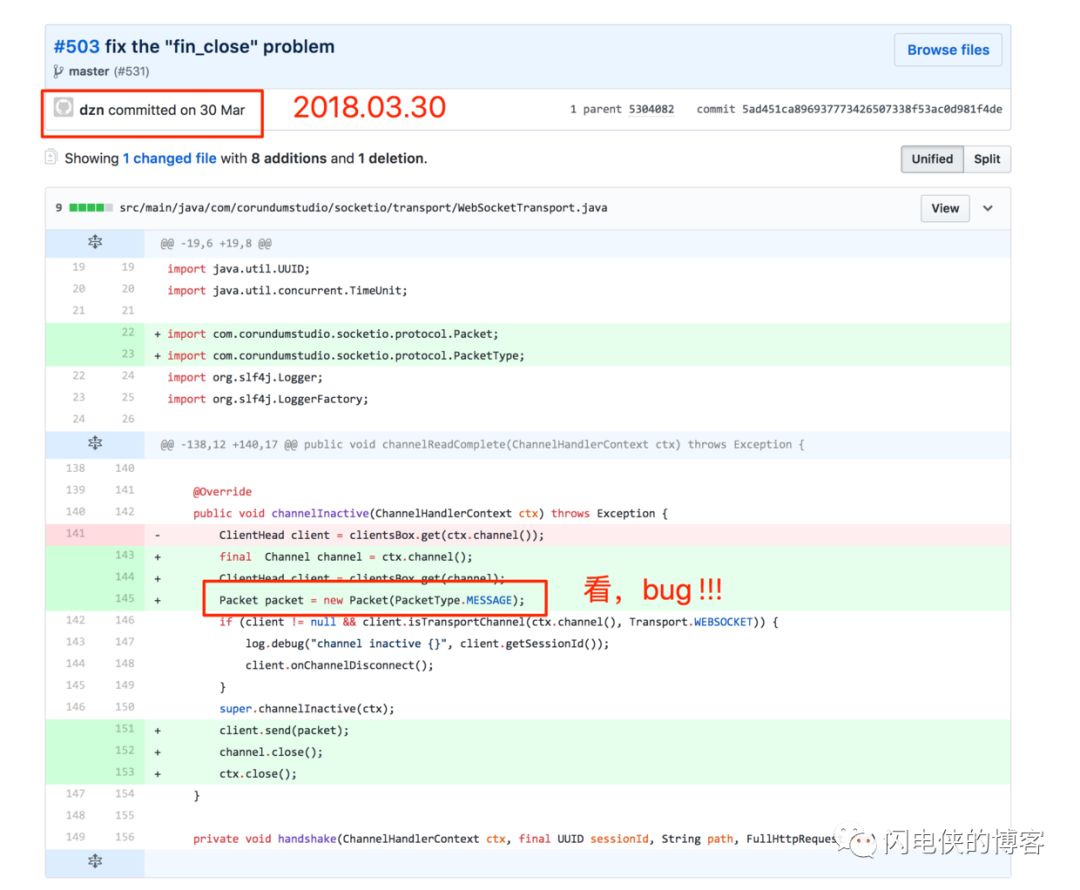 好奇的是,为啥这位
好奇的是,为啥这位 dzn commiter 会写出这么一段如此明显的bug,而且时间就在今年3月30号,项目启动的前夕,真是无比尴尬呀 😂
阶段9:线下验证
一切就绪之后,首先,我们来进行本地验证,服务起起来之后,我疯狂地建立连接,疯狂地断开连接,观察堆外内存的情况
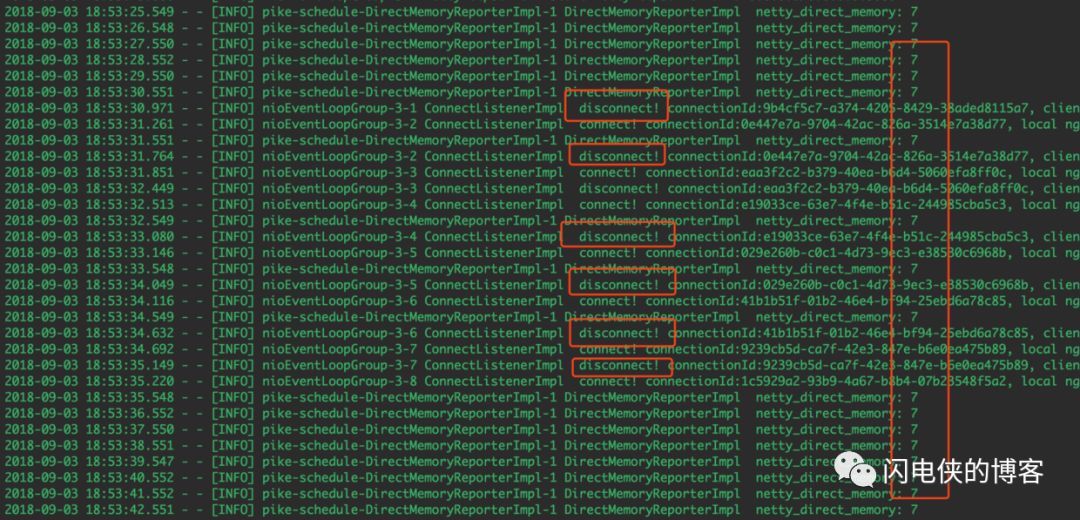
好家伙,不管你如何断开连接,堆外内存一直不涨了,至此,bug 基本fix,当然,最后一步,我们把代码推到线上验证。
阶段10:线上验证
这次线上验证,我们避免了比较土的打日志方法,我们把堆外内存的这个指标喷射到 cat上,然后再来观察一段时间的堆外内存的情况
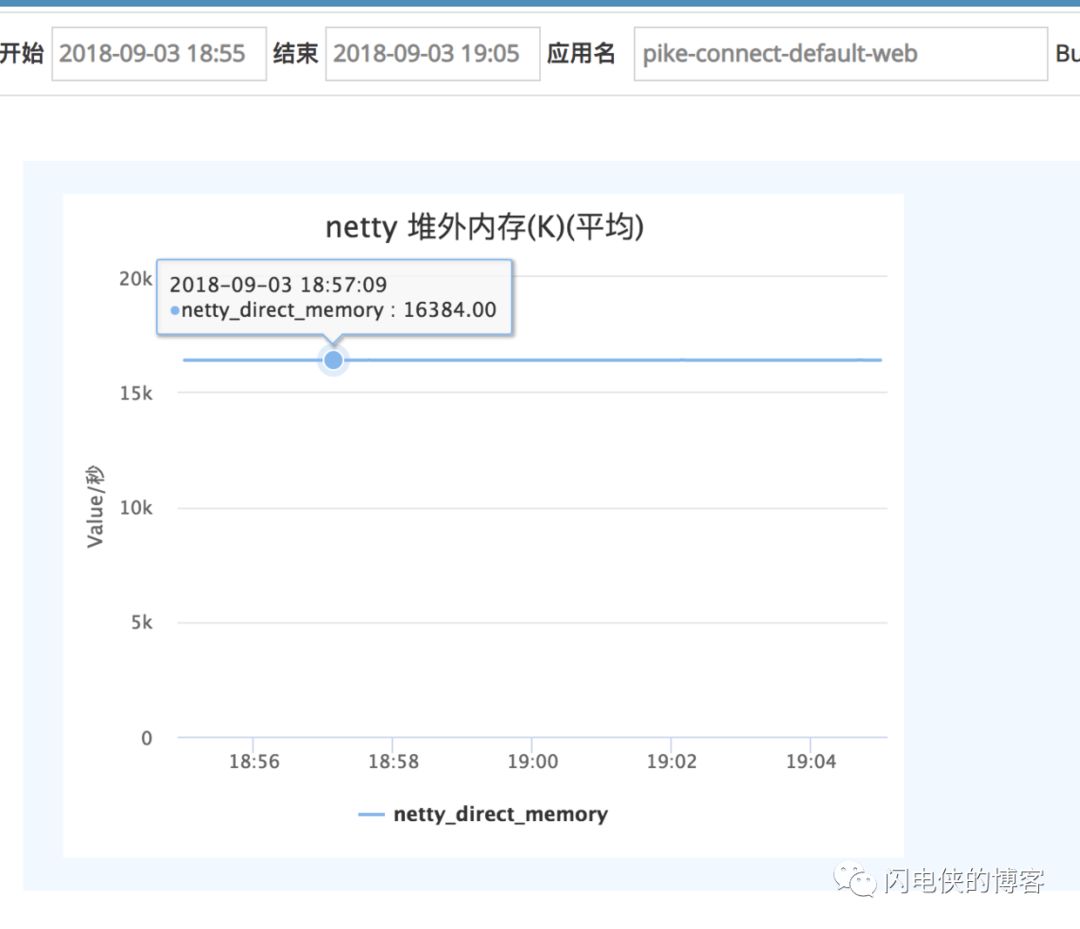
发现过一段时间,堆外内存已经稳定不涨了,我们的捉虫之旅到此结束!最后,我来给本次捉虫之旅做一次总结
总结
1.遇到堆外内存泄露不要怕,仔细耐心分析,总能找到思路,要多看日志,多分析。
2.如果使用了netty 堆外内存,那么你可以自行监控堆外内存的使用情况,不需要借助第三方工具,我这里是使用的反射拿到的堆外内存的情况。
3.逐渐缩小范围,直到bug被你找到。当你确认某个线程的执行带来 bug 的时候,可单步执行,可二分执行,定位到某行代码之后,跟到这段代码,然后继续单步执行或者二分的方式来定位最终出 bug 的代码,这个方法屡试不爽,最后总能找到bug。
4.熟练掌握 idea 的调试,让你的捉虫速度快如闪电,这里,最常见的调试方式是预执行表达式,以及通过线程调用栈,死盯某个对象,就能够掌握这个对象的定义,赋值之类。
最后,祝愿大家都能找到自己的 bug!
- END -