
一次 Java 内存泄漏排查过程,涨姿势
http://www.importnew.com/29591.html
在一个凄凉的午夜
午夜刚过,我就被一条来自监控系统的警报吵醒了。Adventory,我们的 PPC (以点击次数收费)广告系统中一个负责索引广告的应用,很明显连续重启了好几次。在云端的环境里,实例的重启是很正常的,也不会触发报警,但这次实例重启的次数在短时间内超过了阈值。我打开了笔记本电脑,一头扎进项目的日志里。
一定是网络的问题
我看到服务在连接 ZooKeeper 时发生了数次超时。我们使用 ZooKeeper(ZK)协调多个实例间的索引操作,并依赖它实现鲁棒性。很显然,一次 Zookeeper 失败会阻止索引操作的继续运行,不过它应该不会导致整个系统挂掉。而且,这种情况非常罕见(这是我第一次遇到 ZK 在生产环境挂掉),我觉得这个问题可能不太容易搞定。于是我把 ZooKeeper 的值班人员喊醒了,让他们看看发生了什么。
同时,我检查了我们的配置,发现 ZooKeeper 连接的超时时间是秒级的。很明显,ZooKeeper 全挂了,由于其他服务也在使用它,这意味着问题非常严重。我给其他几个团队发了消息,他们显然还不知道这事儿。
ZooKeeper 团队的同事回复我了,在他看来,系统运行一切正常。由于其他用户看起来没有受到影响,我慢慢意识到不是 ZooKeeper 的问题。日志里明显是网络超时,于是我把负责网络的同事叫醒了。
负责网络的团队检查了他们的监控,没有发现任何异常。由于单个网段,甚至单个节点,都有可能和剩余的其他节点断开连接,他们检查了我们系统实例所在的几台机器,没有发现异常。其间,我尝试了其他几种思路,不过都行不通,我也到了自己智力的极限。时间已经很晚了(或者说很早了),同时,跟我的尝试没有任何关系,重启变得不那么频繁了。由于这个服务仅仅负责数据的刷新,并不会影响到数据的可用性,我们决定把问题放到上午再说。
一定是 GC 的问题
有时候把难题放一放,睡一觉,等脑子清醒了再去解决是一个好主意。没人知道当时发生了什么,服务表现的非常怪异。突然间,我想到了什么。Java 服务表现怪异的主要根源是什么?当然是垃圾回收。
为了应对目前这种情况的发生,我们一直打印着 GC 的日志。我马上把 GC 日志下载了下来,然后打开 Censum开始分析日志。我还没仔细看,就发现了一个恐怖的情况:每15分钟发生一次 full GC,每次 GC 引发长达 20 秒的服务停顿。怪不得连接 ZooKeeper 超时了,即使 ZooKeeper 和网络都没有问题。
这些停顿也解释了为什么整个服务一直是死掉的,而不是超时之后只打一条错误日志。我们的服务运行在 Marathon 上,它定时检查每个实例的健康状态,如果某个端点在一段时间内没有响应,Marathon 就重启那个服务。
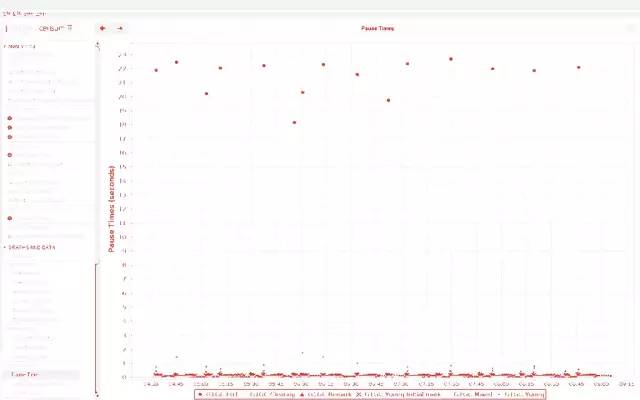
知道原因之后,问题就解决一半了,因此我相信这个问题很快就能解决。为了解释后面的推理,我需要说明一下 Adventory 是如何工作的,它不像你们那种标准的微服务。
Adventory 是用来把我们的广告索引到 ElasticSearch (ES) 的。这需要两个步骤。第一步是获取所需的数据。到目前为止,这个服务从其他几个系统中接收通过 Hermes 发来的事件。数据保存到 MongoDB 集群中。数据量最多每秒几百个请求,每个操作都特别轻量,因此即便触发一些内存的回收,也耗费不了多少资源。第二步就是数据的索引。这个操作定时执行(大概两分钟执行一次),把所有 MongoDB 集群存储的数据通过 RxJava 收集到一个流中,组合为非范式的记录,发送给 ElasticSearch。这部分操作类似离线的批处理任务,而不是一个服务。
由于经常需要对数据做大量的更新,维护索引就不太值得,所以每执行一次定时任务,整个索引都会重建一次。这意味着一整块数据都要经过这个系统,从而引发大量的内存回收。尽管使用了流的方式,我们也被迫把堆加到了 12 GB 这么大。由于堆是如此巨大(而且目前被全力支持),我们的 GC 选择了 G1。
我以前处理过的服务中,也会回收大量生命周期很短的对象。有了那些经验,我同时增加了 -XX:G1NewSizePercent 和 -XX:G1MaxNewSizePercent 的默认值,这样新生代会变得更大,young GC 就可以处理更多的数据,而不用把它们送到老年代。Censum 也显示有很多过早提升。这和一段时间之后发生的 full GC 也是一致的。不幸的是,这些设置没有起到任何作用。
接下来我想,或许生产者制造数据太快了,消费者来不及消费,导致这些记录在它们被处理前就被回收了。我尝试减小生产数据的线程数量,降低数据产生的速度,同时保持消费者发送给 ES 的数据池大小不变。这主要是使用背压(backpressure)机制,不过它也没有起到作用。
一定是内存泄漏
这时,一个当时头脑还保持冷静的同事,建议我们应该做一开始就做的事情:检查堆中的数据。我们准备了一个开发环境的实例,拥有和线上实例相同的数据量,堆的大小也大致相同。把它连接到 jnisualvm ,分析内存的样本,我们可以看到堆中对象的大致数量和大小。大眼一看,可以发现我们域中Ad对象的数量高的不正常,并且在索引的过程中一直在增长,一直增长到我们处理的广告的数量级别。但是……这不应该啊。毕竟,我们通过 RX 把这些数据整理成流,就是为了防止把所有的数据都加载到内存里。
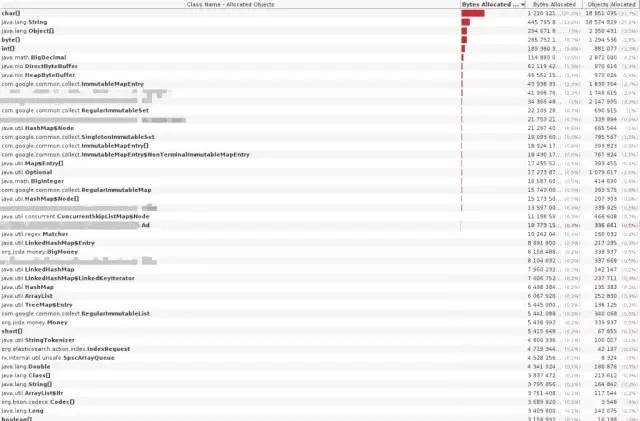
随着怀疑越来越强,我检查了这部分代码。它们是两年前写的,之后就没有再被仔细的检查过。果不其然,我们实际上把所有的数据都加载到了内存里。这当然不是故意的。由于当时对 RxJava 的理解不够全面,我们想让代码以一种特殊的方式并行运行。为了从 RX 的主工作流中剥离出来一些工作,我们决定用一个单独的 executor 跑 CompetableFuture。但是,我们因此就需要等待所有的 CompetableFuture 都工作完……通过存储他们的引用,然后调用 join()。这导致一直到索引完成,所有的 future 的引用,以及它们引用到的数据,都保持着生存的状态。这阻止了垃圾收集器及时的把它们清理掉。
真有这么糟糕吗?
当然这是一个很愚蠢的错误,对于发现得这么晚,我们也很恶心。我甚至想起很久之前,关于这个应用需要 12 GB 的堆的问题,曾有个简短的讨论。12 GB 的堆,确实有点大了。但是另一方面,这些代码已经运行了将近两年了,没有发生过任何问题。我们可以在当时相对容易的修复它,然而如果是两年前,这可能需要我们花费更多的时间,而且相对于节省几个 G 的内存,当时我们有很多更重要的工作。
因此,虽然从纯技术的角度来说,这个问题如此长时间没解决确实很丢人,然而从战略性的角度来看,或许留着这个浪费内存的问题不管,是更务实的选择。当然,另一个考虑就是这个问题一旦发生,会造成什么影响。我们几乎没有对用户造成任何影响,不过结果有可能更糟糕。软件工程就是权衡利弊,决定不同任务的优先级也不例外。
还是不行
有了更多使用 RX 的经验之后,我们可以很简单的解决 ComplerableFurue 的问题。重写代码,只使用 RX;在重写的过程中,升级到 RX2;真正的流式处理数据,而不是在内存里收集它们。这些改动通过 code review 之后,部署到开发环境进行测试。让我们吃惊的是,应用所需的内存丝毫没有减少。内存抽样显示,相较之前,内存中广告对象的数量有所减少。而且对象的数量现在不会一直增长,有时也会下降,因此他们不是全部在内存里收集的。还是老问题,看起来这些数据仍然没有真正的被归集成流。
那现在是怎么回事?
相关的关键词刚才已经提到了:背压。当数据被流式处理,生产者和消费者的速度不同是很正常的。如果生产者比消费者快,并且不能把速度降下来,它就会一直生产越来越多的数据,消费者无法以同样的速度处理掉他们。现象就是未处理数据的缓存不断增长,而这就是我们应用中真正发生的。背压就是一套机制,它允许一个较慢的消费者告诉较快的生产者去降速。
我们的索引系统没有背压的概念,这在之前没什么问题,反正我们把整个索引都保存到内存里了。一旦我们解决了之前的问题,开始真正的流式处理数据,缺少背压的问题就变得很明显了。
这个模式我在解决性能问题时见过很多次了:解决一个问题时会浮现另一个你甚至没有听说过的问题,因为其他问题把它隐藏起来了。如果你的房子经常被淹,你不会注意到它有火灾隐患。
修复由修复引起的问题
在 RxJava 2 里,原来的 Observable 类被拆成了不支持背压的 Observable 和支持背压的 Flowable。幸运的是,有一些简单的办法,可以开箱即用的把不支持背压的 Observable 改造成支持背压的 Flowable。其中包含从非响应式的资源比如 Iterable 创建 Flowable。把这些 Flowable 融合起来可以生成同样支持背压的 Flowable,因此只要快速解决一个点,整个系统就有了背压的支持。
有了这个改动之后,我们把堆从 12 GB 减少到了 3 GB ,同时让系统保持和之前同样的速度。我们仍然每隔数小时就会有一次暂停长达 2 秒的 full GC,不过这比我们之前见到的 20 秒的暂停(还有系统崩溃)要好多了。
再次优化 GC
但是,故事到此还没有结束。检查 GC 的日志,我们注意到大量的过早提升,占到 70%。尽管性能已经可以接受了,我们也尝试去解决这个问题,希望也许可以同时解决 full GC 的问题。
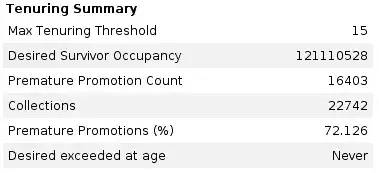
如果一个对象的生命周期很短,但是它仍然晋升到了老年代,我们就把这种现象叫做过早提升(premature tenuring)(或者叫过早升级)。老年代里的对象通常都比较大,使用与新生代不同的 GC 算法,而这些过早提升的对象占据了老年代的空间,所以它们会影响 GC 的性能。因此,我们想竭力避免过早提升。
我们的应用在索引的过程中会产生大量短生命周期的对象,因此一些过早提升是正常的,但是不应该如此严重。当应用产生大量短生命周期的对象时,能想到的第一件事就是简单的增加新生代的空间。默认情况下,G1 的 GC 可以自动的调整新生代的空间,允许新生代使用堆内存的 5% 至 60%。我注意到运行的应用里,新生代和老年代的比例一直在一个很宽的幅度里变化,不过我依然动手修改了两个参数:-XX:G1NewSizePercent=40 和 -XX:G1MaxNewSizePercent=90看看会发生什么。这没起作用,甚至让事情变得更糟糕了,应用一启动就触发了 full GC。我也尝试了其他的比例,不过最好的情况就是只增加 G1MaxNewSizePercent而不修改最小值。这起了作用,大概和默认值的表现差不多,也没有变好。
尝试了很多办法后,也没有取得什么成就,我就放弃了,然后给 Kirk Pepperdine 发了封邮件。他是位很知名的 Java 性能专家,我碰巧在 Allegro 举办的 Devoxx 会议的训练课程里认识了他。通过查看 GC 的日志以及几封邮件的交流,Kirk 建议试试设置 -XX:G1MixedGCLiveThresholdPercent=100。这个设置应该会强制 G1 GC 在 mixed GC 时不去考虑它们被填充了多少,而是强制清理所有的老年代,因此也同时清理了从新生代过早提升的对象。这应该会阻止老年代被填满从而产生一次 full GC。然而,在运行一段时间以后,我们再次惊讶的发现了一次 full GC。Kirk 推断说他在其他应用里也见到过这种情况,它是 G1 GC 的一个 bug:mixed GC 显然没有清理所有的垃圾,让它们一直堆积直到产生 full GC。他说他已经把这个问题通知了 Oracle,不过他们坚称我们观察到的这个现象不是一个 bug,而是正常的。
结论
我们最后做的就是把应用的内存调大了一点点(从 3 GB 到 4 GB),然后 full GC 就消失了。我们仍然观察到大量的过早提升,不过既然性能是没问题的,我们就不在乎这些了。一个我们可以尝试的选项是转换到 GMS(Concurrent Mark Sweep)GC,不过由于它已经被废弃了,我们还是尽量不去使用它。

那么这个故事的寓意是什么呢?首先,性能问题很容易让你误入歧途。一开始看起来是 ZooKeeper 或者 网络的问题,最后发现是我们代码的问题。即使意识到了这一点,我首先采取的措施也没有考虑周全。为了防止 full GC,我在检查到底发生了什么之前就开始调优 GC。这是一个常见的陷阱,因此记住:即使你有一个直觉去做什么,先检查一下到底发生了什么,再检查一遍,防止浪费时间去错误的问题。
第二条,性能问题太难解决了。我们的代码有良好的测试覆盖率,而且运行的特别好,但是它也没有满足性能的要求,它在开始的时候就没有清晰的定义好。性能问题直到部署之后很久才浮现出来。由于通常很难真实的再现你的生产环境,你经常被迫在生产环境测试性能,即使那听起来非常糟糕。
第三条,解决一个问题有可能引发另一个潜在问题的浮现,强迫你不断挖的比你预想的更深。我们没有背压的事实足以中断这个系统,但是直到我们解决了内存泄漏的问题后,它才浮现。