
java内存泄露排查总结
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
作者 | 那个少年~
来源 | urlify.cn/FvQVzi
1.内存溢出和内存泄露
内存溢出:你申请了10个字节的空间,但是你在这个空间写入了11个或者以上字节的数据,则出现溢出
内存泄露:你用new申请了一块内存,后来很长时间都不使用了,但是因为一直被某个或者某些实例所持有导致GC不能回收掉,也就是该释放的对象没有释放,则出现泄露。
1.1 内存溢出
JVM内存过小
程序不严密,产生了过多的垃圾
内存中加载的数据量过大,如一次性从数据库取出过多数据
集合类中有对对象的引用,使用完后没有清空,是jvm不能回收
代码中存在死循环或循环中产生过多重复的对象实体
使用第三方软件中的bug
启动参数内存值设定过小
tomcat:java.lang.OutOfMemoryError: PermGen space
tomcat:java.lang.OutOfMemoryError: Java heap space
weblogic:Root cause of ServletException java.lang.OutOfMemoryError
resin:java.lang.OutOfMemoryError
java:java.lang.OutOfMemoryError
增加JVM的内存大小:对于tomcat容器,找到tomcat在电脑中的安装目录,进入这个目录,然后进入bin目录中,在window环境下找到bin目录中的catalina.bat,在linux环境下找到catalina.sh。编辑catalina.bat文件,找到JAVA_OPTS(具体来说是
set "JAVA_OPTS=%JAVA_OPTS% %LOGGING_MANAGER%")这个选项的位置,这个参数是Java启动的时候,需要的启动参数。也可以在操作系统的环境变量中对JAVA_OPTS进行设置,因为tomcat在启动的时候,也会读取操作系统中的环境变量的值,进行加载。如果是修改了操作系统的环境变量,需要重启机器,再重启tomcat,如果修改的是tomcat配置文件,需要将配置文件保存,然后重启tomcat,设置就能生效了。优化程序,释放垃圾:主要思路就是避免程序体现上出现的情况。避免死循环,防止一次载入太多的数据,提高程序健壮型及时释放。因此,从根本上解决Java内存溢出的唯一方法就是修改程序,及时地释放没用的对象,释放内存空间。
1.2 内存泄露
首先,这些对象是可达的,即在有向图中,存在通路可以与其相连;
其次,这些对象是无用的,即程序以后不会再使用这些对象。
1.3 内存溢出和内存泄露的联系
2、一个Java内存泄漏的排查案例
2.1 确定频繁的Full GC现象
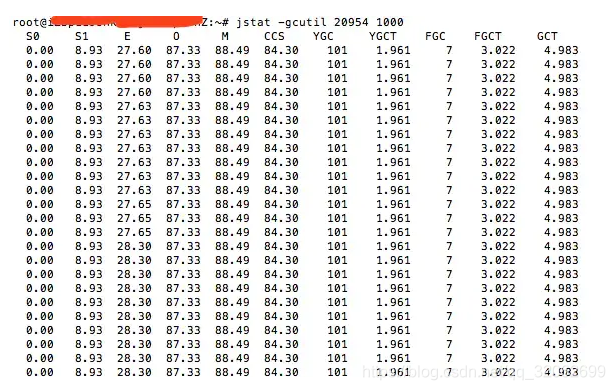
2.2 找出频繁Full GC的原因
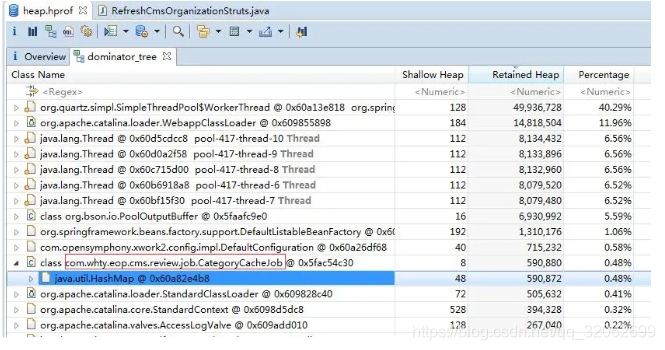
把堆dump下来在用MAT等工具进行分析,但是dump堆要花较长时间,并且文件巨大,再从服务器上拖回本地导入工具,这个过程有些折腾,不到万不得已最好别这么干。
更轻量级的在线分析,使用jmap(java内存影响工具)生成堆转存快照(一般称为headdump或者dump文件)
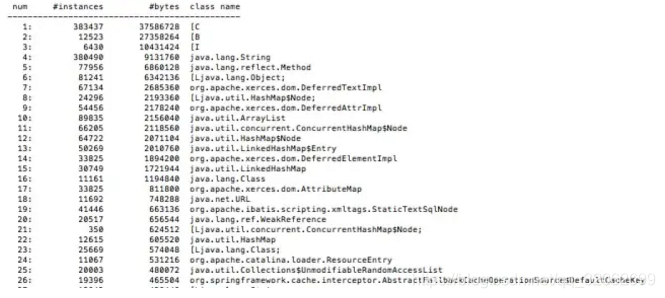

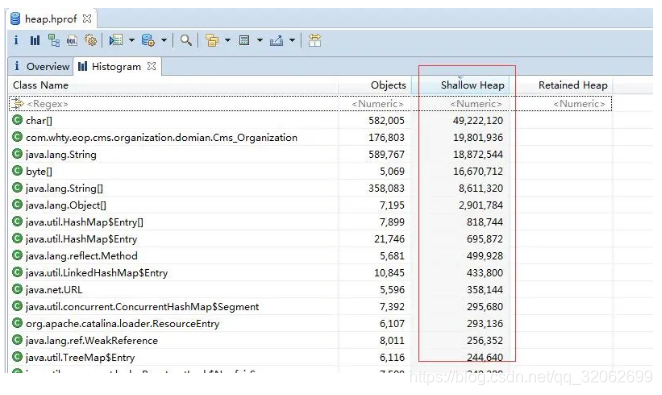
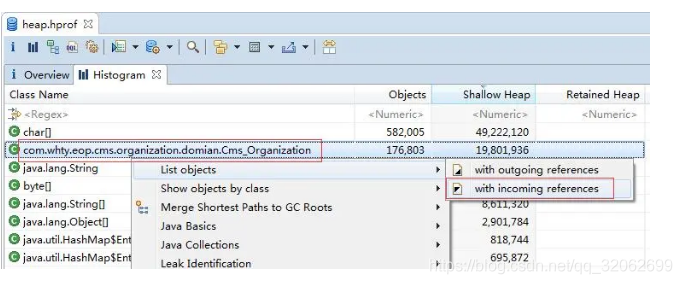
2.3 定位到代码
用工具生成java应用程序的heap dump(如jmap)
使用Java heap分析工具(如MAT),找出内存占用超出预期的嫌疑对象
根据情况,分析嫌疑对象和其他对象的引用关系。
分析程序的源代码,找出嫌疑对象数量过多的原因。
ps -ef|grep java
jmap -histo:live 进程号 | head -7

jmap -dump:live,format=b,file=heap.hprof 3514
安装MAT插件
在eclipse里切换到Memory Analysis视图
用MAT打开heap profile文件。


public class RefreshCmsOrganizationStruts implements Runnable{
private final static Logger logger = Logger.getLogger(RefreshCmsOrganizationStruts.class);
private List<Cms_Organization> organizations;
private OrganizationDao organizationDao = (OrganizationDao) WebContentBean
.getInstance().getBean("organizationDao");
public RefreshCmsOrganizationStruts(List<Cms_Organization> organizations) {
this.organizations = organizations;
}
public void run() {
Iterator<Cms_Organization> iter = organizations.iterator();
Cms_Organization organization = null;
while (iter.hasNext()) {
organization = iter.next();
synchronized (organization) {
try {
organizationDao.refreshCmsOrganizationStrutsInfo(organization.getOrgaId());
organizationDao.refreshCmsOrganizationResourceInfo(organization.getOrgaId());
organizationDao.sleep();
} catch (Exception e) {
logger.debug("RefreshCmsOrganizationStruts organization = " + organization.getOrgaId(), e);
}
}
}
}
}
public class CategoryCacheJob extends QuartzJobBean implements StatefulJob {
private static final Logger LOGGER = Logger.getLogger(CategoryCacheJob.class);
public static Map<String,List<Cms_Category>> cacheMap = new java.util.HashMap<String,List<Cms_Category>>();
@Override
protected void executeInternal(JobExecutionContext ctx) throws JobExecutionException {
try {
//LOGGER.info("======= 缓存编目树开始 =======");
MongoBaseDao mongoBaseDao = (MongoBaseDao) BeanLocator.getInstance().getBean("mongoBaseDao");
MongoOperations mongoOperations = mongoBaseDao.getMongoOperations();
/*
LOGGER.info("1.缓存基础教育编目树");
Query query = Query.query(Criteria.where("isDel").is("0").and("categoryType").is("F"));
query.sort().on("orderNo", Order.ASCENDING);
List<Cms_Category> list = mongoOperations.find(query, Cms_Category.class);
String key = query.toString().replaceAll("\\{|\\}|\\p{Cntrl}|\\p{Space}", "");
key += "_CategoryCacheJob";
cacheMap.put(key, list);
*/
//LOGGER.info("2.缓存职业教育编目树");
Query query2 = Query.query(Criteria.where("isDel").is("0").and("categoryType").in("JMP","JHP"));
query2.sort().on("orderNo", Order.ASCENDING);
List<Cms_Category> list2 = mongoOperations.find(query2, Cms_Category.class);
String key2 = query2.toString().replaceAll("\\{|\\}|\\p{Cntrl}|\\p{Space}", "");
key2 += "_CategoryCacheJob";
cacheMap.put(key2, list2);
//LOGGER.info("3.缓存专题教育编目树");
Query query3 = Query.query(Criteria.where("isDel").is("0").and("categoryType").is("JS"));
query3.sort().on("orderNo", Order.ASCENDING);
List<Cms_Category> list3 = mongoOperations.find(query3, Cms_Category.class);
String key3 = query3.toString().replaceAll("\\{|\\}|\\p{Cntrl}|\\p{Space}", "");
key3 += "_CategoryCacheJob";
cacheMap.put(key3, list3);
//LOGGER.info("======= 缓存编目树结束 =======");
} catch(Exception ex) {
LOGGER.error(ex.getMessage(), ex);
LOGGER.info("======= 缓存编目树出错 =======");
}
}
}

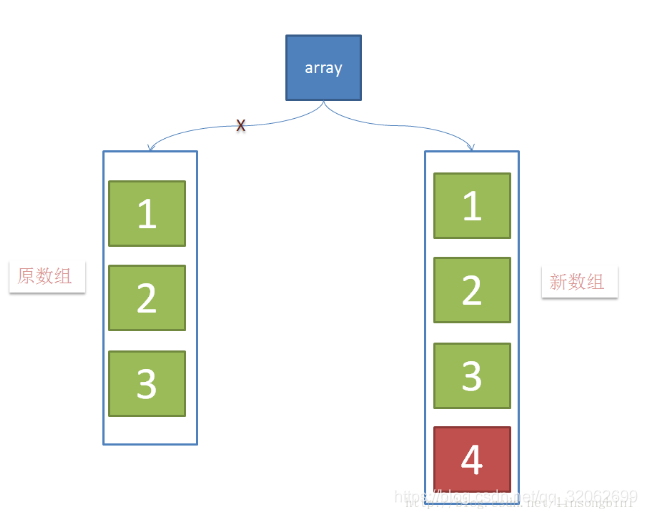
public boolean add(E e) {
//1、先加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
//2、拷贝数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
//3、将元素加入到新数组中
newElements[len] = e;
//4、将array引用指向到新数组
setArray(newElements);
return true;
} finally {
//5、解锁
lock.unlock();
}
}
由于写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致yong gc或者full gc
不能用于实时读的场景,像拷贝数组,新增元素都需要时间,所以调用一个set操作后,读取到的数据可能还是旧的,虽然
CopyOnWriteArrayList能做到最终一致性,但是还无法满足实时性的要求
锋哥最新SpringCloud分布式电商秒杀课程发布
👇👇👇
👆长按上方微信二维码 2 秒
感谢点赞支持下哈 