
埋点自动收集方案-路由依赖分析
1.一个项目总共有多少组件?每个页面又有多少组件构成?
2.有哪些组件是公共组件,它们分别被哪些页面引用?
对于这两个问题,我们先思考一会。sleep……
跟随这篇文章我们一起探讨下,希望能帮你找到答案。
背景
随着组件化思想深入人心,开发中遇到特定的功能模块或UI模块,我们便会想到抽成组件,高级一点的做法就是把多个页面相似的部分抽成公共的组件。
组件化的“诅咒”
但是往往对一件事物依赖越强,越容易陷入它的“诅咒”当中。当项目有越多的组件时,开发者越不容易建立它们之间的关系,特别当改动了某个组件的一行代码,甚至不能准确的判断由于这行代码变动,都影响了哪些页面。我暂且称之为“组件化的诅咒”。如果我们有个完整的组件依赖关系,就可以很好的解决这个问题。
我们以下面的场景为例,看一看依赖分析的重要性和必要性。
通过前一篇文章,想必大家对埋点自动收集方案有了宏观且全面的了解。在这里再简单概述下:
埋点自动收集方案是基于jsdoc对注释信息的搜集能力,通过给路由页面中所有埋点增加注释的方式,在编译时建立起页面和埋点信息的对应关系。
点击查看《埋点自动收集方案-概述》
在整个方案中,埋点的数据源很重要,而数据源与页面的对应关系又是保证数据源完整性的关键。比如:首页和个人主页的商品流都采用相同的商品卡片,开发者自然会将商品卡片抽离为一个公共组件。如下:
//Index.vue 首页
import Card from './common/Card.vue' //依赖商品卡片组件
//Home.vue 个人主页
import Card from './common/Card.vue' //依赖商品卡片组件
//Card.vue 商品卡片组件
goDetail(item) {
/**
* @mylog 商品卡片点击
*/
this.$log('card-click') // 埋点发送
}
这就带来一个问题:商品卡片的点击信息(埋点的数据源),既可能是首页的,也可能是个人主页的,而jsdoc搜集埋点注释时,对这种归属情况的判断无能为力。所以必须找到一种方法可以拿到组件和页面的映射关系。
期望效果
项目中的实际依赖关系:
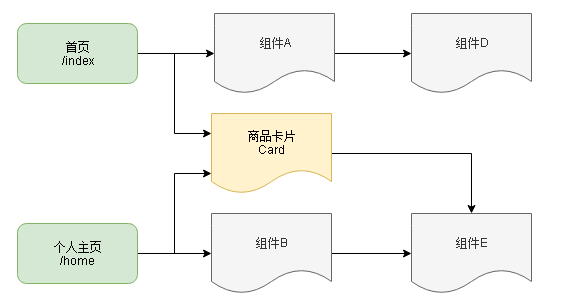
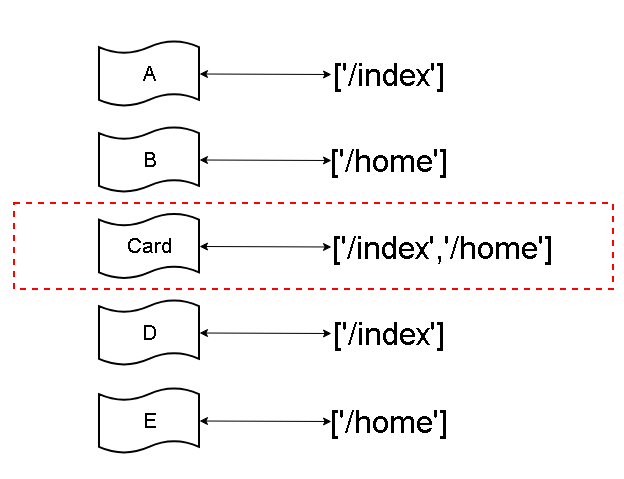
对应的依赖分析关系:(每个组件,与引用它的页面路由的映射)
方案思考
那么,怎么做依赖分析?在思考这个问题之前,我们先看一看有哪些常见的建立依赖的语法。
//a.ts
import B from './b.ts'
import getCookie from '@/libs/cookie.ts'
//c.ts
const C = require('./b.ts')
//b.ts
div {
background: url('./assets/icon.png') no-repeat;
}
import './style.css'
// c.vue
import Vue from Vue
import Card from '@/component/Card.vue'
这里给出三种依赖分析的思路:
1 递归解析
从项目的路由配置文件开始,分别对每个路由页面,进行依赖的递归解析。这种思路想法简单直接,但实现起来可能较为繁琐,需要解析页面中所有形式的依赖关系。
2 借助webpack工具的统计分析数据,进行二次加工
实际项目中我们都是采用webpack打包工具,而它的一大特点就是会自动帮开发者做依赖分析(独立的enhanced-resolve库)。相较于第一种重写解析的方法,为何不站在webpack的肩膀上解决问题呢。
先来看下webpack的整体编译流程:
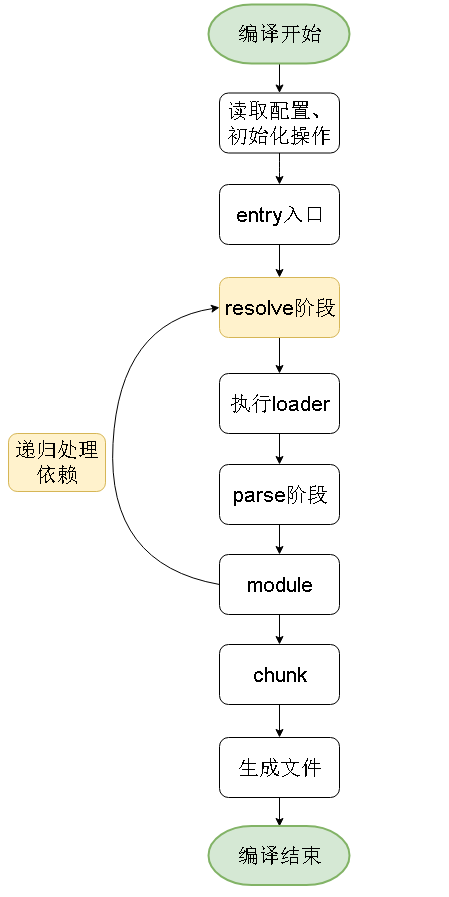
可以看到,每一个文件都会经过resolve阶段,最终在编译结束后,得到本次编译的统计分析信息。
//done是compiler的钩子,在完成一次编译结束后的会执行
compiler.hooks.done.tapAsync("demoPlugin",(stats,cb)=>{
fs.writeFile(appRoot+'/stats.json', JSON.stringify(stats.toJson(),'','\t'), (err) => {
if (err) {
throw err;
}
})
cb()
})
详细的编译数据,就是done事件中的回调参数stats,经过处理后,大致如下:
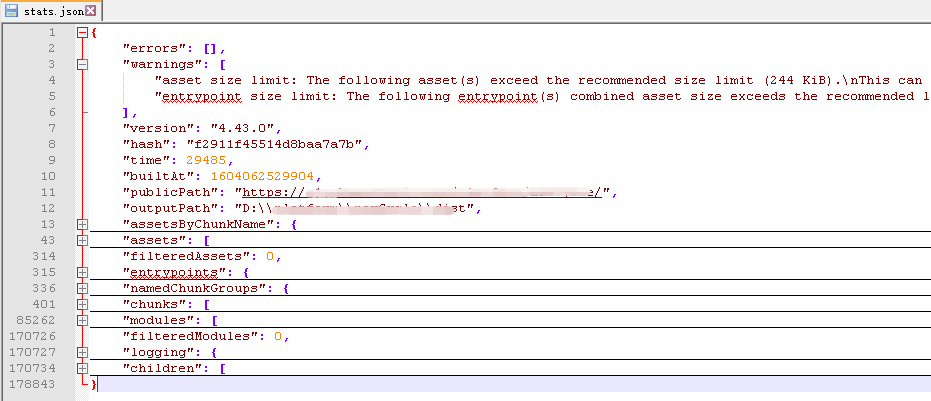
通过对这份统计分析信息的二次加工和分析,也可以得到预期的依赖关系(插件webpack-bundle-analyzer也是基于这份数据生成的分析图表)。这份数据看上去更像基本chunk和module的依赖分析,对于组件或公共组件的依赖关系问题,需要对chunks和modules综合分析才能解决。同时我们还发现,这份数据的数据量相当大,且有大量开发者不关心的数据(截图是只有两个路由页面的情况下的数据量)。接下来讨论的方案是作者实际采用的方案,也是基于webpack,不同之处在于分析和收集依赖关系的时机。
3 在webpack的解析阶段,分析并收集依赖
我们看到虽然webpack的分析数据非常臃肿,但是它确实帮助开发者做了这份繁重的工作。只是我们希望能定制数据的范围,主动收集期望数据,所以推想,可否在每个文件解析阶段进行一定的“干预”,即通过条件判断或过滤筛选达成目的。那么问题来了,应该在resolve的哪个阶段进行“干预”,如何“干预”?
好,我们先要总览下webpack事件流过程:
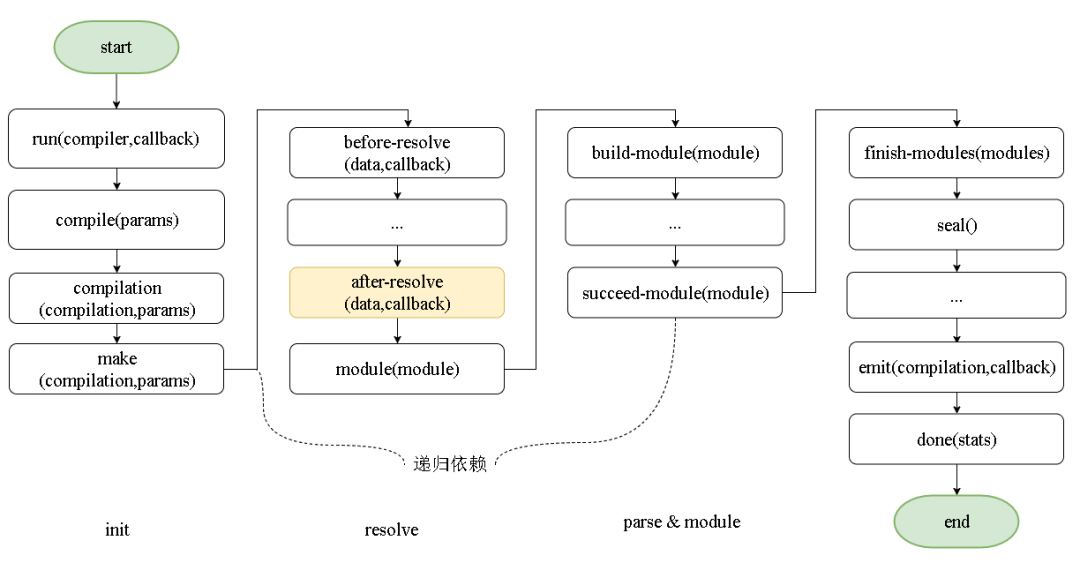
很显然,afterResolve是每个文件解析阶段的最后,应该就从这里下手啦。
具体实现
先奉上流程图
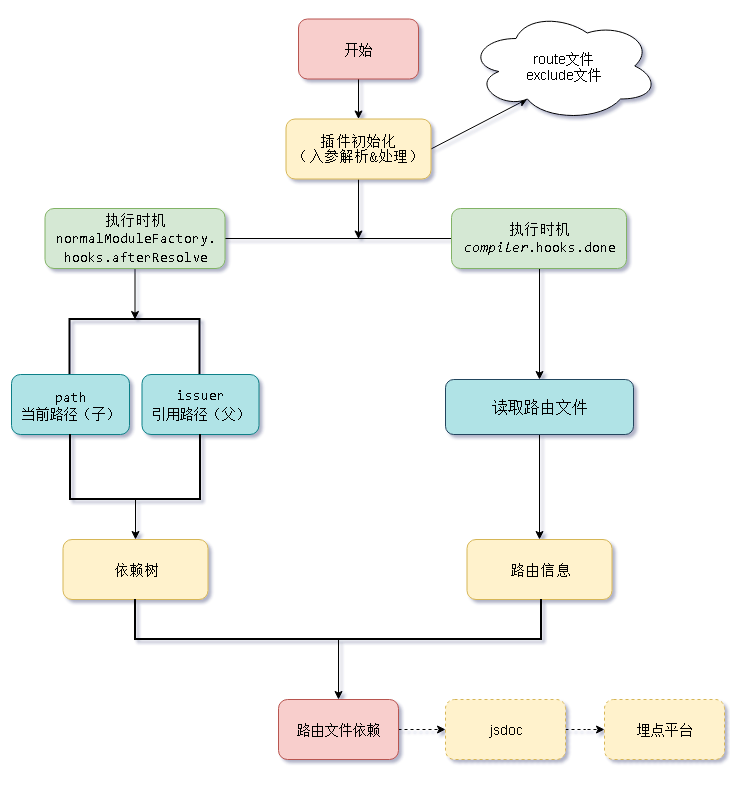
1 初始化
首先这是一个webpack插件,在初始化阶段,指定解析的路由文件地址(比如src/route)以及排除解析的文件地址(比如src/lib、src/util),原因是这些排除的文件不会存在埋点数据。
2 收集依赖关系
在afterResolve钩子函数中,获取当前被解析文件的路径及其父级文件路径。
apply(compiler) {
compiler.hooks.normalModuleFactory.tap(
"demoPlugin",
nmf => {
nmf.hooks.afterResolve.tapAsync(
"demoPlugin",
(result, callback) => {
const { resourceResolveData } = result;
// 当前文件的路径
let path = resourceResolveData.path;
// 父级文件路径
let fatherPath = resourceResolveData.context.issuer;
callback(null,result)
}
);
}
)
}
3 建立依赖树
根据上一步获取的引用关系,生成依赖树。
// 不是nodemodule中的文件,不是exclude中的文件,且为.js/.jsx/.ts/.tsx/.vue
if(!skip(this.ignoreDependenciesArr,this.excludeRegArr,path, fatherPath) && matchFileType(path)){
if(fatherPath && fatherPath != path){ // 父子路径相同的排除
if(!(fatherPath.endsWith('js') || fatherPath.endsWith('ts')) || !(path.endsWith('js') || path.endsWith('ts'))){
// 父子同为js文件,认为是路由文件的父子关系,而非组件,故排除
let sonObj = {};
sonObj.type = 'module';
sonObj.path = path;
sonObj.deps = []
// 如果本次parser中的path,解析过,那么把过去的解析结果copy过来。
sonObj = copyAheadDep(this.dependenciesArray,sonObj);
let obj = checkExist(this.dependenciesArray,fatherPath,sonObj);
this.dependenciesArray = obj.arr;
if(!obj.fileExist){
let entryObj = {type:'module',path:fatherPath,deps:[sonObj]};
this.dependenciesArray.push(entryObj);
}
}
} else if(!this.dependenciesArray.some(it => it.path == path)) {
// 父子路径相同,且在this.dependenciesArray不存在,认为此文件为依赖树的根文件
let entryObj = {type:'entry',path:path,deps:[]};
this.dependenciesArray.push(entryObj);
}
}
那么这时生成的依赖树如下:

4 解析路由信息
通过上一步基本上得到组件的依赖树,但我们发现对于公共组件Card,它只存在首页的依赖中,却不见在个人主页的依赖中,这显然不符合预期(在第6步中专门解释)。那么接下来就要找寻,这个依赖树与路由信息的关系。
compiler.hooks.done.tapAsync("RoutePathWebpackPlugin",(stats,cb)=>{
this.handleCompilerDone()
cb()
})
// ast解析路由文件
handleCompilerDone(){
if(this.dependenciesArray.length){
let tempRouteDeps = {};
// routePaths是项目的路由文件数组
for(let i = 0; i < this.routePaths.length;i ++){
let code = fs.readFileSync(this.routePaths[i],'utf-8');
const tsParsedScript = ts.transpileModule(code, { compilerOptions: {target: 'ES6' }});
code = tsParsedScript.outputText;
let ast = Parser.parse(code,{'sourceType':'module',ecmaVersion:11});
const walk = inject(acornWalk);
let that = this;
walk.ancestor(ast,{
Literal(_, ancestors) {
// 以下操作为获取单独的route配置文件中,name和页面的映射关系
……
}
}
})
}
// 合并多个路由文件的映射关系
let tempDeps = []
for(let arr of Object.values(tempRouteDeps)){
tempDeps = tempDeps.concat(arr)
}
this.routeDeps = tempDeps.filter(it=>it && Object.prototype.toString.call(it) == "[object Object]" && it.components);
// 获取真实插件传入的router配置文件的依赖,除去main.js、filter.js、store.js等文件的依赖
this.dependenciesArray =
getRealRoutePathDependenciesArr(this.dependenciesArray,this.routePaths);
}
}
通过这一步ast解析,可以得到如下路由信息:
[
{
"name": "index",
"route": "/index",
"title": "首页",
"components": ["../view/newCycle/index.vue"]
},
{
"name": "home",
"route": "/home",
"title": "个人主页",
"components": ["../view/newCycle/home.vue"]
}
]
5 对依赖树和路由信息进行整合分析
// 将路由页面的所有依赖组件deps,都存放在路由信息的components数组中
const getEndPathComponentsArr = function(routeDeps,dependenciesArray) {
for(let i = 0; i < dependenciesArray.length; i ++){//可能存在多个路由配置文件
let pageArr = dependenciesArray[i].deps;
pageArr.forEach(page=>{
routeDeps = routeDeps.map(routeObj=>{
if(routeObj && routeObj.components){
let relativePath =
routeObj.components[0].slice(routeObj.components[0].indexOf('/')+1);
if(page.path.includes(relativePath.split('/').join(path.sep))){
// 铺平依赖树的层级
routeObj = flapAllComponents(routeObj,page);
// 去重操作
routeObj.components = dedupe(routeObj.components);
}
}
return routeObj;
})
})
}
return routeDeps;
}
//建立一个map数据结构,以每个组件为key,以对应的路由信息为value
// {
// 'path1' => Set { '/index' },
// 'path2' => Set { '/index', '/home' },
// 'path3' => Set { '/home' }
// }
const convertDeps = function(deps) {
let map = new Map();
......
return map;
}
整合分析后依赖关系如下:
{
A: ["index&_&首页&_&index"],// A代表组件A的路径
B: ["index&_&首页&_&index"],// B代表组件B的路径
Card: ["index&_&首页&_&index"],
// 映射中只有和首页的映射
D: ["index&_&首页&_&index"],// D代表组件D的路径
E: ["home&_&个人主页&_&home"],// E代表组件E的路径
}
因为上一步依赖收集部分,Card组件并没有成功收集到个人主页的依赖中,所以这步整合分析也无法建立准确的映射关系。且看下面的解决。
6 修改unsafeCache配置
为什么公共组件Card在收集依赖的时候,只收集到一次?这个问题如果不解决,意味着只有首页的商品点击埋点被收集到,其他引用这个组件的页面商品点击就会丢失。有问题,就有机会,机会意味着解决问题的可能性。
webpack4提供了resolve的配置入口,开发者可以通过几项设置决定如何解析文件,比如extensions、alias等,其中有一个属性——unsafeCache成功引起了作者的注意,它正是问题的根结。
6.1 unsafeCache是webpack提高编译性能的优化措施。
unsafeCache默认为true,表示webpack会缓存已经解析过的文件依赖,待再次需要解析此文件时,直接从缓存中返回结果,避免重复解析。
我们看下源码:
//webpack/lib/WebpackOptionsDefaulter.js
this.set("resolveLoader.unsafeCache", true);
//这是webpack初始化配置参数时对unsafeCache的默认设置
//enhanced-resolve/lib/Resolverfatory.js
if (unsafeCache) {
plugins.push(
new UnsafeCachePlugin(
"resolve",
cachePredicate,
unsafeCache,
cacheWithContext,
"new-resolve"
)
);
plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));
} else {
plugins.push(new ParsePlugin("resolve", "parsed-resolve"));
}
//前面已经提到,webpack将文件的解析独立为一个单独的库去做,那就是enhanced-resolve。
//缓存的工作是由UnsafeCachePlugin完成,代码如下:
//enhanced-resolve/lib/UnsafeCachePlugin.js
apply(resolver) {
const target = resolver.ensureHook(this.target);
resolver
.getHook(this.source)
.tapAsync("UnsafeCachePlugin", (request, resolveContext, callback) => {
if (!this.filterPredicate(request)) return callback();
const cacheId = getCacheId(request, this.withContext);
// !!划重点,当缓存中存在解析过的文件结果,直接callback
const cacheEntry = this.cache[cacheId];
if (cacheEntry) {
return callback(null, cacheEntry);
}
resolver.doResolve(
target,
request,
null,
resolveContext,
(err, result) => {
if (err) return callback(err);
if (result) return callback(null, (this.cache[cacheId] = result));
callback();
}
);
});
}
在UnsafeCachePlugin的apply方法中,当判断有缓存过的文件结果,直接callback,没有继续后面的解析动作。
6.2 这对我们收集依赖有什么影响?
缓存了解析过的文件,意味着与这个文件再次相遇时,事件流将被提前终止,afterResolve的钩子自然也就不会执行到,那么我们的依赖关系就无从谈起。
其实webpack的resolve 过程可以看成事件的串联,当所有串联在一起的事件执行完之后,resolve 就结束了。我们看下原理:
用来解析文件的库是enhanced-resolve,在Resolverfatory生成resolver解析对象时,进行了大量plugins的注册,正是这些plugins形成一系列的解析事件。
//enhanced-resolve/lib/Resolverfatory.js
exports.createResolver = function(options) {
......
let unsafeCache = options.unsafeCache || false;
if (unsafeCache) {
plugins.push(
new UnsafeCachePlugin(
"resolve",
cachePredicate,
unsafeCache,
cacheWithContext,
"new-resolve"
)
);
plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));
// 这里的事件流大致是:UnsafeCachePlugin的事件源(source)是resolve,
//执行结束后的目标事件(target)是new-resolve。
//而ParsePlugin的事件源为new-resolve,所以事件流机制刚好把这两个插件串联起来。
} else {
plugins.push(new ParsePlugin("resolve", "parsed-resolve"));
}
...... // 各种plugin
plugins.push(new ResultPlugin(resolver.hooks.resolved));
plugins.forEach(plugin => {
plugin.apply(resolver);
});
return resolver;
}
每个插件在执行自己的逻辑后,都会调用resolver.doResolve(target, ...),其中的target是触发下一个插件的事件名称,如此往复,直到遇到事件源为result,递归终止,解析结束。
resolve的事件串联流程图大致如下:

UnsafeCachePlugin插件在第一次解析文件时,因为没有缓存,就会触发target为new-resolve的事件,也就是ParsePlugin,同时将解析结果记入缓存。当判断该文件有缓存结果,UnsafeCachePlugin的apply方法会直接callback,而没有继续执行resolver.doResolve(),意味着整个resolve事件流在UnsafeCachePlugin就终止了。这就解释了,为什么只建立了首页与Card组件的映射,而无法拿到个人主页与Card组件的映射。
6.3 解决办法
分析了原因后,就好办了,将unsafeCache设置为false(嗯,就这么简单)。这时你可能担心会降低工程编译速度,但深入一步想想,依赖分析这件事完全可以独立于开发阶段,只要在我们需要它的时候执行这个能力,比如由开发者通过命令行参数来控制。
//package.json
"analyse": "cross-env LEGO_ENV=analyse vue-cli-service build"
//vue.config.js
chainWebpack(config) {
// 这一步解决webpack对组件缓存,影响最终映射关系的处理
config.resolve.unsafeCache = process.env.LEGO_ENV != 'analyse'
}
7 最终依赖关系
{
A: ["index&_&首页&_&index"],// A代表组件A的路径
B: ["index&_&首页&_&index"],// B代表组件B的路径
Card: ["index&_&首页&_&index",
"home&_&个人主页&_&home"],
// Card组件与多个页面有映射关系
D: ["index&_&首页&_&index"],// D代表组件D的路径
E: ["home&_&个人主页&_&home"],// E代表组件E的路径
}
可以看到,与公共组件Card关联的映射页面中,多了个人主页的路由信息,这才是准确的依赖数据。在埋点自动收集项目中,这份依赖关系数据交由jsdoc处理,就可以完成所有埋点信息与页面的映射关系。
one more thing
webpack5,它来了,它带着持久化缓存策略来了。前面提到的unsafeCache虽然可以提升应用构建性能,但是它牺牲了一定的 resolving 准确度,同时它意味着持续性构建过程需要反复重新启动决断策略,这就要收集文件的寻找策略(resolutions)的变化,要识别判断文件 resolutions 是否变化,这一系列过程也是有成本的,这就是为什么叫unsafeCache,而不是safeCache(安全的)。
webpack5规定在配置信息的cache对象的type,可以设置为memory和fileSystem两种方式。memory是指之前的unsafeCache缓存,fileSystem是指相对安全的磁盘持久化缓存。
module.exports = {
cache: {
// 1. Set cache type to filesystem
type: 'filesystem',
buildDependencies: {
// 2. Add your config as buildDependency to get cache invalidation on config change
config: [__filename]
// 3. If you have other things the build depends on you can add them here
// Note that webpack, loaders and all modules referenced from your config are automatically added
}
}
};
所以针对webpack5,如果需要做完整的依赖分析,只需将cache.type动态设置为memory,resolve.unsafeCache设置为false即可。(感兴趣的童鞋可以试一试)
总结
以上,我们解释了组件化可能带来的隐患,提到了路由依赖分析的重要性,给出三种依赖分析的思路,并基于埋点自动收集项目重点阐述了其中一种方案的具体实现。在此与你分享,期待共同成长~
❤️爱心三连击 1.看到这里了就点个在看支持下吧,你的「点赞,在看」是我创作的动力。
2.关注公众号
程序员成长指北,回复「1」加入高级前端交流群!「在这里有好多 前端 开发者,会讨论 前端 Node 知识,互相学习」!3.也可添加微信【ikoala520】,一起成长。
“在看转发”是最大的支持