
即插即用、无需训练:剑桥大学、腾讯AI Lab等提出免训练跨模态文本生成框架

1. 导读
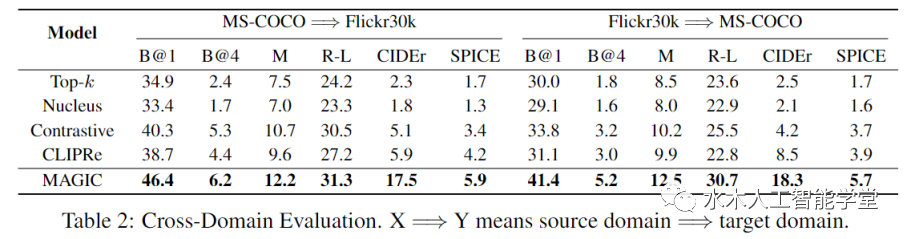
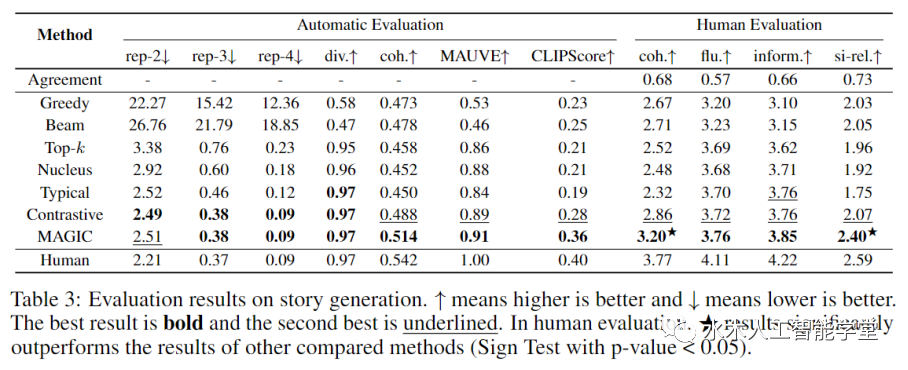
本文提出了一个全新的 MAGIC (iMAge-guided text GeneratIon with CLIP)框架。该框架可以使用图片模态的信息指导预训练语言模型完成一系列跨模态生成任务,例如 image captioning 和 visually grounded story generation。与其他方法不同的是,MAGIC 框架无需多模态训练数据,只需利用现成的语言模型(例如 GPT-2)和图文匹配模型(例如 CLIP)就能够以 zero-shot 的方式高质量地完成多模态生成任务。此外,不同于使用梯度更新生成模型 cache 的传统方法,MAGIC 框架无需梯度更新,因而具备更高效的推理效率。

论文:https://arxiv.org/abs/2205.02655 代码:https://github.com/yxuansu/MAGIC
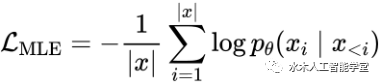
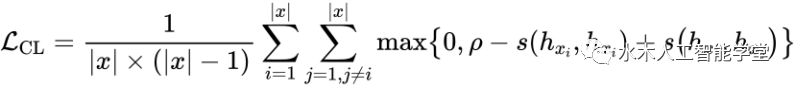
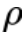 是用来校准生成模型表示空间的 margin 参数,
是用来校准生成模型表示空间的 margin 参数,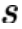 用来计算 token 表示之间的余弦相似度。最终,本文将两个损失函数合并,以此来优化文本模态的 GPT-2 语言模型:
用来计算 token 表示之间的余弦相似度。最终,本文将两个损失函数合并,以此来优化文本模态的 GPT-2 语言模型: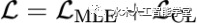
 和图片
和图片 ,第 t 步的 token 选择公式如下:
,第 t 步的 token 选择公式如下: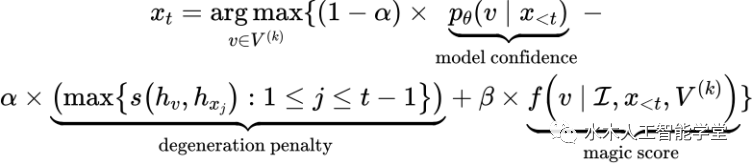
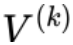 表示按照语言模型概率分布选择的 top-k 个候选 token。同时,该研究借鉴了 SimCTG 中 contrastive search 的思路,在 token 选择指标中引入了 model confidence 和 degeneration penalty 项来使得模型选择更合适的 token。上述公式中最重要的一项是将视觉控制信息引入到模型解码过程中的 magic score:
表示按照语言模型概率分布选择的 top-k 个候选 token。同时,该研究借鉴了 SimCTG 中 contrastive search 的思路,在 token 选择指标中引入了 model confidence 和 degeneration penalty 项来使得模型选择更合适的 token。上述公式中最重要的一项是将视觉控制信息引入到模型解码过程中的 magic score: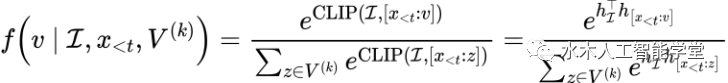
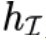 是 CLIP 的 image encoder 产生的图片表示,
是 CLIP 的 image encoder 产生的图片表示,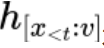 是 CLIP 的 text encoder 产生的文本表示。
是 CLIP 的 text encoder 产生的文本表示。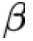 参数用来调节视觉信息的控制力度。当其值为 0 时,语言模型的生成过程不再被视觉信息所影响,从而 magic search 退化为传统的 contrastive search。
参数用来调节视觉信息的控制力度。当其值为 0 时,语言模型的生成过程不再被视觉信息所影响,从而 magic search 退化为传统的 contrastive search。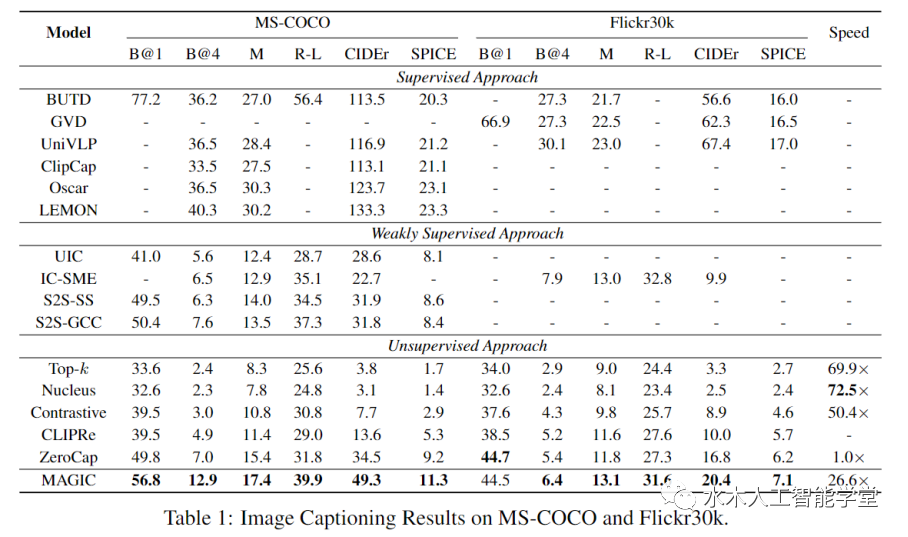


文献来源:机器之心
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
评论