
人体姿态估计、识别与生成最新技术一览

极市导读
本文按照人体姿态的三大分类:Pose Estimation、Pose Recognition、Pose Generation进行了非常详细知识的整理归纳,文章主要讨论研究思路,结合了脑图帮助理解。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
主要讨论研究思路,不过分追求性能。全文结合个人经验,如有纰漏,欢迎指正。
2019年底到2021年初,算是入坑一年了。大大小小的论文总共看了200多篇,觉得是时候要整理归纳一下了。为了方便区分,按细分领域简单梳理成了脑图,每一部分可以配合正文具体看,完整的脑图也放到了文末的链接。
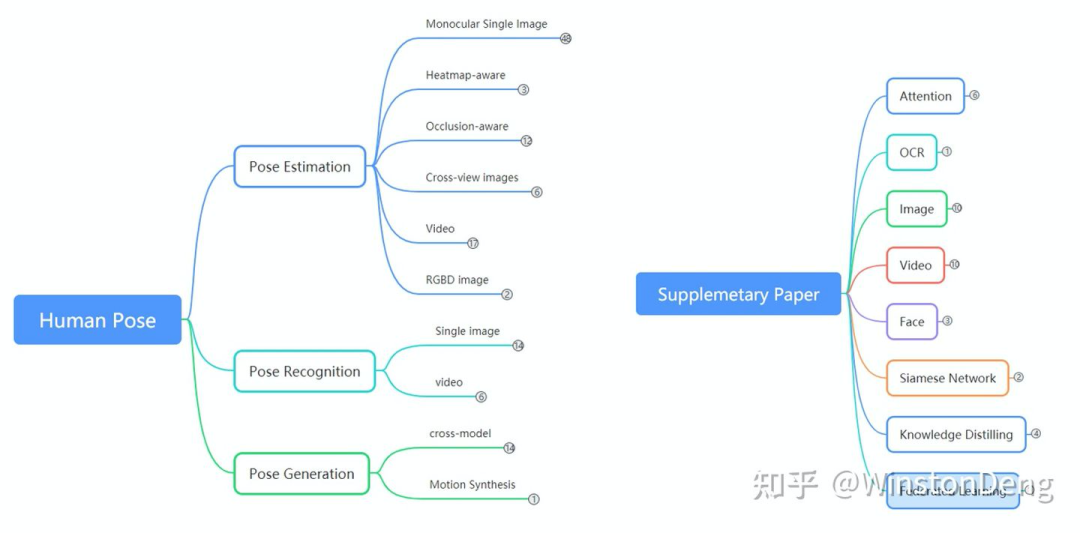
本文只针对 human pose 领域的研究进展,结合自己的理解感受简单梳理一下这个领域。
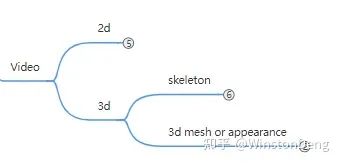
1. Pose Estimation
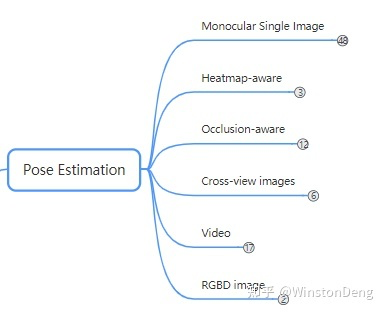
对于 Human Pose Estimation 这个任务来说,最终面向的使用场景是对视频流进行实时的姿态估计,而且至少要像人类一样能够适应各种复杂场景,并且最好是三维人体。
但是实现起来需要循序渐进,因此最简单的样例场景就是:从一张图像中识别一个人,且只需要 2d 的骨架。单人能够做好后,再扩展到一张图像识别多个人。2d 骨架做好后再扩展到 3d 骨架。3d骨架有了,再扩展到三维的形体、纹理。这部分对应到 Monocular Single Image。
传统的计算机视觉方法,会考虑深度信息的使用。例如 kinect摄像头可以采集深度信息,进而可以用模式识别来估计人体姿态。而在深度学习时代,这以方向在理论上也值得进一步挖掘,所以对应到RGBD image。
单视图做的差不多了,那自然就开始考虑多视图。这里的多视图更多指的是同一时刻的不同角度的图像。这部分对应 Cross-view images。
平行的,还有视频流的情况,对应 Video。这里主要指的是同一视角的多帧场景,当然也包括少部分多视角情况。
不论哪一种输入源,在做人体姿态估计时,都会遇到一些共同的挑战,最主要的就是遮挡。一部分是其他物体的遮挡,一部分是人与人相互之间的遮挡(人群聚集)。所以有必要单独对这一问题进行分析,对应到 Occlusion-aware。
最后要讨论的是 Heatmap-aware。目前绝大多数的 Pose Estimation 方法都是采用 heatmap 方式进行监督,而 heatmap 还需要再后处理一次才能得到最终的坐标。heatmap 本身有误差,转换坐标的过程存有误差,导致最终产生累计误差。这也是一些方法难以再提升的原因。
1.1 Monocular Single Image
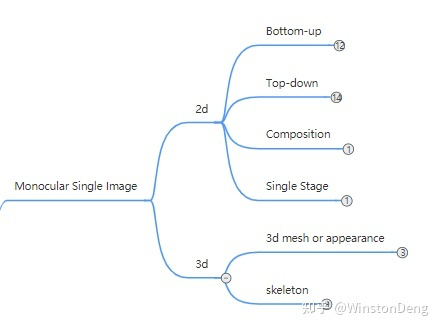
1.1.1 2d
最直观的,是从图像中获得 2d 的人体骨架信息,即需要知道人体关节的位置以及关节的连接关系。对于单人的情况,其实只需要关节点的位置就好了。因为每个关节的类型是不同的信道,而这在神经网络之外是可以预先知道的,所以拿到各个关节的位置,再按预先定义的顺序连起来就是一个人的完整骨架。
经典之作:Stacked Hourglass for Human Pose Estimation。从图像纹理到人体骨架,本身是一个信息降维、信息过滤的过程,因此需要堆叠多层卷积。而通过监督产生的heatmap需要与输入是同样的size,因此还需要上采样的过程将分辨率还原。
多人情况下,人数是我们无法预知的,那需要怎么做呢?有两种思路:Top-down, Bottom-up。
Top-down: 先用目标检测框到每个人,再对每个框进行单人姿态估计。
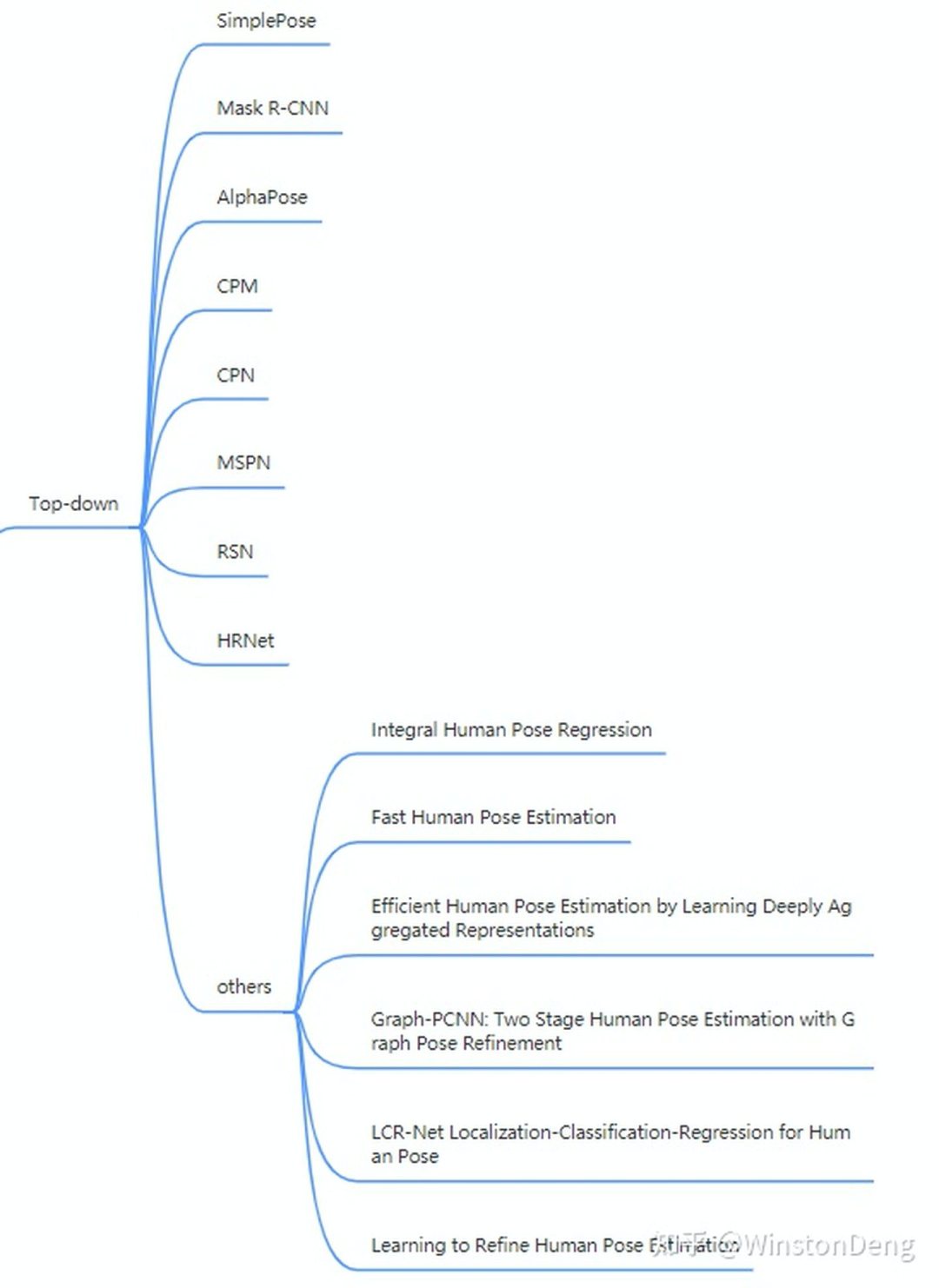
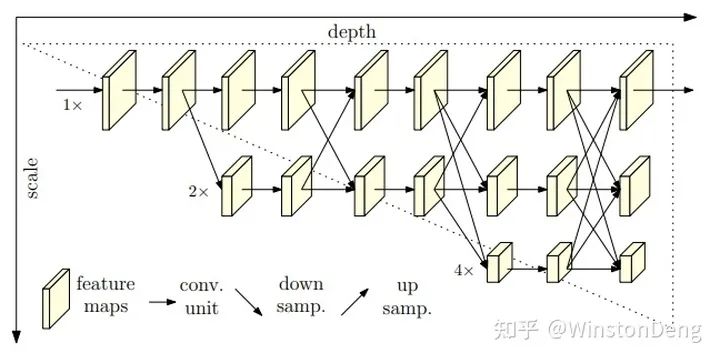
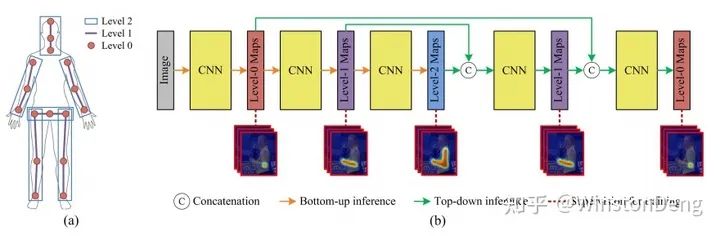
Top-down 将整个过程分为人体检测、单人姿态估计两个阶段。依赖于成熟的目标检测,更多的工作聚焦于单人姿态估计这个阶段。总体来看,主要工作集中于空间上多尺度、多阶段的信息融合,以适应不同分辨率、不同大小的局部区域。堆叠的设计一方面加深了网络可以提取更深度的信息,另一方面暗含了从粗到细的渐进监督原则。【SimplePose~HRNet】
这里贴一个上交卢策吾老师的 AlphaPose 在复杂图像情况下的结果(高斯模糊、运动模糊、暗光、强对比度、图像破损)。虽然方法上没有针对性处理,但还是具有一定的鲁棒性。个人的推测是训练数据包括了复杂的模态,以及网络的强大表征能力。

除了直接从 heatmap 获得关节点的这种方式,还有其他平行的姿态估计方法吗?有的,一个是基于图,一个是基于模板。
先说基于图的方式。人体骨架结构可以被看做一个有明确连接关系的图,因此自然会人有用 Graph 的方法来表示人,然后用 GNN/GCN 来进一步学习这种结构化约束。【Graph-PCNN, Learning to Refine Human Pose Estimation】
而基于模板的方式,核心思想是先给人“贴”一个差不多的骨架模板,然后再回归这个模板的各个关节点到 groud truth 之间的差异。【LCR-Net】
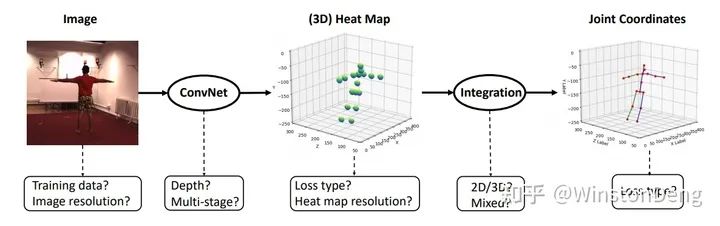
虽然大部分方法都在用 heatmap 作为网络的最终产物(heatmap到坐标的过程是不可导的),但是其实可以将 heatmap flatten 之后再多加一层 softmax ,从而得到最终的坐标值,使得整个过程是用坐标值监督且完全可导。【Integral Human Pose Regression】
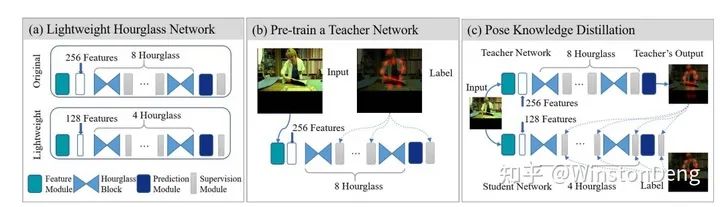
模型的性能是一方面,在实际部署时,模型的大小也十分关键。为此需要对现有的模型进行压缩。那有没有什么办法在压缩的时候尽可能少的降低性能呢?一个做法是用大模型对小模型进行知识蒸馏。具体的,大模型与小模型结构类似,在每个阶段用大模型的 feature map 对小模型的 feature map 进行监督。【Fast Human Pose Estimation】
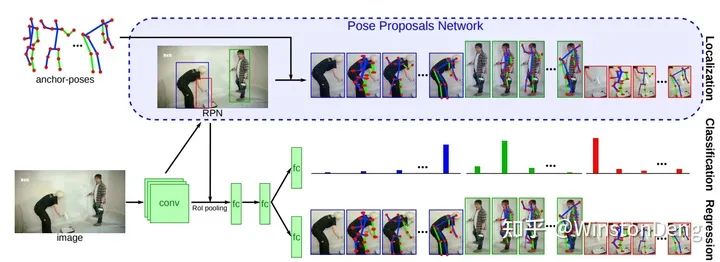
Bottom-up: 先一次性估计出所有的关节点,再估计每个肢体的位置(即关节点之间的连接关系)或者关节点的归属(同一个人的关节的归属标签应该一致),最后连起来得到多人。
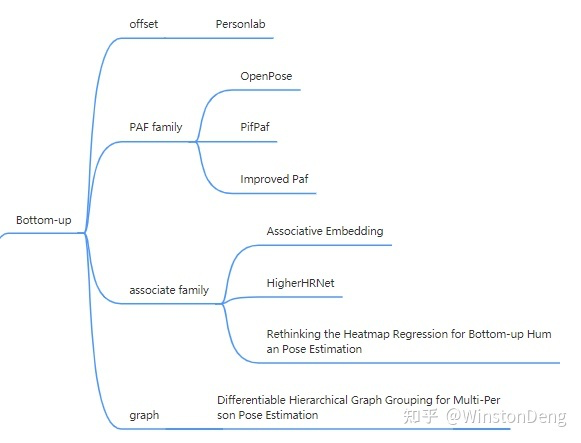
Bottom-up 除了估计关节点位置外,还需要估计各个点之间的关系。前者同单人姿态估计,而后者才是重点。目前对于关节点之间关系的表示主要为两大类,一类是肢体的表示,另一类是归属的表示。
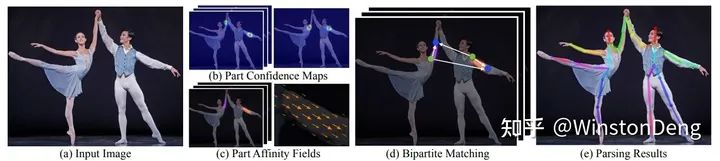
肢体的表示指的是从网络中估计出肢体的空间位置,以此为依据对之前得到的零散的关节点进行“组装”。这里我归纳到 【PAF family】。
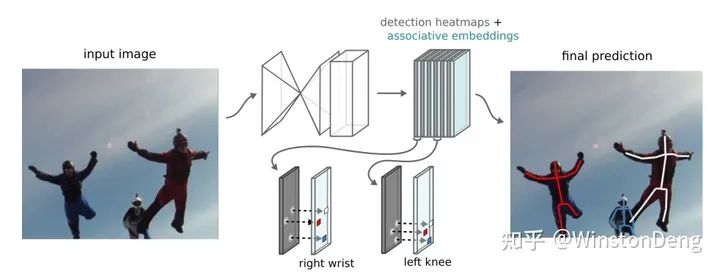
除了肢体,还有一个直观的想法是能不能得到一个表示归属的标签,类似id,同一个人的不同点都应该是同一个标签值。但是我们无法预知输入中可能会出现几个人,而且也不能预先指定具体的标签值。为了将不同的人区分开,要怎么做呢?可以看成聚类任务,即同一个人的不同关节点的 id 值应当接近(也就是接近他们的均值),不同人之间的点的 id 值尽量远离(也就是不同人的 id 均值尽量距离远),这里我归纳到 【associate family】。
说了这么多方法,到底效果怎么样,直接贴两张图。可以看到人少时,基本接近人类水平。但是人一旦多起来就会出现一些错误问题。这里的问题涉及到遮挡和聚集,之后单独会讲。


除了上述这些,还有一些偏向“阶段组合”的工作。
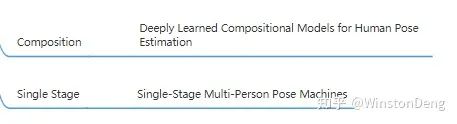
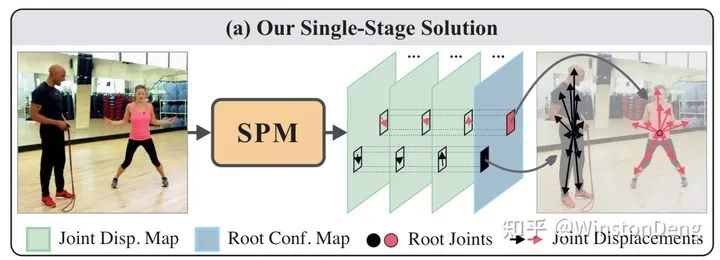
例如 【Deeply Learned Compositional Models for Human Pose Estimation】对 top-down 与 bottom-up 进行组合。以及【Single-Stage Multi-Person Pose Machines】将 top-down 中用人体中心点的估计视作人整体的定位,并以此来进行后续的其他关节的估计,从而实现 localization 与 pose estimation 两阶段的整合。
1.1.2 3d

图像虽然是 2d 形态,但其记录的客观世界仍然是 3d 的,所以在道理上是可以从图像中提取出三维人体信息。基础的信息当然是人体骨架,额外的还要有形体和纹理。
3d skeleton
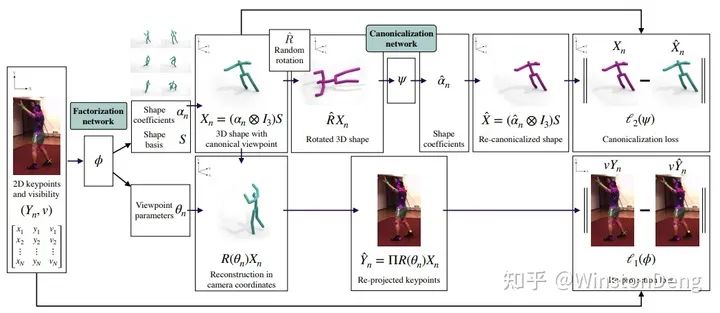
对于 3d 骨架的估计,有一类工作是延续 Non-rigid Structure from Motion 的思路,即认为 2d矩阵 = 3D矩阵 * 相机矩阵。【nrsfm】
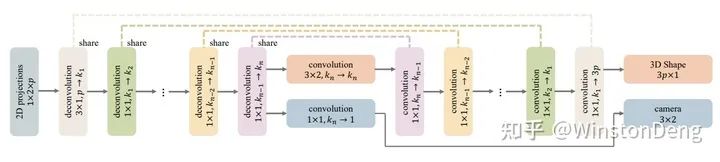
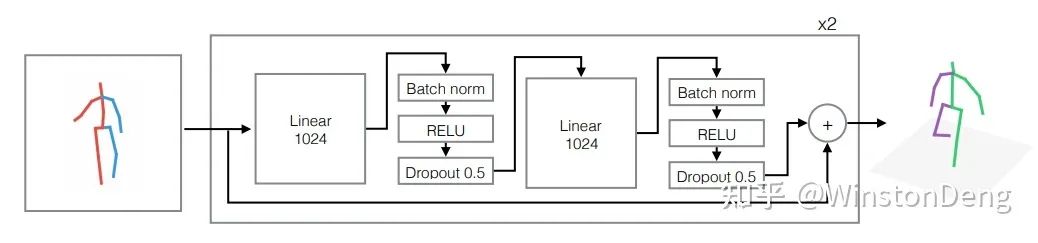
还有一类比较暴力,是先获得 2d 骨架坐标,再从2d pose 直接归回出 3d pose。【A simple yet effective baseline for 3d human pose estimation】
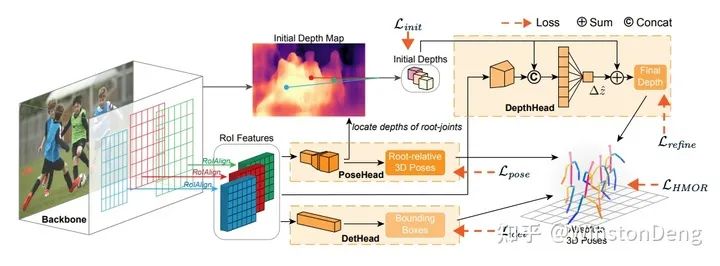
另外还有上交卢策吾老师的 HMOR,利用深度信息辅助出 3d。
其他的比较零碎,不再介绍。
3d mesh or appearance
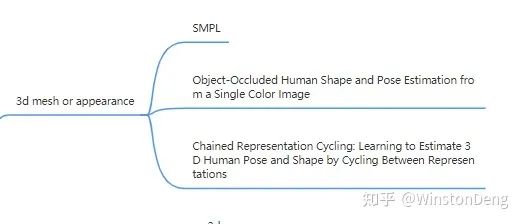
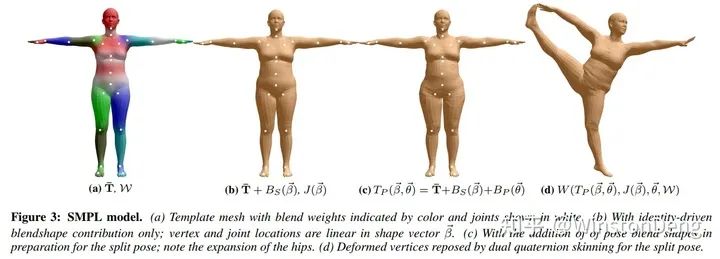
3d 形体这里主要介绍 SMPL 相关的内容。SMPL 是参数化人体模型,主要有两组参数β和θ。其中β代表是个人体高矮胖瘦、头身比等比例的10个参数,θ是代表人体整体运动位姿和24个关节相对角度的75个参数。
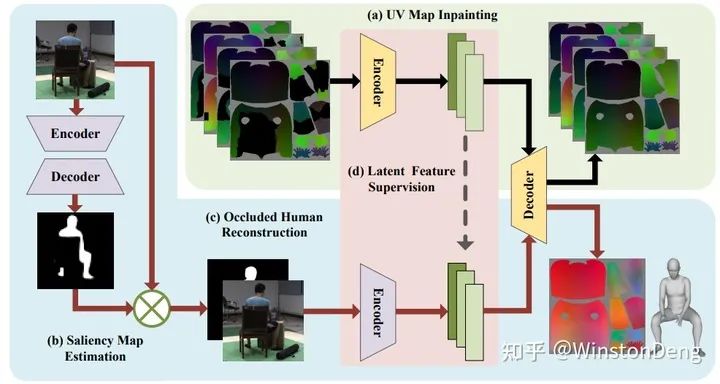
东南大学王雁刚老师的一个工作从单图提取出 SMPL 模型的 3d mesh,同时还解决了遮挡问题。其中的方法也比较有趣,值得仔细阅读。【Object-Occlued Human Shape and Pose Estimation from a Single Color Image】
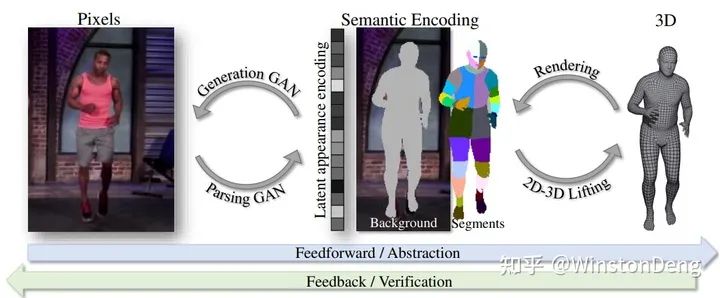
【Chained Representation Cycling】这篇也很有趣,提出了 image-segmentation-3d mesh 三个 domain 前后循环的思路,甚至可以实现完全的无监督。虽然效果上略差,但是思路还是比较新颖,值得学习。
1.2 Cross-view images
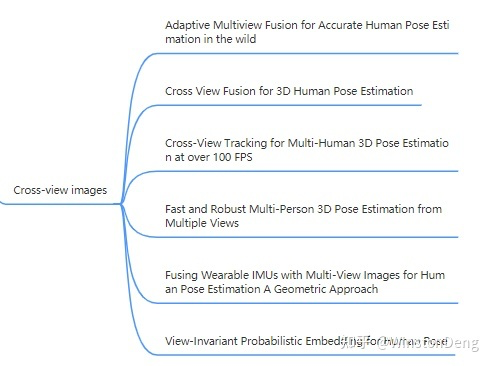
人类能够感知三维空间,很大程度上离不开两只眼睛组成的双视角系统。所以多视角下,更多聚焦于基于对极几何的 3d pose 的估计。这一领域的很多文章都是 MSRA 的曾文军老师,文章很细致,不再班门弄斧。
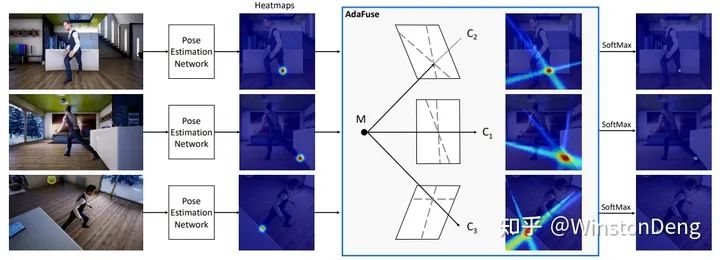
个人觉得比较有趣的是浙大的这篇【Fast and Robust Multi-Person 3D Pose Estimation from Multiple Views】,主要解决了多视角下多个人的自身匹配问题。方法上用 2d pose 做结构相似度度量,用 re-id 模型提取 feature 做纹理相似度度量,然后构造相似度矩阵并进行求解。文章里面公式很多,优化函数涉及了很多矩阵知识,但条例清晰,不得不让人佩服。
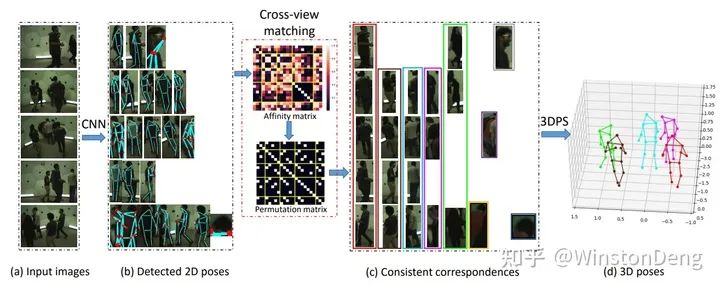
【View-Invariant Probabilistic Embedding for Human Pose】其实不算严格意义上的跨视角姿态估计。文章主要描述了一种直接从 2d pose 提取具有空间不变性的 embedding 的方法,以用于下游分析任务。
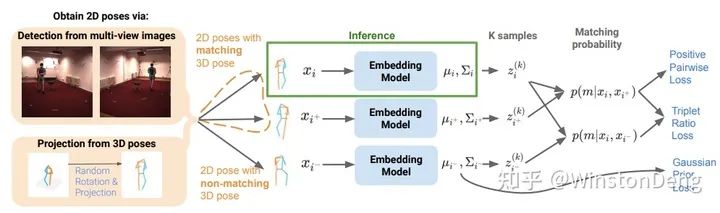
1.3 Video
在视频流场景下获得人体姿态,工程上可以逐帧采用单帧姿态估计的方法处理。但是这就忽略了时空一致性的约束。因此 video 领域的方法都致力于更好地挖掘和利用时空一致性信息,以提升单帧方法的表现。
video 2d
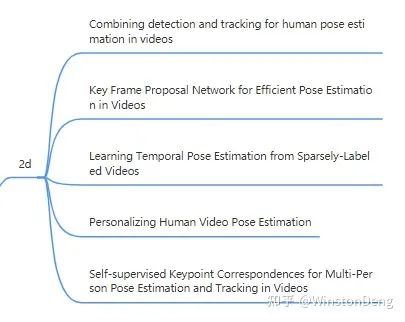
video 上的 2d pose estimation task 一方面针对的是数据标注(因为人工逐帧标注成本太高),另一方面针对人的track。
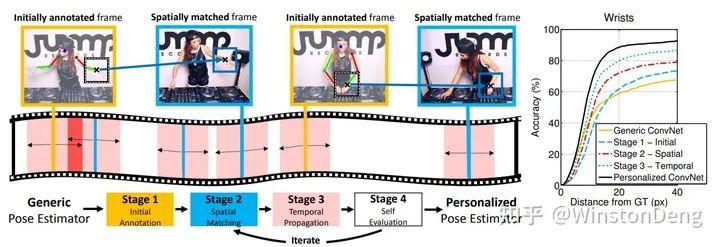
【Personalizing Human Video Pose Estimation】的核心思想是用少数几个标注帧的与未标注帧匹配,然后进行 pose 的扩展。空间上,直接使用图像匹配,认为匹配到的位置是同一个人的同一个部位。因为是基于图像匹配,所以是可以匹配到很远的帧。时间上,在标注帧临近的窗口范围内用光流进行 pose 的估计,只能局限于局部。
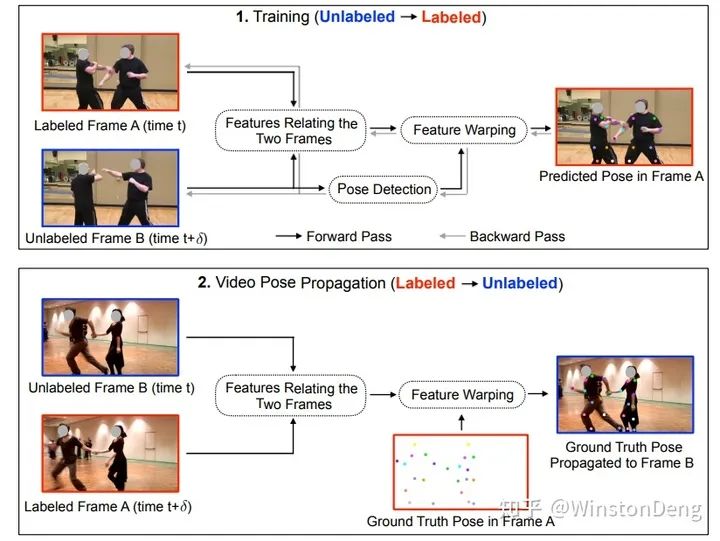
【Learning Temporal Pose Estimation from Sparsely-Labeled Videos】用标注帧的图像与pose,结合未标注的图像,生成未标注帧的 pose。有些类似知识迁移。
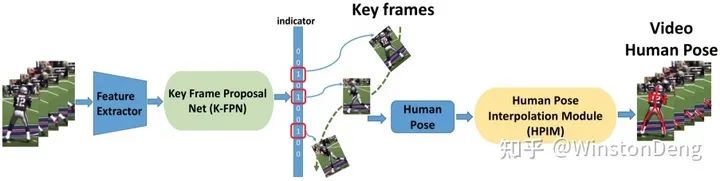
【Key Frame Proposal Network for Efficient Pose Estimation in Videos】的想法很有趣。不同于前两个方法,它不需要预先指定一些帧进行标注,而是用网络得出需要标注的关键帧。整体思路是先从video frames中提取关键帧,然后对关键帧进行pose estimation,最后基于关键帧的pose对其余帧进行pose推理。筛选关键帧的核心思路是,对所有帧的图像进行高维表示(图像用自回归得到的高维特征),整个video进而可以替换为一个高秩矩阵,然后用低秩矩阵逼近高秩矩阵,那这个最小的低秩矩阵就对应了关键帧。
【Combining detection and tracking for human pose estimation in videos】是对 video 进行固定长度的 clip 划分,然后通过不同 clip 重复帧的 pose 的相似度 (OKS) 来判定是否 merge 到一起,从而完成 track。此外还在 merge poses 时用了一些 trick 来解决人与人的遮挡问题。
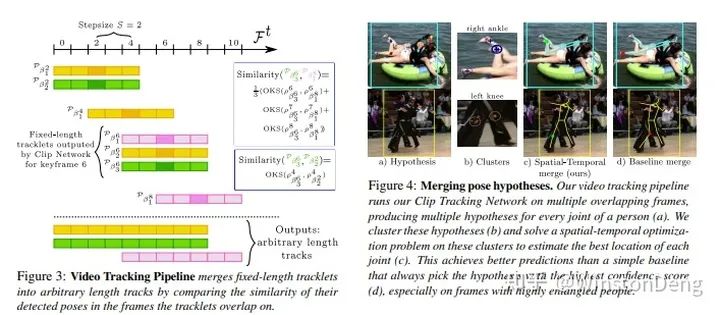
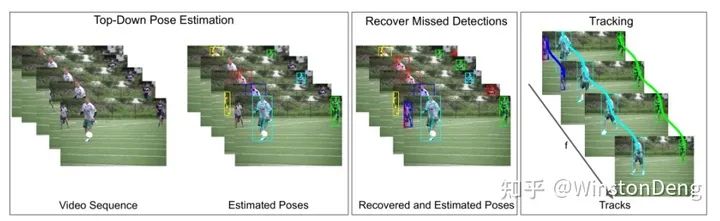
【Self-supervised Keypoint Correspondences for Multi-Person Pose Estimation and Tracking in Videos】则是提出了 affinity map,用来表示同一个人的同一个部位在帧间的对应关系。这样就可以通过预先用 top-down 得到的每一帧的 pose,结合帧间的 pose 对应关系,对缺失的 pose 和 detection 进行补充。
video 3d
video 3d skeleton 中最经典的就是 【VideoPose】,核心思想是对 2d pose sequence 用TCN 做卷积,得到中心帧的 3d pose。其实可以看做是单图出 3d pose (前文的 A simple yet effective baseline for 3d human pose estimation)的 TCN 版本。
之后的文章大多是基于 VideoPose 的改进。例如 【Attention Mechanism Exploits Temporal Contexts Real-time 3D Human Pose Reconstruction】额外增加了时序上的 Attention。【Motion Guided 3D Pose Estimation from Videos】主要是提出了一个新的 Motion Loss,用来刻画帧间的 pose 变化(个人理解为速度,其实对应到 infer 时的 MPJVE 指标)。【PoseNet3D】则是将 VideoPose 当作 teacher branch,对 SMPL 的 branch 进行知识蒸馏,从而实现 2d pose sequence 到 SMPL 模型的生成。
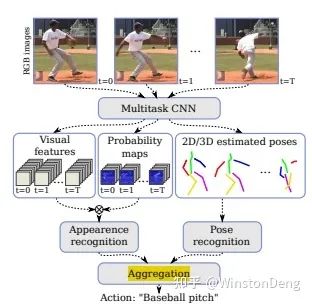
【2d or 3D Pose Estimation and Action Recognition using Multitask Deep Learning】这一篇是平行的估计 pose (Integral Pose的形式)、heatmap、visual feature,最后整合起来预测 action。个人理解这样的依据是同一种 action 类别中的 pose 的分布是类似的,而 action 又是与 pose 强相关的。
video 3d mesh 中,【Human Mesh Recovery from Monocular Images via a Skeleton-disentangled Representation】的主要贡献有两方面,一个是从图像中解耦出 pose 和 detail feature(可能是 appearance 和 context),再将其组合得到“高质量”的中间表示;另一个是将中间表示在时序上做乱序重排,进一步加强中间特征的表示,最后用TCN得到中心帧的结果。
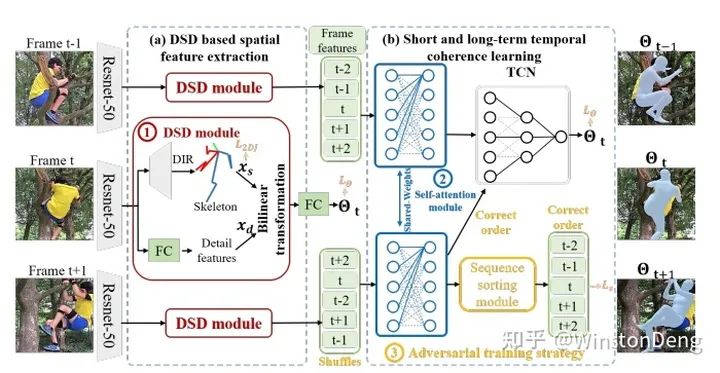
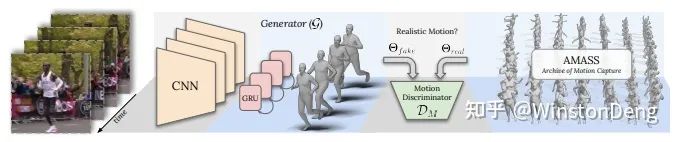
【VIBE】则是引入了 AMASS 这个庞大的 Motion Capture 数据集,用来判别 RNN 生成的结果是否真实。
1.4 RGBD image

RGBD在输入中额外多了深度图,可以有效帮助预测3D的结果。但是在实际应用中,由于摄像头成本问题,使用非常受限,因此这里收集了两篇只是作为理论上的补充,不做深入。
1.5 Heatmap distribution

鉴于目前绝大多数 Pose Estimation 的方法都是依赖于 heatmap 进行监督,因此 heatmap 本身以及 heatmap 到坐标的过程也非常值得研究。
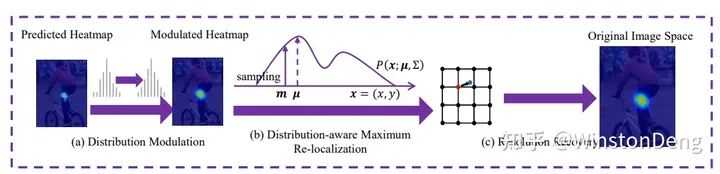
【DarkPose】主要在 heatmap 到坐标的映射过程中修正了 heatmap 的分布,从而产生更准确的坐标。
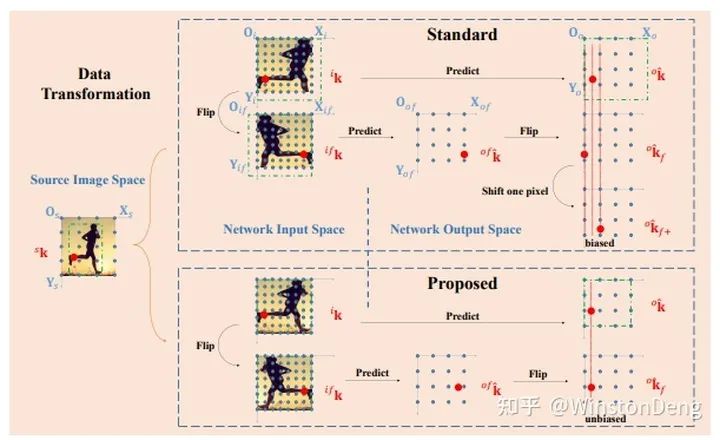
【UDP】则是发现了 flip pose 这一过程中存在的偏差并进行修正,具体的解释可以看作者亲自答:
黄骏杰:魔鬼在细节中:人体姿态估计中无偏的数据处理方法
https://zhuanlan.zhihu.com/p/92525039
【Rethinking the Heatmap Regression for Bottom-up Human Pose Estimation】提出要针对 bottom-up 中不同人的部位大小设计不同大小的 heatmap 高斯范围。
1.6 Occlusion and crowds
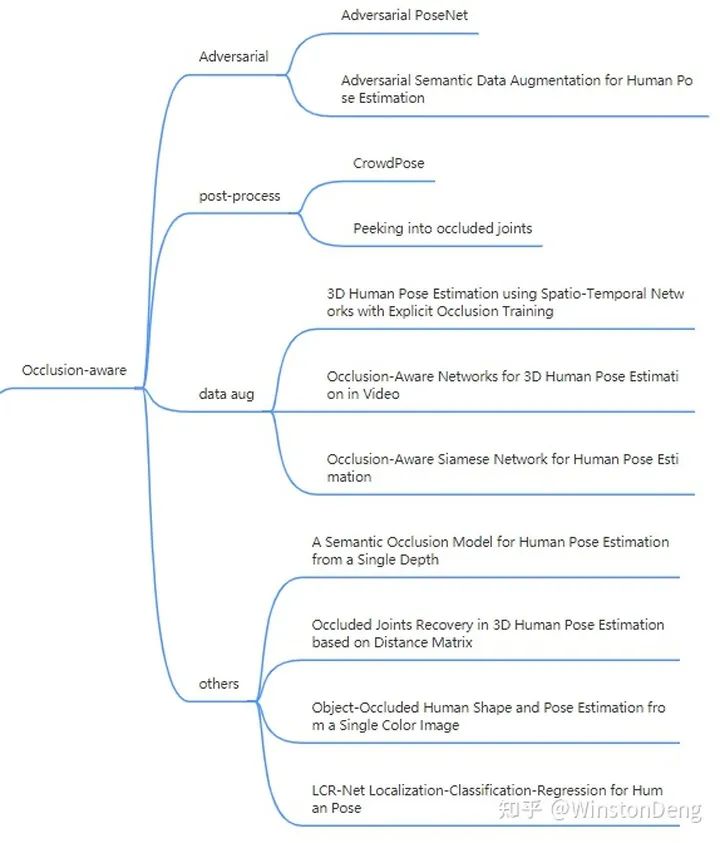
遮挡具体可以分为物体遮挡、自遮挡、人与人遮挡。
物体遮挡使得被遮挡部位的纹理缺失,因此对应位置的 heatmap 的 score 值比较低 或者 峰值错位。但是人类可以估计出一个差不多的位置,很大一部分信息来自于人体的结构关系,例如脚被遮挡,脚的位置可以顺着腿估计出来。自遮挡与物体遮挡类似。
而人与人的遮挡更为复杂,如果用 top-down 则可能会框不到聚集的人,如果用 bottom-up 则可能由于遮挡导致关节点间的关系错乱。另一方面,人的局部往往在位置上距离很近导致错把 A 人的部位识别为 B 人的部位,这一情况在人体纠缠的情况下更为场景,例如交际舞、摔跤等。
个人把遮挡问题的解决大致划分为四个方面:对抗、后处理、数据增广、其他。
Adversarial
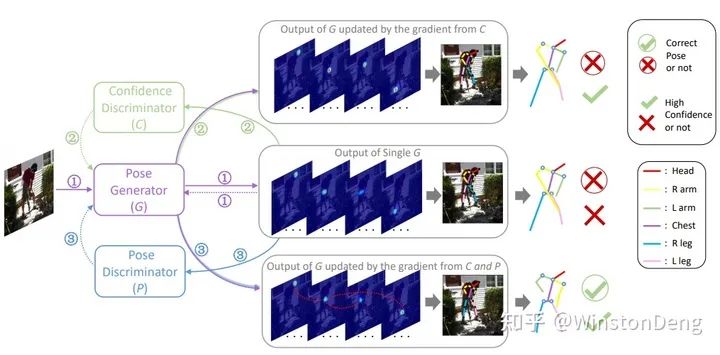
【Adversarial PoseNet】把 pose estimation 看作 generator,对“生成”的 pose 进行判别。文章设计了两个判别器,一方面进行 pose 结构合理性的判别,使得 pose 的结果尽可能接近合理的动作;另一方面进行 heatmap confidence 的判别,使得被遮挡部位的 heatmap 尽量从低 confidence 变到高 confidence。
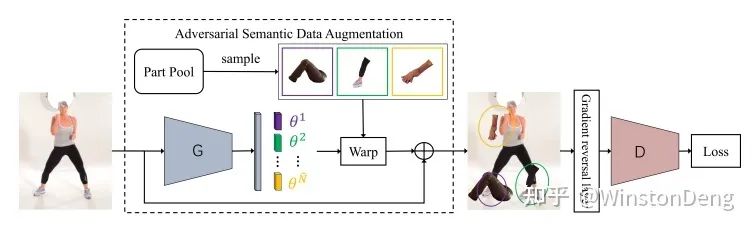
【Adversarial Semantic Data Augmentation for Human Pose Estimation】则与 Adversarial PoseNet 相反,它把 pose estimation 看作 Disriminator,对 data augmentation module 生成 occlusion image 的结果进行判别。文章预先准备了一个 human part pool,然后将 sample 的结果 warp 到输入的 human image 中,从而构造遮挡数据。所以这篇主要针对是人与人遮挡的情况。
Post-process
后处理的过程则是要先进行 pose estimation,然后再进一步调整。
上交卢策吾老师的【CrowdPose】是在 AlphaPose 的基础上的拓展,所以主要工作集中在对 AlphaPose 结果的修正上。文章构造了人-关节图,把每个人看作一个节点,零散的关节点看作节点集合,其中每个边的权重是与某个人相关的关节的score值 (top-down 会在同一个人上产生多个可能的结果,每一组结果可以看成一个 graph)。通过求所有人的人-关节图的总体最大边权来实现人与肢体的归属划分。在构造关节的节点时,把位置邻近的同类型关节点视作同一个位置。而每个人的节点则用目标检测框来表示。另外文章还贡献了聚集人群的数据集,根据不同的遮挡程度做了均衡。
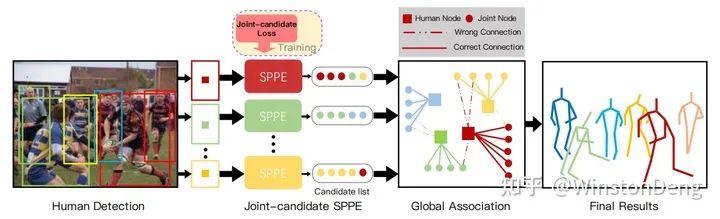
【Peeking into occluded joints】考虑到被遮挡部位的估计需要满足纹理和结构的双重约束,因此先用 AlphaPose 从图像纹理上进行粗略估计,然后再构造人体的 graph ,用 GNN 进行结构上的精细估计。同样,文章也提供了一个双人遮挡的数据集(例如交际舞、摔跤等)。
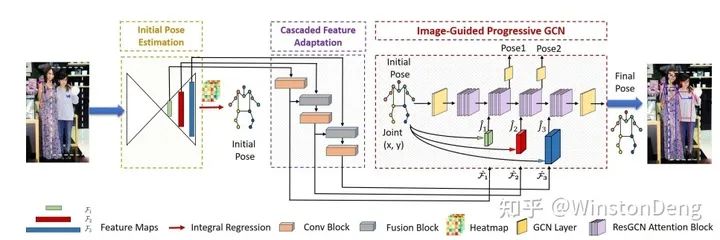
data augmentation
个人认为,目前的深度学习的方法设计是一方面,高质量大范围的数据仍然是王道。所以不少工作是从数据驱动的角度入手,设计了一系列的数据增广的方法。
【3D Human Pose Estimation using Spatio-Temporal Networks with Explicit Occlusion Training】用帧间和帧内的“置零”来模拟遮挡的情况。具体来说,为了模拟人突然被遮挡,文章对 heatmap 进行跳帧 mask,也就是整体置为 0。而对于帧内的遮挡,则是随机对某些部位的 heatmap 进行置 0。
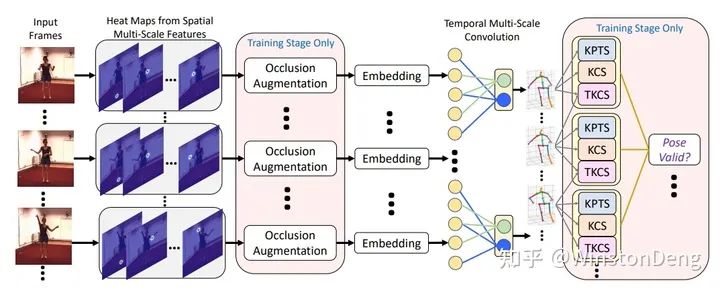
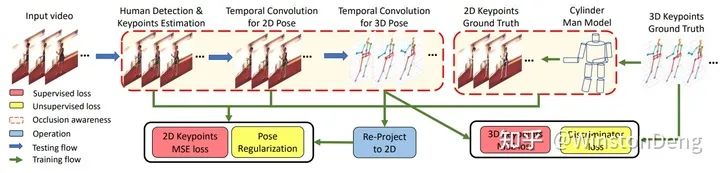
【Occlusion-Aware Networks for 3D Human Pose Estimation in Video】用 3D pose 做随机旋转来生成更多的 3D 数据,且对关节点随机置零来模拟物体遮挡。文章还用提出的 Cylinder Man Model 来生成自遮挡的 occlusion label,使得网络可以对 occlusion label 进行统计,进而设计正则化惩罚。在处理遮挡方面,文章用 TCN 对 2d pose 和 3d pose 的非遮挡点进行监督,然后对遮挡点进行正则化。
【Occlusion-Aware Siamese Network for Human Pose Estimation】自己构造遮挡数据,然后输入到孪生网络中,期望遮挡与未遮挡的图像有一样的 pose estimation 结果。在构造遮挡数据时,对于一个 human image,对于已经存在遮挡的位置手动添加 mask,对于未被遮挡的位置,随机截取 image patch 进行覆盖。
others
【A Semantic Occlusion Model for Human Pose Estimation from a Single Depth】是从深度图中用回归森林的方法进行姿态估计,个人对这部分理解不是很清楚,为了避免误导不做介绍。
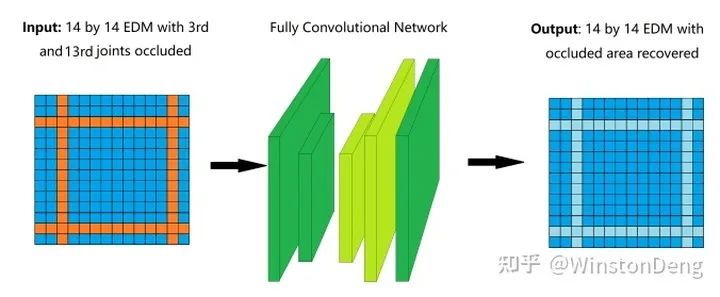
【Occluded Joints Recovery in 3D Human Pose Estimation based on Distance Matrix】比较粗暴,直接对遮挡的 EDM (Joint Euclidean Distance Matrix)用全卷积网络进行处理,期望得到修正后的结果。
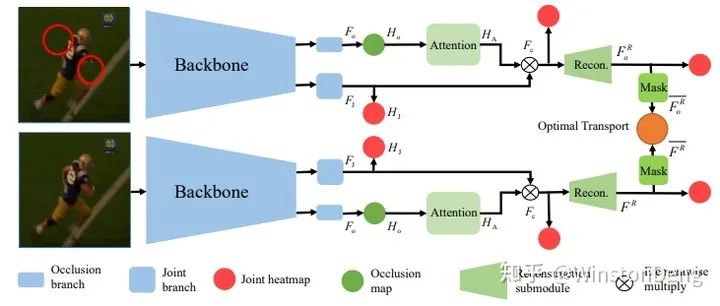
【Object-Occluded Human Shape and Pose Estimation from a Single Color Image】比较巧妙地把解遮挡问题看作 3D mesh 恢复 UV map 的过程。传统的 UV map 上的值是 rgb,这里替换为 xyz,由于 SMPL 的 3d mesh 已经约束了 shape,因此只需要从图像中恢复坐标。而从图像恢复 UV map 的过程是用 UV map 的 encode-decode 知识蒸馏来完成的。
【LCR-Net】前文介绍过,由于是基于 pose 模板的回归,可以保证结构性约束,因此一定程度上也可以解决遮挡问题。
2. Pose Recognition
Pose 作为人体的结构化表示,可以非常有效的表示人体信息,也因此会被应用于动作识别等下游分类任务。个人认为,分类任务更偏向于获得信息的有效表征,在模型的设计上很有讲究,毕竟得做到每一路的信息产生、不同分支间信息融合有理有据。这个过程非常类似于人类的理解过程,也因此不同于 Pose estimation 这样数值计算的测量任务,更具有 AI 味儿。
类似 Pose estimation,从输入源上应该分为 Single image 和 video。但是由于个人阅读所限,需要特别说明的是,我这里的 Single image 中都是 HOI,video 中都是 Action Recognition。
2.1 Human Action Recognition
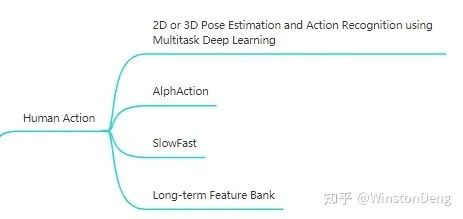
【2D or 3D Pose Estimation and Action Recognition using Multitask Deep Learning】前文也介绍过,一大特点就是将 Pose estimation 与 Action Recognition 进行结合。
何凯明的【SlowFast】模拟人眼对于快慢信息流的不同反应,设计了 Slow 和 Fast 两条branch。Slow 流帧数少,但是空间 size 大;相反,Fast 流帧数多,空间 size 小。
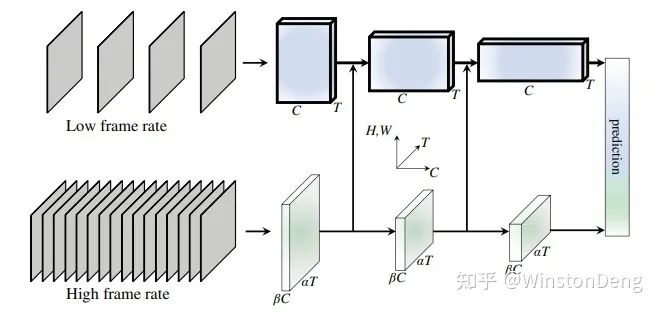
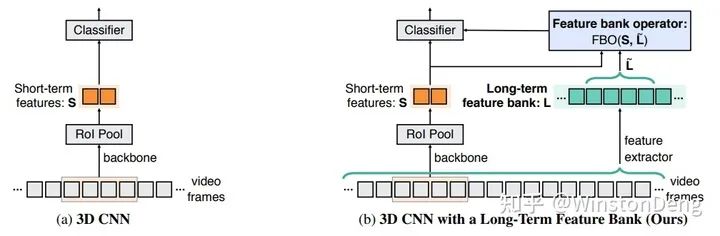
而何的另外一篇【Long-term Feature Bank】则是仿照人脑的记忆,提出了 Feature Bank 来存储中间的特征,用于之后的卷积过程。因为卷积在结构上受限于局部,要想融合全局的信息或者远处的信息,Memory 是一个很好的选择。
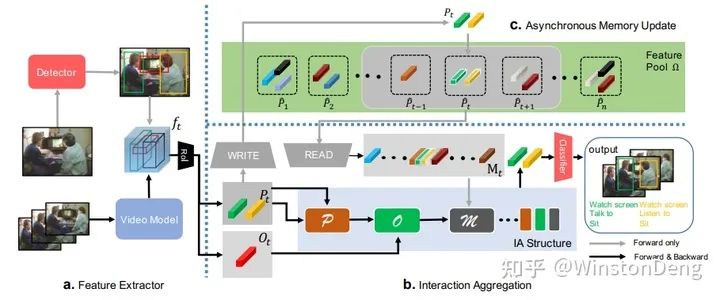
这种存储中间 feature 当作 Memory 服务于局部的思想被广为应用,卢策吾老师的 【AlphAction】就是其中一个。这篇工作借鉴了 HOI 的思想,分别提取 Human,Object 的 feature,然后结合 feature bank 的 feature 得到最终的表征。
2.2 Human Object Interaction
HOI 不同于普通的行为识别,更多的是识别人与物体的交互关系,因此在信息提取上必然离不开 human 和 object。至于交互关系这一信息,可以显式的去学(例如学人与物的连线),或者也可以隐式的去学(在网络的高维空间做信息融合),毕竟“关系”不再是一个简单的视觉任务,更偏向于概念上的关联与理解,甚至后续的工作开始于 NLP 有关联。同其他分类任务一样,HOI 也面临歧义、zero-shot 等问题。
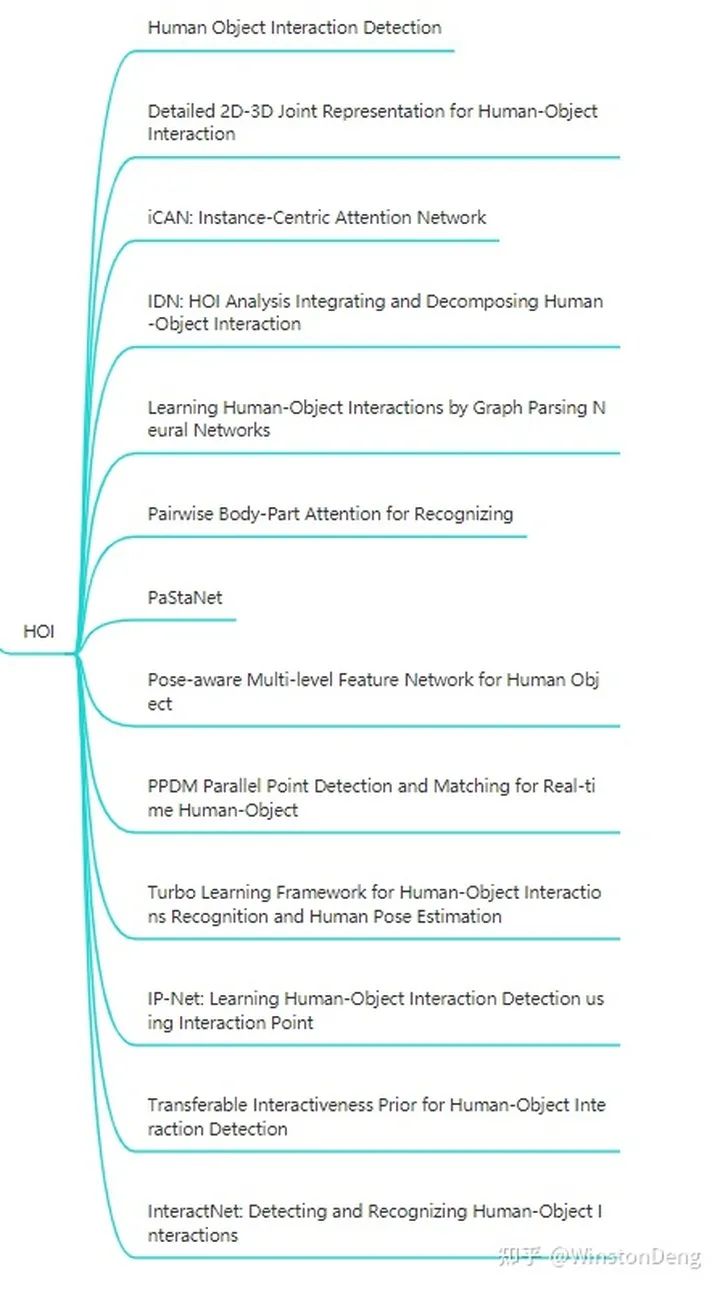
HOI 这个领域是近几年新兴的领域,指标没有其他领域那样刷的那么高,但是相关的文章已经有不少了。
早期的有何凯明的 InteractNet,提出了
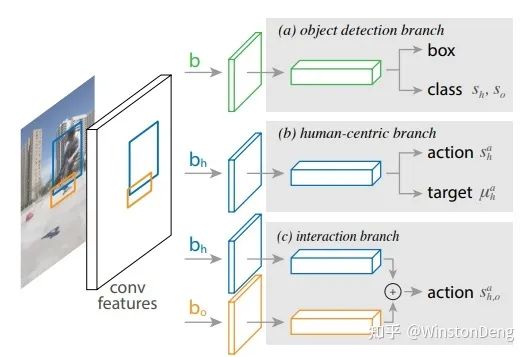
作为 Pose 领域的资深专家,卢策吾老师在这个方向的文章也不少,主要工作集中在他的一个博士李永露,他本人还整理了 HOI 领域的文章以及数据,非常详细清晰,具体可以看他的 github:
https://github.com/DirtyHarryLYL/HOI-Learning-Listgithub.com
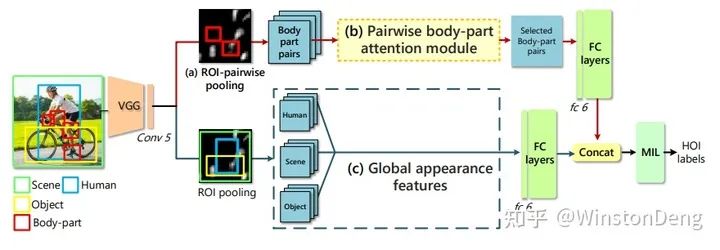
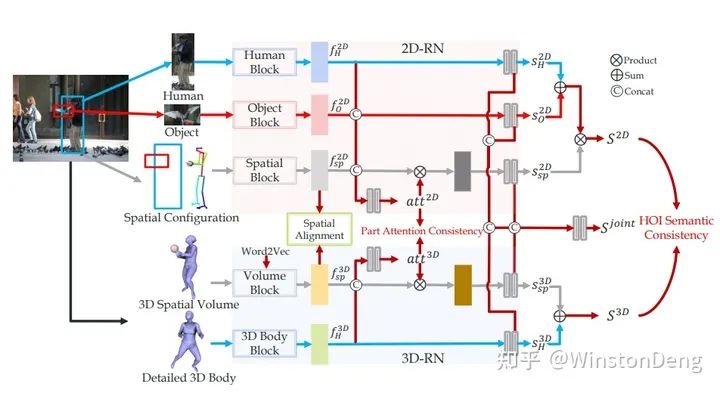
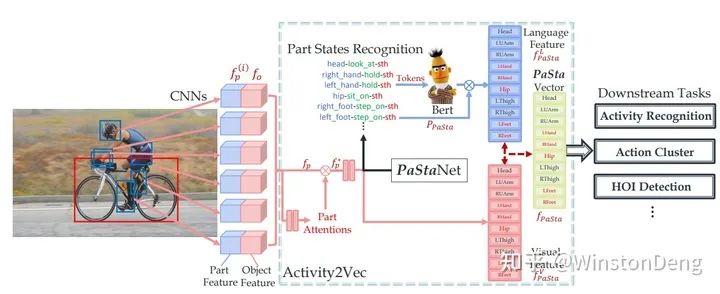
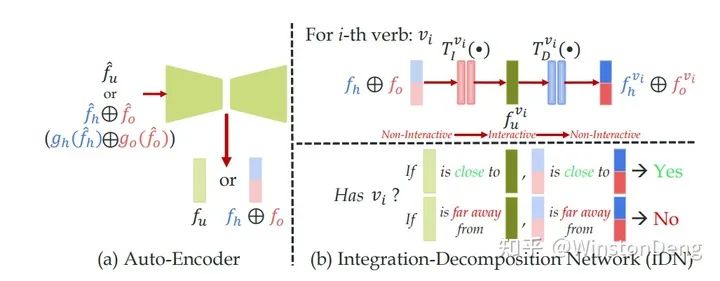
这里就简单描述一下他们的工作,从 2d pose part attention 的信息与 detection 信息的融合【Pairwise Body-Part Attention for Recognizing Human-Object Interactions】,到 3d pose 于 3d object 的关系 【Detailed 2D-3D Joint Representation for Human-Object Interaction】,甚至是 利用不同身体部位与目标物体的稀疏关系构建类似 NLP word embedding 那样的语义化视觉信息 【PaStaNet】。而在 【IDN】中对于 human+objectA-objectB 这样的组合已经是非常 NLP 的操作了。
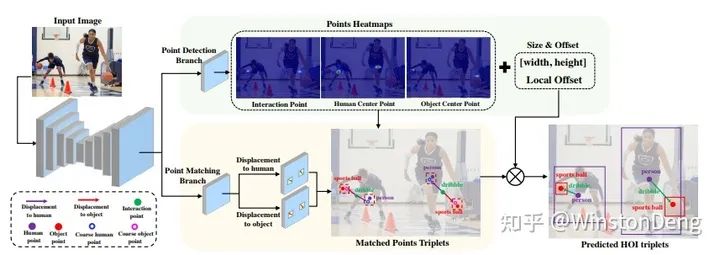
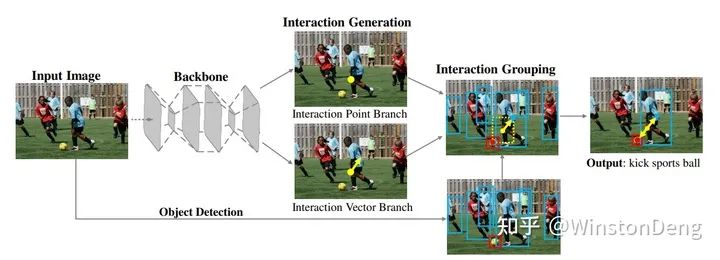
显式的去学人与物的关系的文章主要是两篇:【PPDM】和 【IP-Net】,两者思路类似,都是学习 human 与 object 中心点连线的 offset。个人感觉 PPDM 的更完整一些。
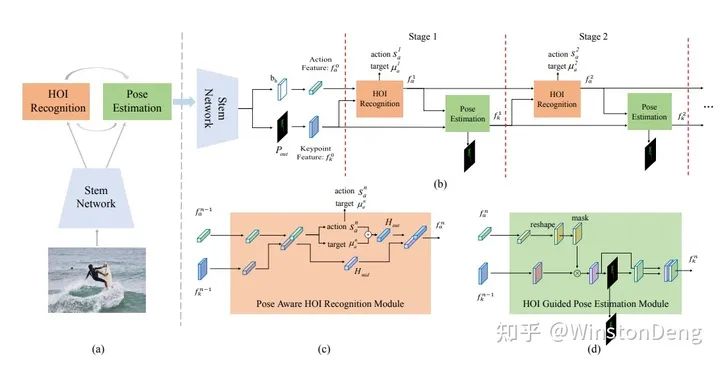
【Turbo Learning Framework for Human-Object Interactions Recognition and Human Pose Estimation】这篇则是将 Pose Estimation 和 HOI 两个阶段拼接并多次堆叠,设计成 Multi-task 的方式进行推理。
自己有在一些项目尝试修改,但是效果不是很好,加上一些主客观原因没有在这个领域继续研究,所以其他的文章只是去看一下理论发展情况,没有仔细去看,这里也不多讲。
3. Pose Generation
更为有趣的工作是实现动作的驱动或生成。下面就从跨模态生成、动作合成两方面来梳理。
3.1 cross-model generation

这里对跨模态生成动作主要分成三部分:语音生成动作、音乐生成动作、文本生成动作。
语音和音乐的共同点在于,它们是连续的、有节奏的、有语义的。区别在于语音的语义与语言或语言含义强相关,而音乐的语义则与风格强相关。而对于文本来说,本身是稀疏的、有语义的。
从发文章的角度来看,生成任务主要是抢第一、贡献数据集、实现泛化、追求 End2End,理论上的扩展性与丰富性相对少一些。而且整体上比较工程。
speech2pose
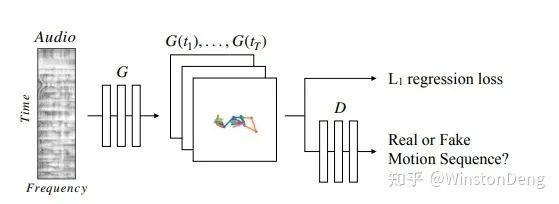
语音方向的开篇之作应该是 【Speech2Gesture】,文章用 U-Net 作为生成器完成 speech audio domain 到 pose domain 的映射。作者发现每个人在讲话时的风格差异很大,因此对每个人都单独 train 了模型。
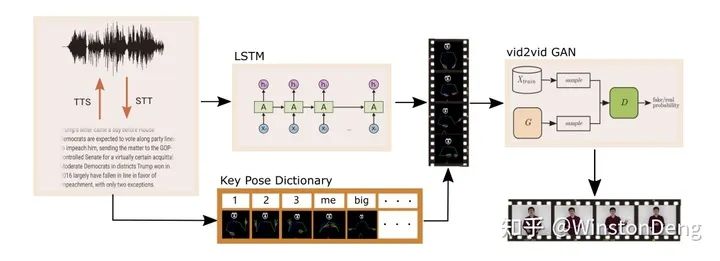
而【Speech2Video】则是在输入端结合了文本的信息,用 LSTM 完成 pose 的映射,并且对常见的 word-pose pair 构建 dictionary。
music2pose
音乐生成 Pose 我之前也有专门分析过其中的两篇,可以对这个细分领域有一个基本的理解。
WinstonDeng:[专题]跨模态转换——音乐生成舞蹈
https://zhuanlan.zhihu.com/p/149117246
text2pose
个人认为 pose 其实可以看成一种象形文字,可以存在一定的稀疏语义。因此文本到动作这个任务就开始有点像语言翻译了。
【Text2Action】中先是 train 了一个 language-pose-language 的 autoencoder,然后用 encoder 做 generator 进行对抗训练,是一个比较常规的 domain translation 的操作。
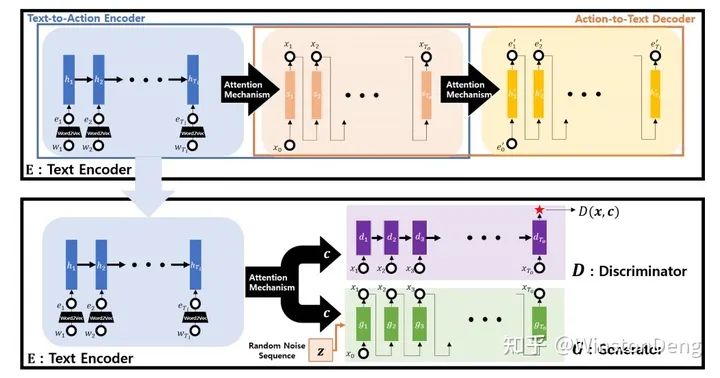
【Language2Pose】则是希望 language 和 pose 都可以 encode 到同一个 embedding 空间(拉近两个 domain 分布的距离),从而实现 decode 出 pose。自己试了一下,泛化能力很差,怀疑还只是强映射。
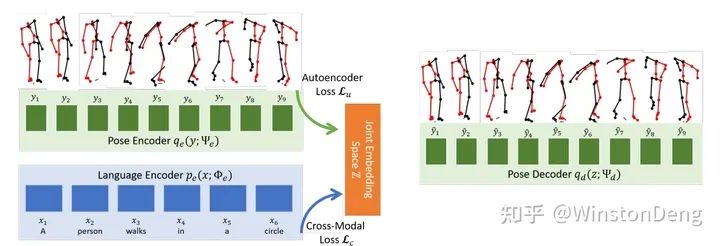
值得一提的是,文章的作者近几年一直致力于语言到动作的研究,具体可以看他的个人主页:
http://chahuja.com/chahuja.com
3.2 Motion Synthesis

动作合成说实话没有仔细看过,当初想了解存粹是为了好玩。从早期的 pix2pix,到 Nvidia 的 vid2vid 都可以生成可驱动的人。当然最近效果比较好的是 腾讯AI lab 的 【Liquid Warping GAN】。

推荐的代码工具:
(不是广告,真的好用)非常推荐大家用商汤的 Pose estimation 工具包 mmpose:
mmposegithub.com
基本集成了绝大多数方法,而且代码统一配置,无论是代码的工程化还是易用化都非常值得学习。另外商汤的 mmaction 也支持了很多行为识别的方法,值得一看。
mmactiongithub.com
写在最后
回过头来不难看出,Pose 的方向逐渐从基础的测量任务向下游的理解任务上发展,这在一些大组的研究方向上就可以窥探。这也对后入门的我来说,总有一些“代差感”和“无力感”,一些想法总是慢人一步。只能说想要发好的文章还真不是那么容易,需要更加细致的观察和深入的思考,当然也离不开广泛而扎实的理论基础以及工程能力。
还是古人那句话:路漫漫其修远兮,吾将上下而求索。
最后分享一下自己论文的脑图链接:
Human Pose 相关
https://note.youdao.com/ynoteshare1/index.html?id=0f2ed184fb4439b36c61f91938989d8c&type=note
其他泛读
https://note.youdao.com/ynoteshare1/index.html?id=214443c3ba483378998d447c4a0b4757&type=note
推荐阅读
