
北大计算机博士生先于OpenAI发表预训练语言模型求解数学题论文,曾被顶会拒绝
日期 : 2021年11月25日
正文共 :2805字
【导读】北大博士生沈剑豪同学一篇关于「用语言模型来解决数学应用题」的EMNLP投稿在综合评审时被认为不够重要,收录于Findings而没有被主会接收。有趣的是,OpenAI的最新工作与该论文的方法不谋而合,并表示非常好用。



拓展了特定任务的SOTA,但是对EMNLP社区而言,没有新的见解或更广泛的适用性; 有良好的、新颖的实验,并提出了全面的分析和结论,但使用的方法不够「新颖」。




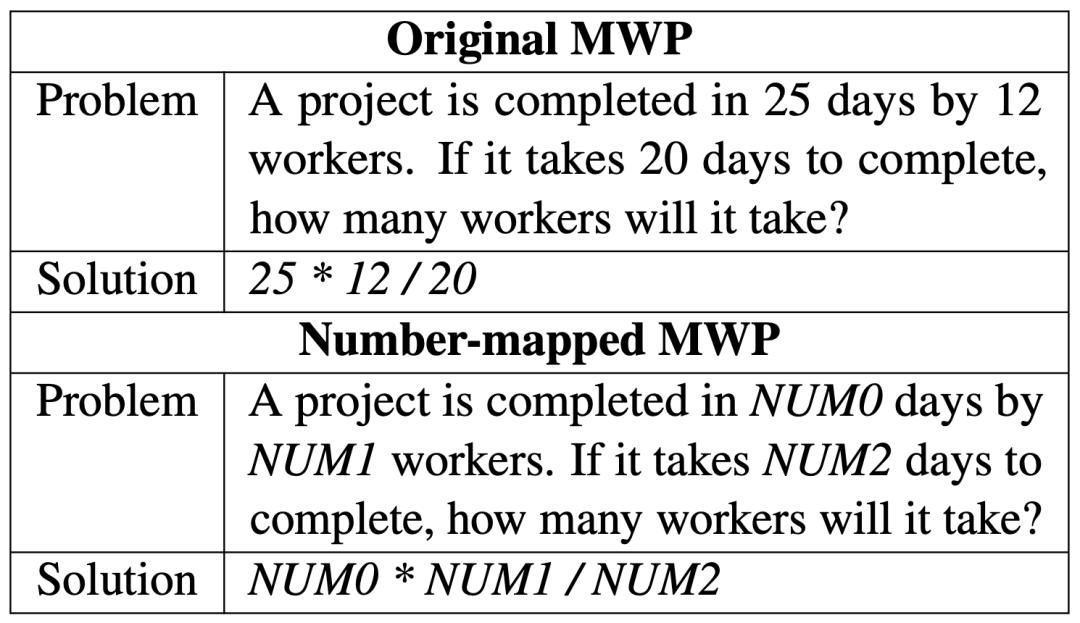
沈剑豪,尹伊淳,李琳,尚利峰,蒋欣,张铭, 刘群,《生成&排序:一种数学文字问题的多任务框架》,EMNLP 2020 Findings。该工作由北大计算机学院和华为诺亚方舟实验室合作完成。
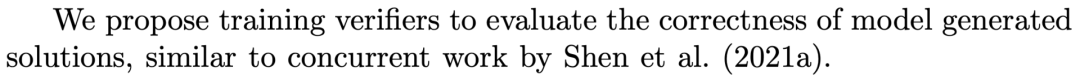

我们的工作与他们的方法有许多基本相似之处,尽管我们在几个关键方面有所不同。




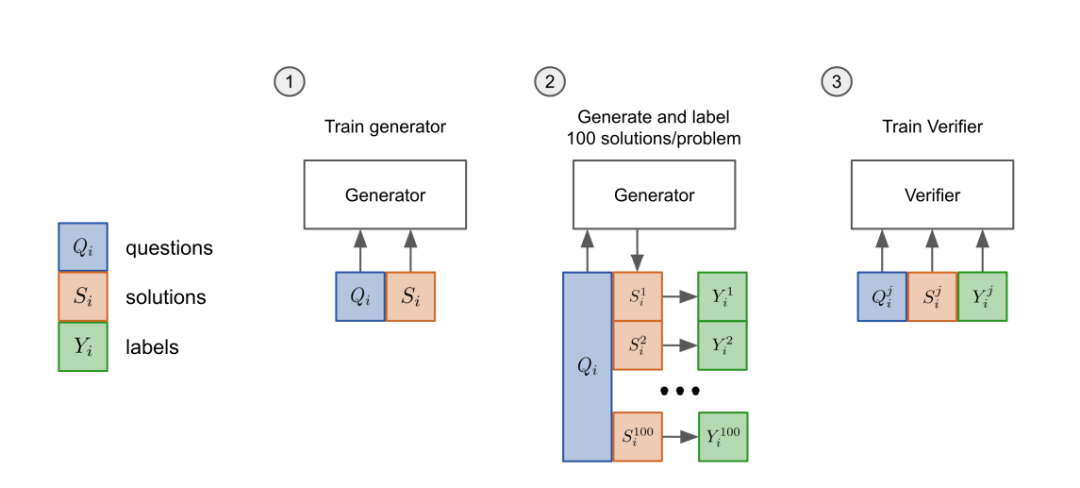
先把模型的「生成器」在训练集上进行2个epoch的微调。 从生成器中为每个训练问题抽取100个解答,并将每个解答标记为正确或不正确。 在数据集上,验证器再训练单个epoch。
— THE END —

评论