
北大计算机博士生先于OpenAI发表预训练语言模型求解数学题论文,曾被顶会拒绝

视学算法报道
视学算法报道
来源:EMNLP
编辑:好困 小咸鱼
【新智元导读】北大博士生沈剑豪同学一篇关于「用语言模型来解决数学应用题」的EMNLP投稿在综合评审时被认为不够重要,收录于Findings而没有被主会接收。有趣的是,OpenAI的最新工作与该论文的方法不谋而合,并表示非常好用。
北大博士生沈剑豪领衔的一篇关于「用语言模型来解决数学应用题」(Generate & rank: A multi-task framework for math word problems)的EMNLP投稿在综合评审时被认为不够重要,最终收录于Findings而没有被主会接收。

「审稿人普遍喜欢这篇论文,但这看起来是一篇边缘的论文。鉴于这是BART在数学问题上的应用,而数学问题的解决对于NLP来说并不是一个真正重要的任务,我怀疑这个任务的高度工程化解决方案的价值。」


拓展了特定任务的SOTA,但是对EMNLP社区而言,没有新的见解或更广泛的适用性; 有良好的、新颖的实验,并提出了全面的分析和结论,但使用的方法不够「新颖」。
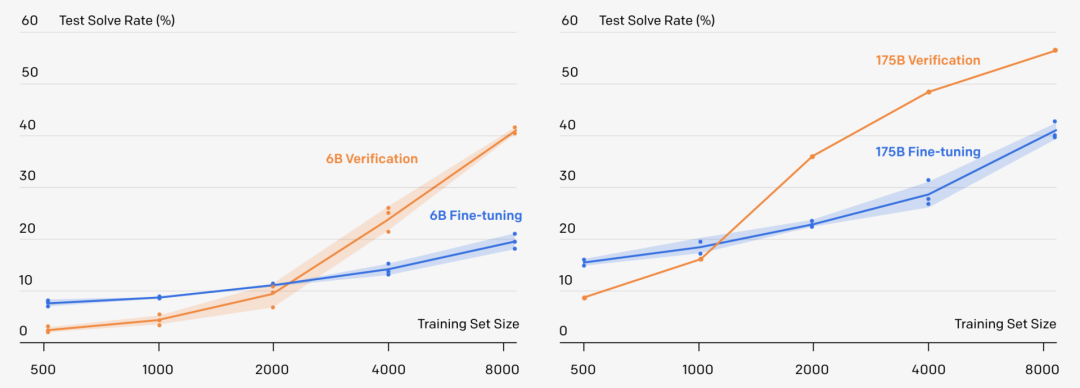
虽然,但是OpenAI觉得这个论文很重要



沈剑豪,尹伊淳,李琳,尚利峰,蒋欣,张铭, 刘群,《生成&排序:一种数学文字问题的多任务框架》,EMNLP 2020 Findings。该工作由北大计算机学院和华为诺亚方舟实验室合作完成。
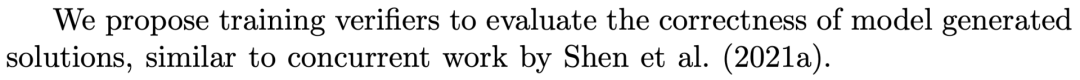

我们的工作与他们的方法有许多基本相似之处,尽管我们在几个关键方面有所不同。

语言模型能解数学题吗?
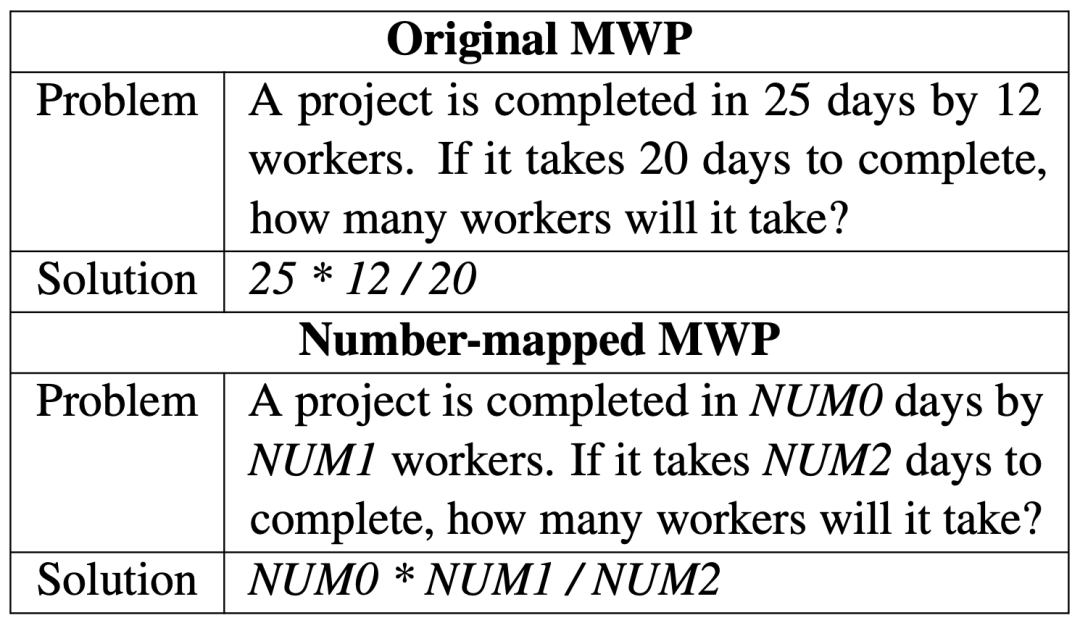
两者内容对比
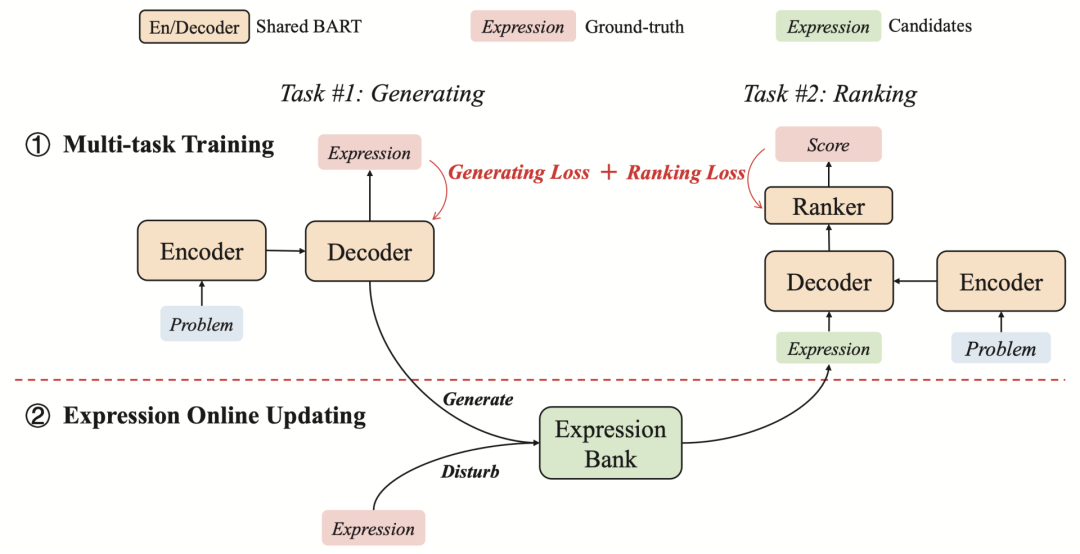
北大与华为诺亚的生成与重排序框架
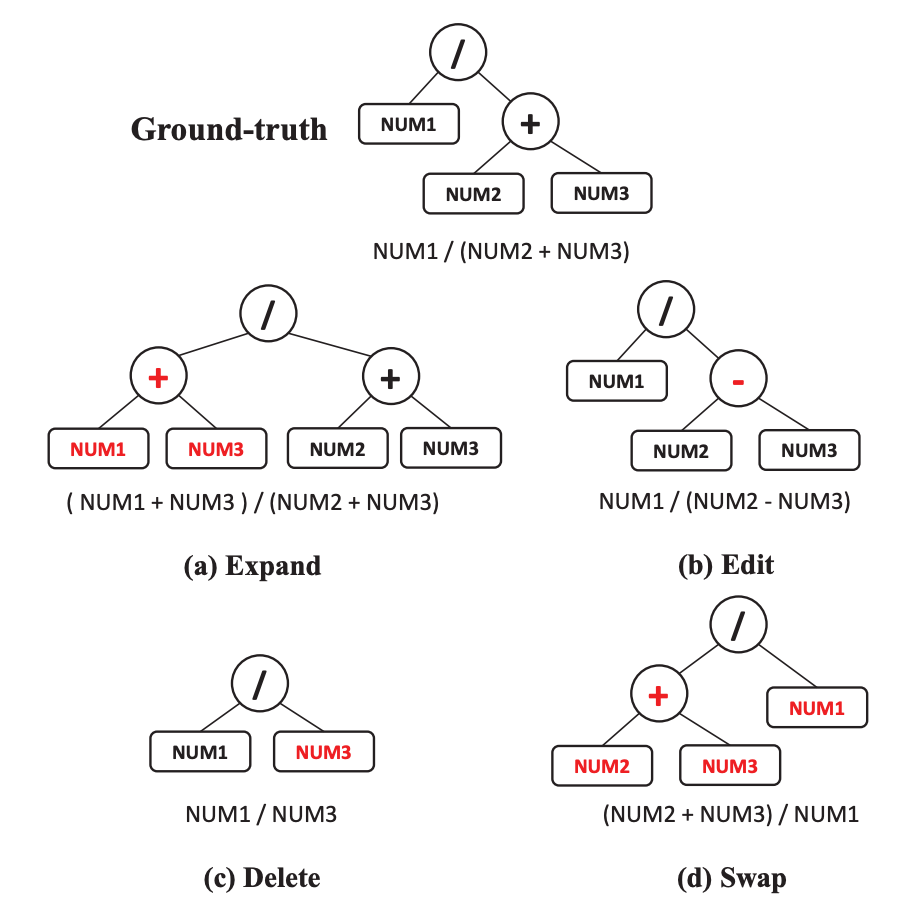
基于树的干扰
训练过程包括多任务训练和表达式在线更新。首先为生成任务对预训练的BART进行微调。之后,使用经过微调的BART和基于树的干扰来生成表达式,作为排序器的训练样本。然后,进行生成和排序的联合训练。
这个过程是以迭代的方式进行的,两个模块(即生成器和排序器)继续相互促进。同时,用于排序器的训练实例在每轮迭代后会被更新。

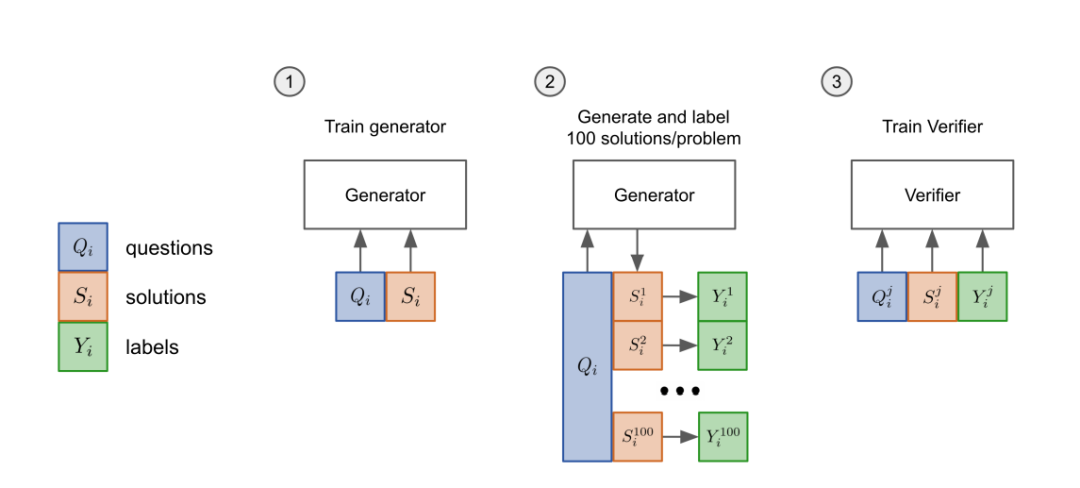
先把模型的「生成器」在训练集上进行2个epoch的微调。 从生成器中为每个训练问题抽取100个解答,并将每个解答标记为正确或不正确。 在数据集上,验证器再训练单个epoch。
参考资料:

点个在看 paper不断!
评论