
SLAM就业问题汇总复习
相似变换仿射变换射影变换的区别
相似变换7自由度是因为6+1,多了一个尺度。
仿射变换12自由度是因为一个平移变换(t)和一个非均匀变换(A)的复合,A是可逆矩阵,并不要求是正交矩阵。9+3=12。不变的是平行线比例和长度,体积比。
射影变换15自由度是因为16-1=15,扣除一个全局尺度(整个矩阵除以右下角为1)。不变的是重合关系。
单应矩阵和基础矩阵的区别

视差和深度的关系
z=fb/d,f是焦距,b是基线(baseline,两相机光圈中心的距离),d是视差(disparity)。视差最小为一个深度,因此双目深度存在理论上的最大值,由fb确定。
二值图,最大联通区域
两次扫描法:
这块复制维基百科的内容:连通分量标记 (内网打不开,看我下面的)
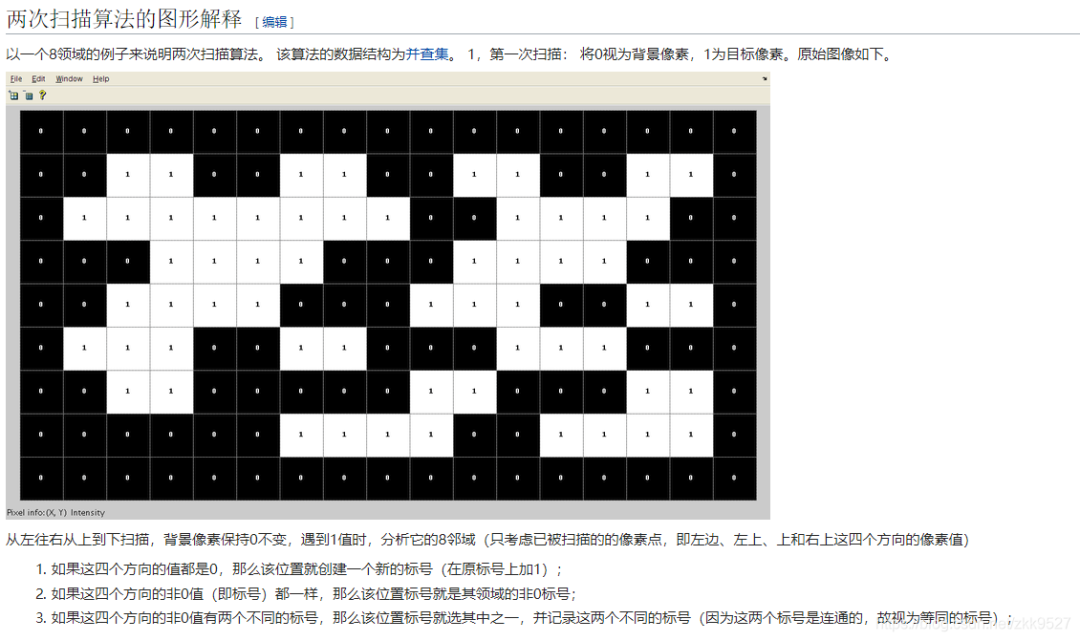

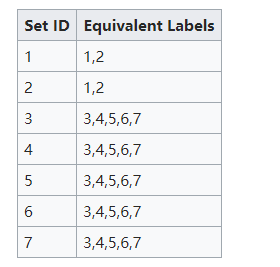
最后连起来。
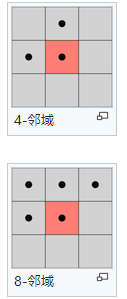
注意这个4领域和8领域,只是上面的点,不要下面的。
区域生长法:

梯度下降法,牛顿法和高斯牛顿法优劣

边缘检测算子
1.sobel 产生的边缘有强弱,抗噪性好。用 f '(x) = f(x + 1) - f(x - 1) 近似计算一阶差分。
2.laplace 对边缘敏感,可能有些是噪声的边缘,也被算进来了。用二阶差分计算边缘,f '(x) = f(x - 1) - 2 f(x)+ f(x + 1)
3.canny 产生的边缘很细,可能就一个像素那么细,没有强弱之分。
canny方式:
1.高斯滤波器平滑图像。
2.一阶差分偏导计算梯度值和方向。
3.对梯度值不是极大值的地方进行抑制。
4.用双阈值连接图上的联通点。
Harris:

R=det(M) - k(trace(M))^2其中,det(M) = λ1λ2,trace(M) = λ1+λ2
当|R|很小时,即λ1和λ2很小时,该区域是平面。
当 R < 0时,即λ1远远大于λ2或者λ2远远大于λ1时,该区域是边缘。
当 R很大时,即λ1和λ2都很大且近似相等,该区域是角点。
BA算法的流程
构造代价函数(比如重投影误差)
令雅克比矩阵为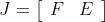
雅克比子矩阵为
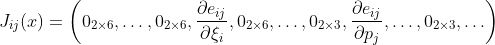
之后构建H矩阵,可以利用高斯牛顿法求解。使用舒尔补操作加速求解。
如果限制窗口大小,用舒尔补操作marg掉前面不再需要的变量,同时把其中的联系逐步递推下来。
SVO中深度滤波器原理
基本SLAM14讲中已经提过。
极线搜索与块匹配。之后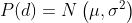 ,新到的数据是
,新到的数据是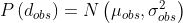 ,以如下方式融合:
,以如下方式融合:
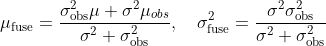
其中,μ为块匹配找到像素的深度,σ为扰动一个像素的深度改变,当成不确定度。
当不确定度每次改变小于一个阈值的时候,就认为是收敛了,加入地图。
某个SLAM框架工作原理,优缺点,改进
1.MonoSLAM:以扩展卡尔曼滤波器为后端,追踪前端的稀疏特征点,里程碑式的工作
2.PTAM:第一个使用非线性优化而不是滤波器作为后端的方案。
3.ORB-SLAM:现代SLAM系统中做的最完善易用的系统之一,在特征点SLAM中达到顶峰。
三个线程,一个实时跟踪特征点,一个局部BA,一个全局Pose Graph优化与回环检测。缺点是对硬件要求比较高。

4.LSD-SLAM:将直接法应用到了半稠密单目SLAM中。(所以拥有直接法的优缺点,对特征缺失的地方不敏感,但是对相机内参和曝光比较敏感)
5.SVO:没有后端优化和回环检测部分。优势是速度极快,针对的是应用平台为无人机的俯视相机。
6.RTAB-MAP:集成度高,方便使用但是不适合研究。
Ransac框架的实现

简单实现cv::Mat()
这个题目网上好几个记录帖都说会问(虽然可能都是抄来抄去同一个),但我实在不晓得具体需求是什么,要实现到什么程度。
暂且跳过,现场发挥吧。或者以后补上。知道的帮忙留言,告诉我这个题目啥意思,到底是想怎么个实现。
卡尔曼滤波、粒子滤波、贝叶斯滤波
卡尔曼滤波

-
粒子滤波
这块放两个大佬的文章:
怎样从实际场景上理解粒子滤波(Particle Filter)?- 青青子衿的回答 - 知乎
https://www.zhihu.com/question/25371476/answer/31552082
-
贝叶斯滤波
它做的工作就是根据不断接收到的新信息和我提供的一些已经知道的统计值,来不断更新概率。
【易懂教程】我是如何十分钟理解与推导贝叶斯滤波(Bayes Filter)算法?- Ai酱的文章 - 知乎
https://zhuanlan.zhihu.com/p/75880143
SIFT、SURF特征点
SIFT特征检测的步骤:
检测尺度空间的极值点:搜索所有尺度上的图像位置,通过高斯微分函数来识别潜在的对于尺度和旋转不变的候选关键点。
精确定位特征点(Keypoint):在每个候选的位置上,通过一个拟合精细的模型来确定位置和尺度,同时关键点的选择依据于它们的稳定程度。
设定特征点的方向参数:基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。
所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。
生成特征点的描述子(128维向量):在每个关键点周围的邻域内,在选定的尺度上测量图像局部的梯度。梯度被变换成一种表示。
这块内容属实抽象,看了也他娘的记不住。更别说叫我去推公式,那是万万不可能的,招聘在即,这种花时间推了最后也只能记个大概的我绝对不干,浪费宝贵时间。这里讲的比较好:
1.高斯金字塔则是由图像经过逐层下采样(步长为2的采样)而成,而每一层(称之为octave)中则含有多张由不同高斯函数卷积得到。
接着同一层(octave)的相邻两个图像进行差分,即可得到高斯差分金字塔。(DOG)
之后,在高斯差分金字塔中,中间的检测点和它同尺度的8个相邻点和上下相邻尺度对应的9×2个点共26个点比较,以确保在尺度空间和二维图像空间都检测到极值点。
一个点如果在DOG尺度空间本层以及上下两层的26个领域中是最大或最小值时,就认为该点是图像在该尺度下的一个特征点。
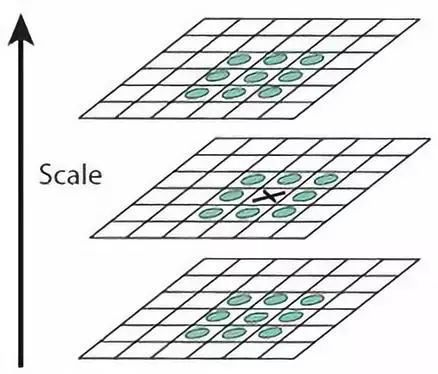
2.对尺度空间DoG函数进行曲线拟合,计算其极值点,从而实现关键点的精确定位。
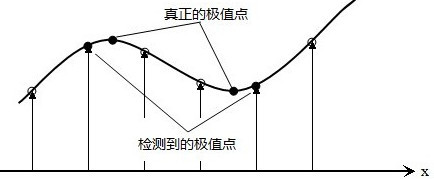
拟合函数一般采用二次函数:对其求导取0,可得偏移量。一般使(x,y,σ)任一维小于0.5即可停止选择。
而对于所确定的点还需要进行筛选,如通过设定阈值去除对比度低的点,或者hessian矩阵的迹与行列式的比值判断关键点是否在边缘,剔除这些不稳定的边缘响应点。
3.完成关键点的梯度计算后,使用直方图统计邻域内像素的梯度和方向。
梯度直方图将0~360度的方向范围分为36个柱(bins),其中每柱10度。
随着距中心点越远的领域其对直方图的贡献也响应减小(为简化,图中只画了45度一柱,8个方向的直方图)。
而在主方向的计算中,还存在主方向的校正,通过一个旋转矩阵将坐标轴旋转为特征点的主方向。
至此,图像的关键点已经检测完毕,每个关键点有三个信息:位置、尺度、方向,这些关键点即是该图像的SIFT特征点。
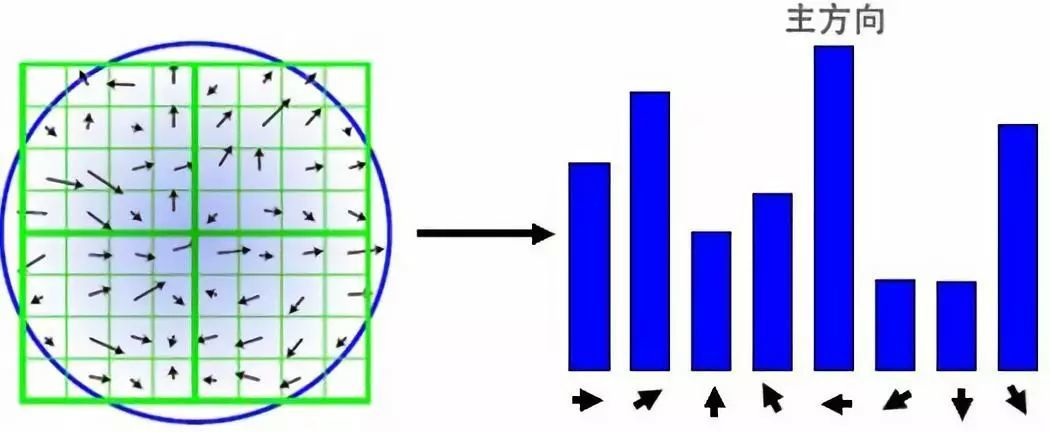
4.计算描述子:
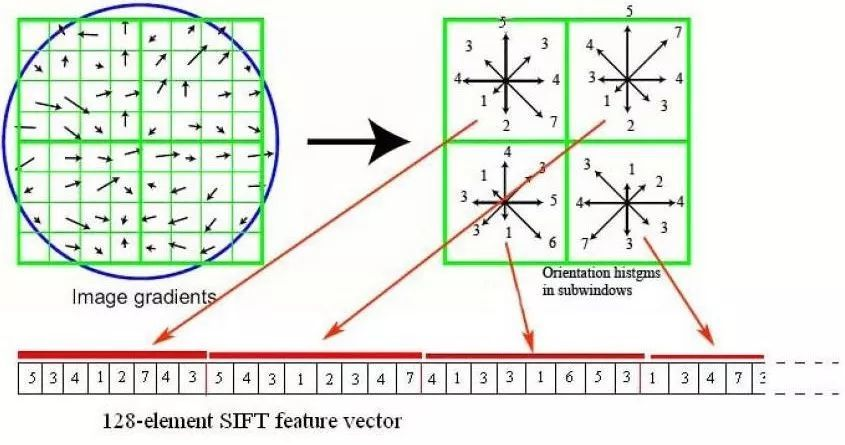
左图的中央为当前关键点的位置,每个小格代表为关键点邻域所在尺度空间的一个像素,求取每个像素的梯度幅值与梯度方向,箭头方向代表该像素的梯度方向,长度代表梯度幅值。
然后利用高斯窗口对其进行加权运算。最后在每个2×2的小块上绘制8个方向的梯度直方图,计算每个梯度方向的累加值,即可形成一个种子点,如右图所示。
每个特征点由4个种子点组成,每个种子点有8个方向的向量信息,那么向量的维数为4×8=32维。将其按照顺时针方向进行展开,即可得到一个1×32的向量。
对每个关键点使用16×16的窗口,4×4共16个种子点来描述,这样一个关键点就可以产生128维的SIFT特征向量。
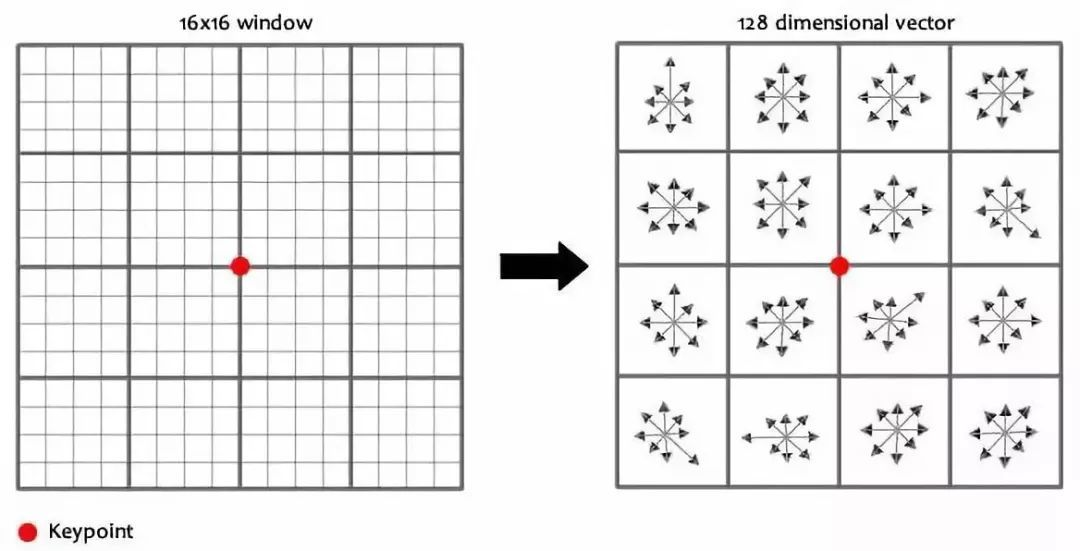
SIFT特征点(Scale Invariant Feature Transform,尺度不变特征变换):图像的局部特征,对旋转、尺度缩放、亮度变化保持不变,对视角变化、仿射变换、噪声也保持一定程度的稳定性。
缺点是实时性不高,并且对于边缘光滑目标的特征点提取能力较弱。
SURF特征点的步骤:
1. 构建Hessian(海塞矩阵),生成所有的兴趣点,用于特征的提取;
2. 构建尺度空间
3. 特征点定位
4. 特征点主方向分配
5. 生成特征点描述子
6. 特征点匹配
跟SIFT的区别在于:
1.构建Hessian矩阵形成兴趣点,用盒式滤波器代替高斯滤波器。(上面是高斯滤波器 下面是盒式滤波器
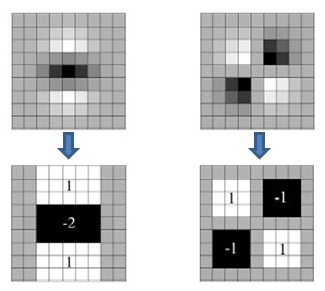
2.在构建尺度空间中,SIFT算法下一组图像的长宽均是上一组的一半,同一组不同层图像之间尺寸一样,但是所使用的尺度空间因子(高斯模糊系数σ)逐渐增大;
而在SURF算法中,不同组间图像的尺寸都是一致的,不同的是不同组间使用的盒式滤波器的模板尺寸逐渐增大,同一组不同层图像使用相同尺寸的滤波器,但是滤波器的尺度空间因子逐渐增大。
3.特征点定位过程和SIFT一样,但是特征点主方向计算方法不一样:
SIFT算法特征点的主方向是采用在特征点邻域内统计其梯度直方图,横轴是梯度方向的角度,纵轴是梯度方向对应梯度幅值的累加,取直方图bin最大的以及超过最大80%的那些方向作为特征点的主方向。
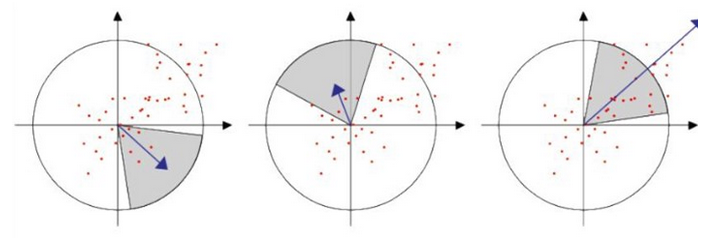
而在SURF算法中,采用的是统计特征点圆形邻域内的Harr小波特征,即在特征点的圆形邻域内,统计60度扇形内所有点的水平、垂直Harr小波特征总和。
然后扇形以0.2弧度大小的间隔进行旋转并再次统计该区域内Harr小波特征值之后,最后将值最大的那个扇形的方向作为该特征点的主方向。该过程示意图如下:
4.生成特征描述不一样:
在SIFT算法中,为了保证特征矢量的旋转不变性,先以特征点为中心,在附近邻域内将坐标轴旋转θ(特征点的主方向)角度。
然后提取特征点周围4×4个区域块,统计每小块内8个梯度方向,这样一个关键点就可以产生128维的SIFT特征向量。
SURF算法中,也是提取特征点周围4×4个矩形区域块,但是所取的矩形区域方向是沿着特征点的主方向,而不是像SIFT算法一样,经过旋转θ角度。
每个子区域统计25个像素点水平方向和垂直方向的Haar小波特征,这里的水平和垂直方向都是相对主方向而言的。
该Harr小波特征为水平方向值之和、垂直方向值之和、水平方向值绝对值之和以及垂直方向绝对值之和4个方向。该过程示意图如下:
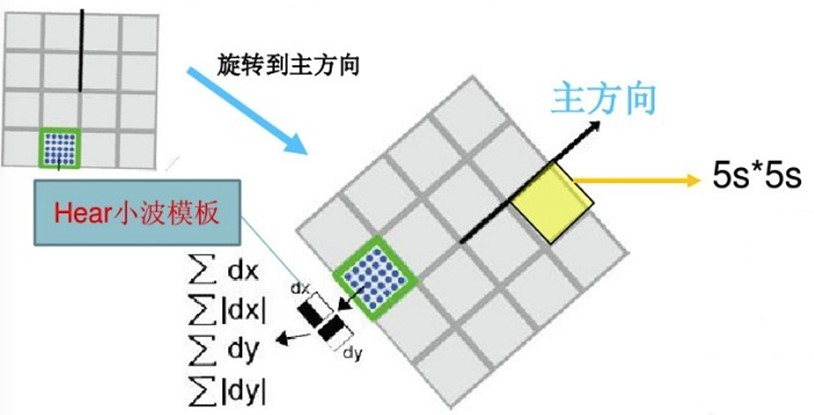
把这4个值作为每个子块区域的特征向量,所以一共有4×4×4=64维向量作为SURF特征的描述子,比SIFT特征的描述子减少了一半。
4*4,其中每个块中25个点,用这25个点统计四个值)
详情参见这里。优势是速度比SIFT提高了,对于旋转模糊鲁棒性也比SIFT提高了。
对于速度来说,ORB最快,SURF次之,SIFT最慢。
对于尺度变换的鲁棒性来说:SURF>SIFT>ORB(没有)对于旋转模糊鲁棒性来说:SURF>ORB~SIFT
如何求解Ax=b?
回顾矩阵与数值分析中的内容,可以分解A:
1.Gauss消元法:传统方式。
2.LU分解,本质上也是Gauss消元,令A=LU,L对角线为1,上半部分为0,其余记录gauss消元的化简过程,U记录原矩阵的变化。
3.Crout分解,U对角线1,U上三角,L下三角。
4.LDU分解,L单位下三角(对角为1),U单位上三角,D对角矩阵。
5.cholesky分解:A=LL^T,要求A为对称正定矩阵。(顺序主子式都大于0)
Vector4d x2 = A.llt().solve(B);也可以LDL^T分解,L为下三角矩阵,D为对角元素均为正数的对角矩阵。
Vector4d x3 = A.ldlt().solve(B);6.QR分解,A=QR,用正交矩阵代替Gauss消元的下三角矩阵。步骤是求Householder矩阵。
A分块为 A=(α1,α2,α3),取w1=α1-||α2||*e1
Q=H(w1)=
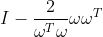
把Q左乘A,会得到第一行是111,下面右下角一个小块,再对这个小块重复操作。
直到把A变成上三角,然后把中途的Q一路左乘,得到一个QT是正交矩阵。
eigen中:
Vector4d x1 = A.colPivHouseholderQr().solve(B);7.Schur分解,A=URU^H,U为酉阵,R为上三角矩阵。
8.Jordan标准型。A=TJT^(-1),用Jordan链求,代数重复度,几何重复度。
9.奇异值分解,不再提。
JacobiSVD<MatrixXd> svd(J, ComputeThinU | ComputeThinV);U = svd.matrixU();V = svd.matrixV();A = svd.singularValues();
如何对匹配好的点做进一步的处理,更好保证匹配效果:
1.确定匹配最大距离,汉明距离小于最小距离的两倍
2.使用KNN-matching算法,令K=2。则每个match得到两个最接近的descriptor,然后计算最接近距离和次接近距离之间的比值,当比值大于既定值时,才作为最终match。
3.RANSAC(使用RANSAC找到最佳单应性矩阵。由于这个函数使用的特征点同时包含正确和错误匹配点,因此计算的单应性矩阵依赖于二次投影的准确性)
描述PNP
Perspective-n-Points, PnP(P3P)提供了一种解决方案,它是一种由3D-2D的位姿求解方式,即需要已知匹配的3D点和图像2D点。
目前遇到的场景主要有两个:
其一是求解相机相对于某2维图像/3维物体的位姿;
其二就是SLAM算法中估计相机位姿时通常需要PnP给出相机初始位姿。
在场景1中,我们通常输入的是物体在世界坐标系下的3D点以及这些3D点在图像上投影的2D点,因此求得的是相机坐标系相对于世界坐标系(Twc)的位姿
在场景2中,通常输入的是上一帧中的3D点(在上一帧的相机坐标系下表示的点)和这些3D点在当前帧中的投影得到的2D点,所以它求得的是当前帧相对于上一帧的位姿变换
FLANN算法

对这些特征点描述子集中建立索引。
K-dimensional Tree(Kd树)是一种常用的建立特征向量索引的方法。建立Kd树时,要不断地选取切分维度(当前子集内的所有点之间方差最大的维度),然后确定切分位置(按照切分维度排序选择中位数)。
这方面已经有比较成熟的代码库可以使用,例如FLANN。FLANN既可以单独使用,同时也被集成到了OpenCV、PCL等代码库中。
根据特征向量建立好Kd树后,查找Kd树中的最近邻居(K Nearest Neighbor)便可以得到目标图中匹配的特征点了。
EPNP
求解PnP问题目前主要有直接线性变换(DLT),P3P,EPnP,UPnP以及非线性优化方法。
DLT
直接构建一个12个未知数的[R|t]增广矩阵(先不考虑旋转矩阵的自由度只有3),取六个点对,去求解12个未知数(每一个3D点到归一化平面的映射给出两个约束),最后将[R|t]左侧3*3矩阵块进行QR分解,用一个旋转矩阵去近似(将3*3矩阵空间投影到SE(3)流形上)。
P3P
P3P方法是通过3对3D/2D匹配点,求解出四种可能的姿态,在OpenCV calib3d模块中有实现。
EPnP
需要4对不共面的(对于共面的情况只需要3对)3D-2D匹配点,是目前最有效的PnP求解方法。
EPnP的原理有些独特,参考这里:
https://zhuanlan.zhihu.com/p/46695068

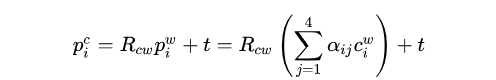
之后把t也写到其中,变成:
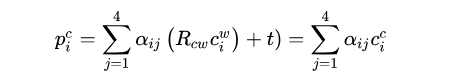

g2o流程
1.自己定义顶点类、边类或者用已经有的。
class CurveFittingVertex: public g2o::BaseVertex<3, Eigen::Vector3d>{public:EIGEN_MAKE_ALIGNED_OPERATOR_NEWvirtual void setToOriginImpl() // 重置{_estimate << 0,0,0;}virtual void oplusImpl( const double* update ) // 更新{_estimate += Eigen::Vector3d(update);}// 存盘和读盘:留空virtual bool read( istream& in ) {}virtual bool write( ostream& out ) const {}};
2.定义边。
class CurveFittingEdge :public g2o::BaseUnaryEdge<1,double,CurveFittingVertex>{public:EIGEN_MAKE_ALIGNED_OPERATOR_NEWCurveFittingEdge( double x ): BaseUnaryEdge(), _x(x) {}// 计算曲线模型误差void computeError(){const CurveFittingVertex* v = static_cast<const CurveFittingVertex*> (_vertices[0]);const Eigen::Vector3d abc = v->estimate();_error(0,0) = _measurement - std::exp( abc(0,0)*_x*_x + abc(1,0)*_x + abc(2,0) ) ;}virtual bool read( istream& in ) {}virtual bool write( ostream& out ) const {}public:double _x; // x 值, y 值为 _measurement};
之后很重要的一点,还有linearizeOplus函数,这个函数是求雅克比矩阵,也可以没有这个函数。
雅克比矩阵也就是误差函数对顶点的求导值。_jacobianOplusXi(i,j)=;
3.定义图模型
typedef g2o::BlockSolver< g2o::BlockSolverTraits<3,1> > Block; // 每个误差项优化变量维度为3,误差值维度为1Block::LinearSolverType* linearSolver = new g2o::LinearSolverDense<Block::PoseMatrixType>(); // 线性方程求解器Block* solver_ptr = new Block( linearSolver ); // 矩阵块求解器// 梯度下降方法,从GN, LM, DogLeg 中选g2o::OptimizationAlgorithmLevenberg* solver = new g2o::OptimizationAlgorithmLevenberg( solver_ptr );// g2o::OptimizationAlgorithmGaussNewton* solver = new g2o::OptimizationAlgorithmGaussNewton( solver_ptr );// g2o::OptimizationAlgorithmDogleg* solver = new g2o::OptimizationAlgorithmDogleg( solver_ptr );g2o::SparseOptimizer optimizer; // 图模型optimizer.setAlgorithm( solver ); // 设置求解器optimizer.setVerbose( true ); // 打开调试输出
即:
typedef一个矩阵块求解器 Block类型。
定义线性方程求解器。
Block 一个指针,定义矩阵块求解器的实例(形参传入线性方程求解器)。
定义一个图模型优化器optimizer。
定义梯度下降法solver,将矩阵块求解器的实例传入形参。
图模型optimizer.setAlgorithm(梯度下降法solver)
-
打开调试输出。
4.图模型添加顶点。
CurveFittingVertex* v = new CurveFittingVertex();v->setEstimate( Eigen::Vector3d(0,0,0) );v->setId(0);optimizer.addVertex( v );
5.添加边
for ( int i=0; i<N; i++ ){CurveFittingEdge* edge = new CurveFittingEdge( x_data[i] );edge->setId(i);edge->setVertex( 0, v ); // 设置连接的顶点edge->setMeasurement( y_data[i] ); // 观测数值edge->setInformation( Eigen::Matrix<double,1,1>::Identity()*1/(w_sigma*w_sigma) ); // 信息矩阵:协方差矩阵之逆optimizer.addEdge( edge );}
6.图模型求解
optimizer.initializeOptimization();optimizer.optimize(100);
Ceres流程

代价函数:
struct CURVE_FITTING_COST{CURVE_FITTING_COST(double x,double y):_x(x),_y(y){}template <typename T>bool operator()(const T* const abc,T* residual)const //待估计参数,误差项{residual[0]=_y-ceres::exp(abc[0]*_x*_x+abc[1]*_x+abc[2]);return true;}const double _x,_y;};
2.构建优化问题:
ceres::Problem problem;for(int i=0;i<1000;i++){//自动求导法,输出维度1,输入维度3,problem.AddResidualBlock(new ceres::AutoDiffCostFunction<CURVE_FITTING_COST,1,3>(new CURVE_FITTING_COST(x_data[i],y_data[i])),nullptr, //核函数abc //待估计参数,这个在main函数中要定义,然后这样传入进来);}
3.配置求解问题这块就是套路了:
Solver::Options options;options.linear_solver_type = ceres::DENSE_QR; //配置增量方程的解法options.minimizer_progress_to_stdout = true;//输出到coutSolver::Summary summary;//优化信息Solve(options, &problem, &summary);//求解!!!
创建一个Option,配置一下求解器的配置,创建一个Summary。最后调用Solve方法,求解。
LM算法和dogleg算法
LM:
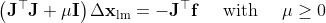
求解的△xm为:
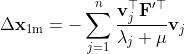
这个求解结果可以证明,但是我这里先不放。
其中,阻尼因子μ的作用是,它大于0保持正定,μ大就接近最速下降法,μ小就接近高斯牛顿法
μ的初值选取JTJ对角线元素的最大值乘以一个τ(一般取10e-8到1):
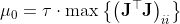
根据上面求解出的△xlm,之后如果迭代△x导致Fx增大,那么就要增大分母里的μ,让△x减小一些。
反之让△x增大一些。(这个是定性分析)
真正的定量分析,是通过比例因子ρ来确定:
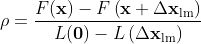
分子代表实际下降的值,分母代表雅克比的估计值。
分母应该始终大于0,如果分子小于0,导致ρ小于零,说明该增大μ了。
如果ρ是大于0的:
如果比较大,说明实际下降的大于估计下降的,那么步长应该大一些,所以需要减小μ。
如果比较小,说明实际下降的小于估计下降的,那么步长应该放小一些,所以需要增大μ。
接下来就涉及到步长的更新了:
这是马尔夸特的更新策略:
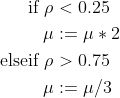
但是g2o,ceres里面用的不是这个更新策略,而是叫Nielsen策略:(因为原来的策略会导致阻尼因子上下震荡,浪费了一些计算次数)
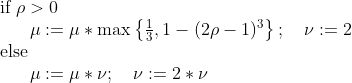
意思是如果ρ大于0,就按这个策略去更新。如果小于0了,就该增大μ,用一个v来控制,让步长快点减小到一个合适的值。
Dogleg:
GaussNewton和最快下降法混合方法是Dog-Leg法,代替阻尼项,用trust region:
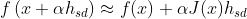
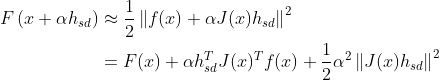
对α求导令其为0,得:
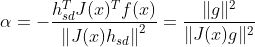
到此为止,如果我们采用高斯牛顿法,那么表示为:
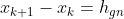
如果采取最速下降法,那么表示为:
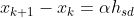
记住上面的这两个符号。

狗腿算法的主要内容就可以理解为:根据最速下降法和高斯牛顿法的两种迭代步长进行均衡,自动选择比较好的步长!
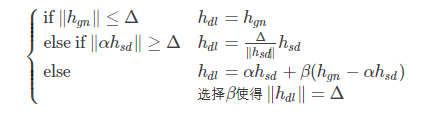

ρ如果偏小,说明实际更新的小于预测的,说明步子迈大了,应该减小步长。

ORB-SLAM初始化流程
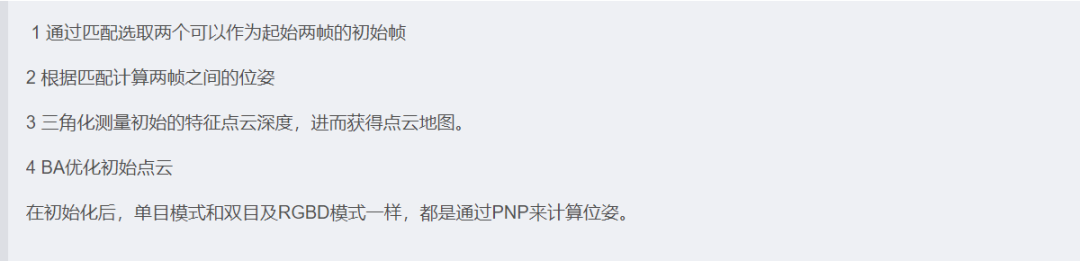


也就是根据公式算分值SH和SF,然后根据下述的公式,决定选哪个:
当RH>0.45的时候选择单应矩阵。
注意,那SH和SF怎么算呢?

这是吴博的PPT内容。
TF和TH那里标误了,应该反过来,TF=5.99,TH=3.84。这个代表阈值,意思是本身根据F和H矩阵的性质,2范数内部应该是0的。
至于这两个数值,是对于x,一个误差的错误所影响的结果。
最后选好模型后,分解得到对应的位姿。(不过F是要先变成本质矩阵E,再分解的)
三角化测量初始的特征点云深度:
用线性三角形法中的齐次方法。

执行一个全局BA,以优化初始重构得到的点云地图
ORB-SLAM的其他注意内容
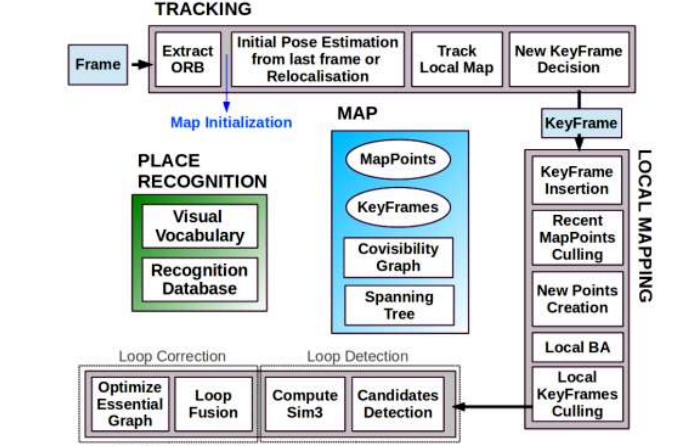
三个线程,一个Tracking,一个Local mapping,一个loop closing。
Tracking线程:初始化->相机位姿跟踪(可以选择要不要插入关键帧即局部地图要不要工作)->局部地图跟踪 (EPNP)->判断是否生成关键帧->生成关键帧
LocalMapping线程:检查队列 -> 处理新关键帧(更新MapPoints与KeyFrame的关联)->剔除MapPoints(剔除地图中新添加的但质量不好的MapPoints。
比如观测到该点的关键帧太少)->生成MapPoint( 共视程度比较高的关键帧通过三角化恢复出一些MapPoints)->Mappoint融合(检查当前关键帧与相邻帧(两级相邻)重复的MapPoints)->Local BA(和当前关键帧相连的关键帧及MapPoints做局部BA优化)
Loop closing线程:这个三言两语说不清了,放个图吧:
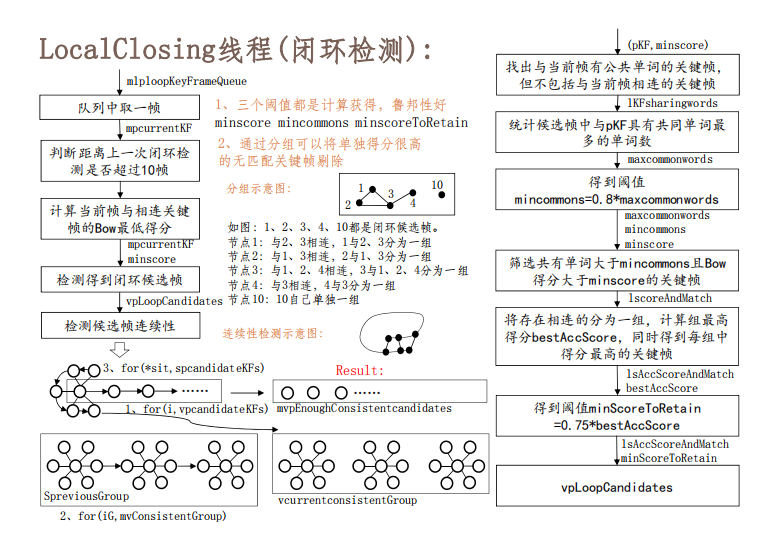
这块学习的时候可以参考东北大学吴博和360人工智能研究院的谢晓佳老师一起注释的ORBSLAM的内容:
https://gitee.com/paopaoslam/ORB-SLAM2
来源:古月居
声明:部分内容来源于网络,仅供读者学习、交流之目的。文章版权归原作者所有。如有不妥,请联系删除。