
超越CLIP的多模态模型,只需不到1%的训练数据!南加大最新研究来了
羿阁 发自 凹非寺
来源 | 量子位 QbitAI
火爆全网的AI绘画你玩了吗?
女娲无限版、DALL·E2、Imagen……这些通过文字生成图像的AI绘画工具,背后的原理都是一个叫“CLIP”的模型,它是AI如何“理解”人类语义这一问题的关键。

CLIP(Contrastive Language–Image Pre-training),是一种基于对比的图片-文本学习的跨模态预训练模型,由OpenAI于去年1月发布。
它好用是好用,但一个大问题是数据需求太大:4亿个图像文本对、256个GPU,这对许多公司和个人都很不友好。
对此,南加州大学的最新研究发现了一种基于本体的课程学习(Curriculum Learning)算法,只需不到1%的训练数据就能达到CLIP同款效果,甚至在图像检索方面表现更好。
新方法名为TOnICS(Training with Ontology-Informed Contrastive Sampling),相关论文已上传到arXiv。

原理介绍
在介绍新方法之前,首先需要回顾一下CLIP。
CLIP的模型结构其实非常简单:包括两个部分,即文本编码器和图像编码器。
两者分别编码后,将文本和视觉嵌入映射到相同空间中,使用对比学习的思想,将匹配的图片-文本Embedding的距离拉近,将不匹配的Embedding拉远。
在此基础上,TOnICS没有选择从头训练图像和文本编码器,而是把单模态预训练模型BERT用于文本编码,微软的VinVL用于图像编码,并使用InfoNCE损失函数将它们彼此对齐。

这是一种基于本体的课程学习算法,从简单的样本开始训练,方法是随机抽样小批次,并通过在图像和文本输入中加入相似的小批量数据,逐步加大对比任务的难度。
举个例子,在随机抽样生成的小批量数据中,如果想找到“一条叼着飞盘在草地上奔跑的狗”,只需要先找画面中有狗的图片即可,因为随机生成的图像中包含狗的概率非常小。
也就意味着,随机小批量抽样将对比任务简化为了对象匹配。
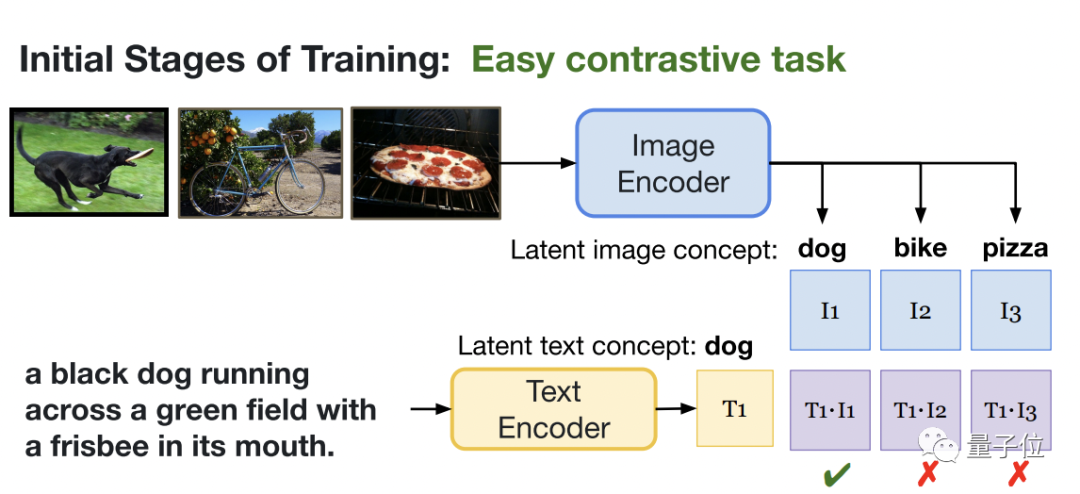
但当对小批样进行采样时,会抓取到很多画面中有狗的相似图片,因此仅靠识别图片中是否有狗已经不能解决问题了,该模型必须共享上下文级信息的语言和视觉表示,从而产生更细粒度的对齐。

此外,不同于CLIP从互联网收集构建了4亿个图像-文本对的数据集,BERT-VinVL模型只需不到1%的训练量,但效果并没有打折扣。

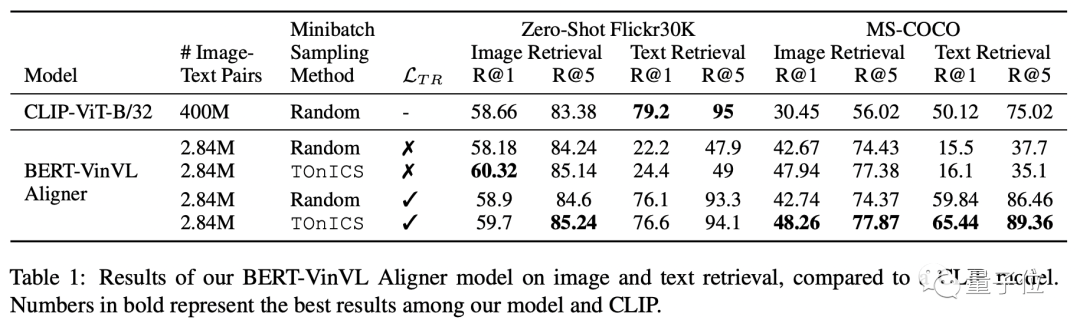
研究人员在MS-COCO和Conceptual Captions上训练BERT-VinVL模型,并将该模型与下游检索任务上的CLIP进行比较。
实验结果发现,BERT-VinVL模型同样能达到零样本学习效果,甚至在图像检索上表现更好( R@1 提高了 1.5%)。
研究团队
该篇论文来自南加州大学的研究团队,作者分别是Tejas Srinivasan、Xiang Ren和Jesse Thomason。
第一作者Tejas Srinivasan,是南加州大学GLAMOR实验室的一年级博士生,跟随助理教授Jesse Thomason进行多模态机器学习和语言基础领域的研究。

他曾在微软研究院实习,并在人工智能基金会短暂地担任过 NLP 研究科学家。
之前在卡内基梅隆大学语言技术学院完成了硕士学位,本科毕业于孟买印度理工学院机械工程专业,辅修计算机科学学位。
参考链接:
[1]https://tejas1995.github.io/
[2]https://twitter.com/tejubabyface_/status/1554152177035186178
[3]https://arxiv.org/abs/2207.14525
— 完 —
分享
收藏
点赞
在看
