
干货 | 深度学习检测小目标常用方法
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自|视觉算法

github地址:https://github.com/Captain1986/CaptainBlackboard
来源:opencv学堂 文字编辑:gloomyfish
引言
在深度学习目标检测中,特别是人脸检测中,小目标、小人脸的检测由于分辨率低,图片模糊,信息少,噪音多,所以一直是一个实际且常见的困难问题。不过在这几年的发展中,也涌现了一些提高小目标检测性能的解决手段,本文对这些手段做一个分析、整理和总结。
传统的图像金字塔和多尺度滑动窗口检测
最开始在深度学习方法流行之前,对于不同尺度的目标,大家普遍使用将原图build出不同分辨率的图像金字塔,再对每层金字塔用固定输入分辨率的分类器在该层滑动来检测目标,以求在金字塔底部检测出小目标;或者只用一个原图,在原图上,用不同分辨率的分类器来检测目标,以求在比较小的窗口分类器中检测到小目标。
在著名的人脸检测器MTCNN中,就使用了图像金字塔的方法来检测不同分辨率的人脸目标。
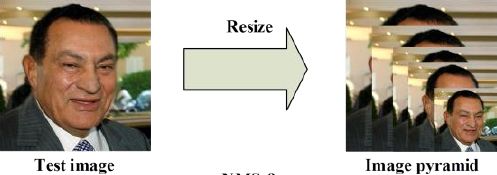
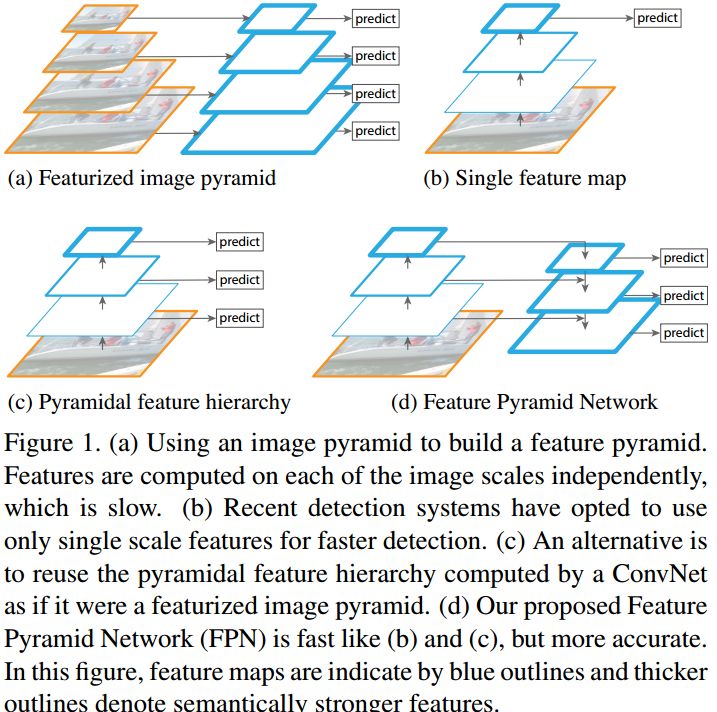
不过这种方式速度慢(虽然通常build图像金字塔可以使用卷积核分离加速或者直接简单粗暴地resize,但是还是需要做多次的特征提取呀),后面有人借鉴它的思想搞出了特征金字塔网络FPN,它在不同层取特征进行融合,只需要一次前向计算,不需要缩放图片,也在小目标检测中得到了应用,在本文后面会讲到。
简单粗暴又可靠的Data Augmentation
深度学习的效果在某种意义上是靠大量数据喂出来的,小目标检测的性能同样也可以通过增加训练集中小目标样本的种类和数量来提升。在《深度学习中不平衡样本的处理》一文中已经介绍了许多数据增强的方案,这些方案虽然主要是解决不同类别样本之间数量不均衡的问题的,但是有时候小目标检测之难其中也有数据集中小样本相对于大样本来说数量很少的因素,所以其中很多方案都可以用在小样本数据的增强上,这里不赘述。另外,在19年的论文Augmentation for small object detection中,也提出了两个简单粗暴的方法:
方法一
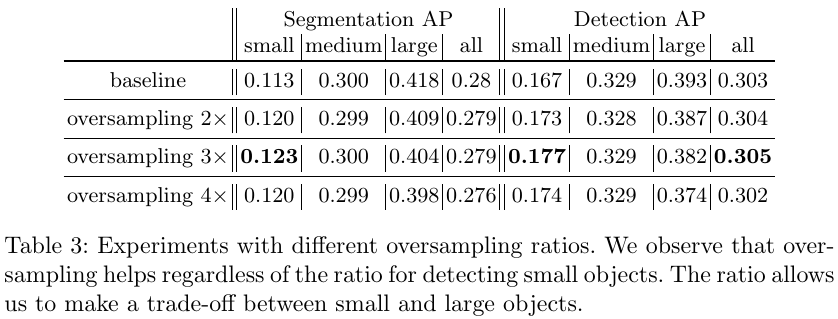
针对COCO数据集中包含小目标的图片数量少的问题,使用过采样OverSampling策略;
方法二
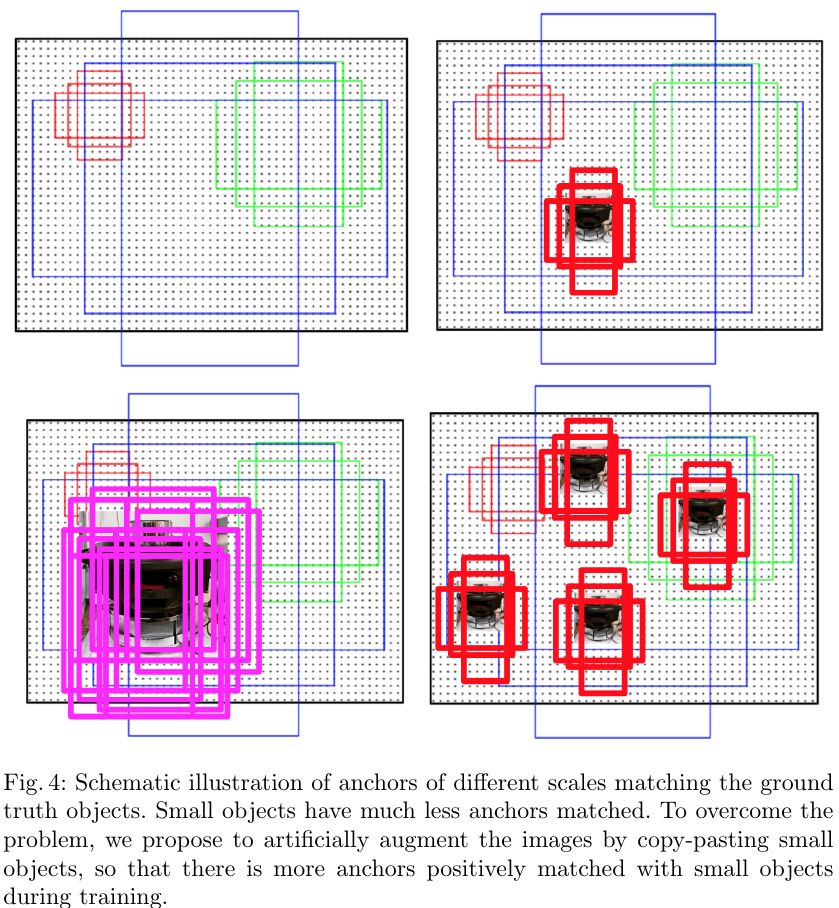
针对同一张图片里面包含小目标数量少的问题,在图片内用分割的Mask抠出小目标图片再使用复制粘贴的方法(当然,也加上了一些旋转和缩放,另外要注意不要遮挡到别的目标)。

在同一张图中有更多的小目标,在Anchor策略的方法中就会匹配出更多的正样本。
特征融合的FPN
不同阶段的特征图对应的感受野不同,它们表达的信息抽象程度也不一样。浅层的特征图感受野小,比较适合检测小目标(要检测大目标,则其只“看”到了大目标的一部分,有效信息不够);深层的特征图感受野大,适合检测大目标(要检测小目标,则其”看“到了太多的背景噪音,冗余噪音太多)。所以,有人就提出了将不同阶段的特征图,都融合起来,来提升目标检测的性能,这就是特征金字塔网络FPN。
在人脸领域,基本上性能好一点的方法都是用了FPN的思想,其中比较有代表性的有:
RetinaFace:Single-stage Dense Face Localisation in the Wild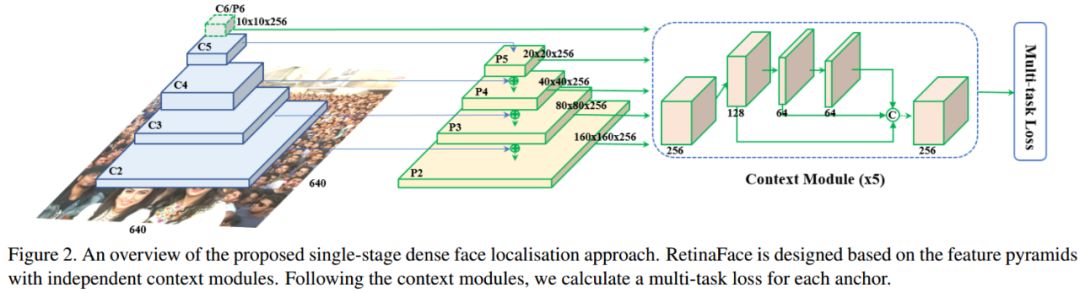
另外一个思路:
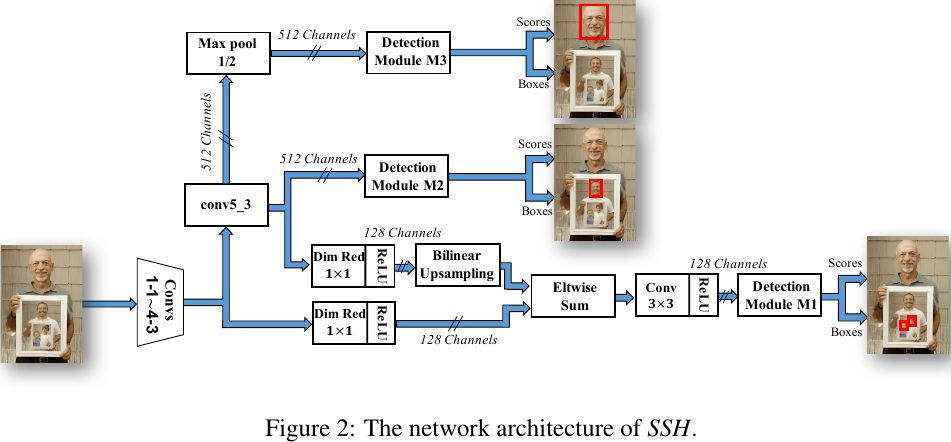
既然可以在不同分辨率特征图做融合来提升特征的丰富度和信息含量来检测不同大小的目标,那么自然也有人会进一步地猜想,如果只用高分辨率的特征图(浅层特征)去检测小脸;用中间分辨率的特征图(中层特征)去检测大脸;最后用地分辨率的特征图(深层特征)去检测小脸。比如人脸检测中的SSH。
合适的训练方法SNIP,SNIPER,SAN
机器学习里面有个重要的观点,模型预训练的分布要尽可能地接近测试输入的分布。所以,在大分辨率(比如常见的224 x 224)下训练出来的模型,不适合检测本身是小分辨率再经放大送入模型的图片。如果是小分辨率的图片做输入,应该在小分辨率的图片上训练模型;再不行,应该用大分辨率的图片训练的模型上用小分辨率的图片来微调fine-tune;最差的就是直接用大分辨率的图片来预测小分辨率的图(通过上采样放大)。但是这是在理想的情况下的(训练样本数量、丰富程度都一样的前提下,但实际上,很多数据集都是小样本严重缺乏的),所以放大输入图像+使用高分率图像预训练再在小图上微调,在实践中要优于专门针对小目标训练一个分类器。


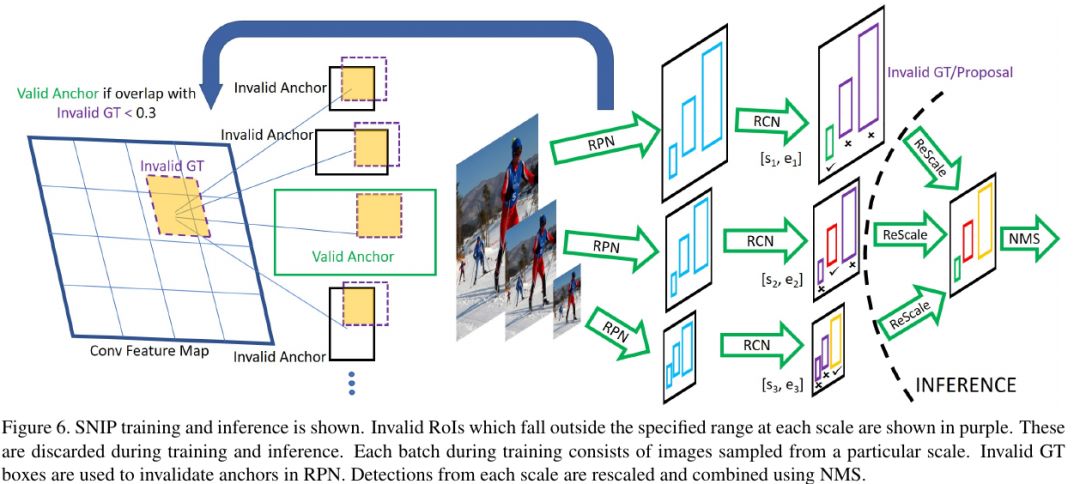
在下图中示意的是SNIP训练方法,训练时只训练合适尺寸的目标样本,只有真值的尺度和Anchor的尺度接近时来用来训练检测器,太小太大的都不要,预测时输入图像多尺度,总有一个尺寸的Anchor是合适的,选择那个最合适的尺度来预测。对R-FCN提出的改进主要有两个地方,一是多尺寸图像输入,针对不同大小的输入,在经过RPN网络时需要判断valid GT和invalid GT,以及valid anchor和invalid anchor,通过这一分类,使得得到的预选框更加的准确;二是在RCN阶段,根据预选框的大小,只选取在一定范围内的预选框,最后使用NMS来得到最终结果。
SNIPER是SNIP的实用升级版本,这里不做详细介绍了。
稠密Anchor采样和匹配策略S3FD,FaceBoxes
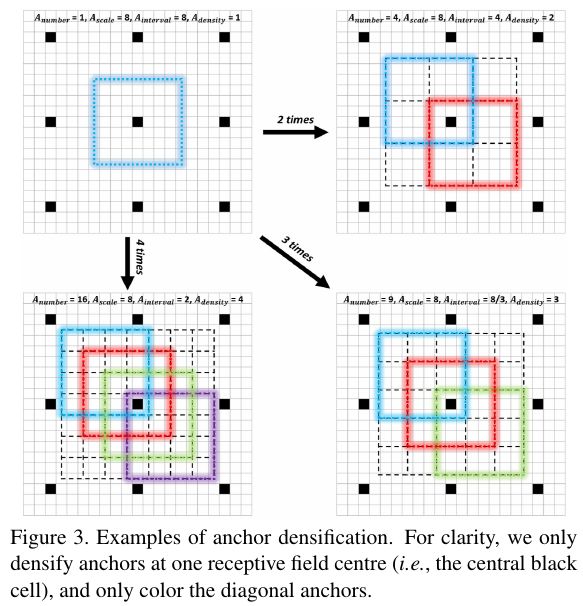
在前面Data Augmentation部分已经讲了,复制小目标到一张图的多个地方可以增加小目标匹配的Anchor框的个数,增加小目标的训练权重,减少网络对大目标的bias。同样,反过来想,如果在数据集已经确定的情况下,我们也可以增加负责小目标的Anchor的设置策略来让训练时对小目标的学习更加充分。例如人脸检测中的FaceBoxes其中一个Contribution就是Anchor densification strategy,Inception3的anchors有三个scales(32,64,128),而32 scales是稀疏的,所以需要密集化4倍,而64 scales则需要密集化2倍。在S3FD人脸检测方法中,则用了Equal-proportion interval principle来保证不同大小的Anchor在图中的密度大致相等,这样大脸和小脸匹配到的Anchor的数量也大致相等了。
另外,对小目标的Anchor使用比较宽松的匹配策略(比如IoU > 0.4)也是一个比较常用的手段。
先生成放大特征再检测的GAN
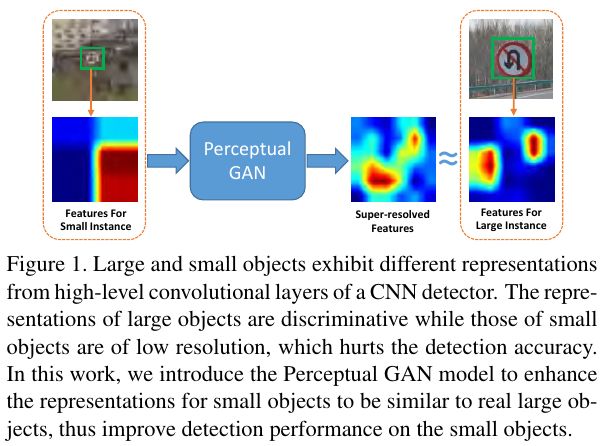
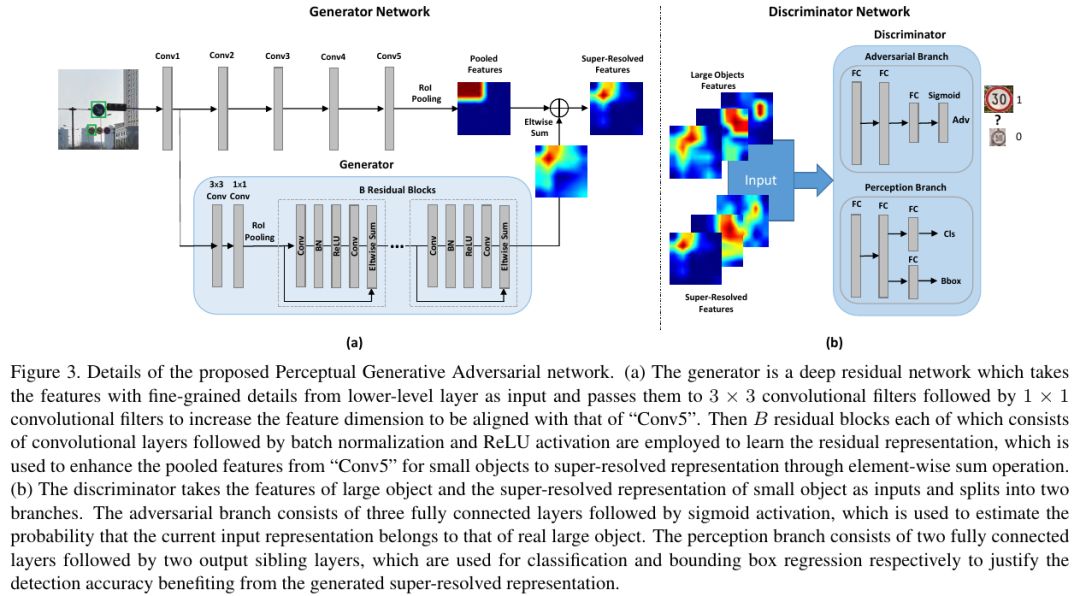
Perceptual GAN使用了GAN对小目标生成一个和大目标很相似的Super-resolved Feature(如下图所示),然后把这个Super-resolved Feature叠加在原来的小目标的特征图(如下下图所示)上,以此增强对小目标特征表达来提升小目标(在论文中是指交通灯)的检测性能。
利用Context信息的Relation Network和PyramidBox
小目标,特别是像人脸这样的目标,不会单独地出现在图片中(想想单独一个脸出现在图片中,而没有头、肩膀和身体也是很恐怖的)。像PyramidBox方法,加上一些头、肩膀这样的上下文Context信息,那么目标就相当于变大了一些,上下文信息加上检测也就更容易了。

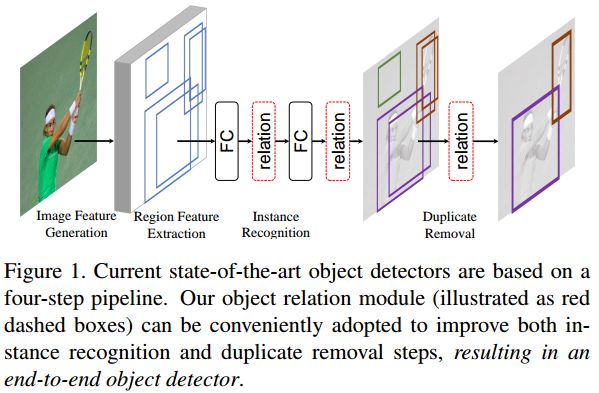
这里顺便再提一下通用目标检测中另外一种加入Context信息的思路,Relation Networks虽然主要是解决提升识别性能和过滤重复检测而不是专门针对小目标检测的,但是也和上面的PyramidBox思想很像的,都是利用上下文信息来提升检测性能,可以归类为Context一类。
总结
本文比较详细地总结了一些在通用目标检测和专门人脸检测领域常见的小目标检测的解决方案,后面有时间会再写一些专门在人脸领域的困难点(比如ROP的侧脸,RIP的360度人脸)及现在学术界的解决方案。
参考链接
Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
https://arxiv.org/abs/1604.02878
Augmentation for small object detection
https://arxiv.org/pdf/1902.07296.pdf
Feature Pyramid Networks for Object Detection
https://arxiv.org/abs/1612.03144
RetinaFace: Single-stage Dense Face Localisation in the Wild
https://arxiv.org/pdf/1905.00641.pdf
SSH: Single Stage Headless Face Detector
https://arxiv.org/pdf/1708.03979.pdf
An Analysis of Scale Invariance in Object Detection - SNIP
https://arxiv.org/abs/1711.08189
R-FCN: Object Detection via Region-based Fully Convolutional Networks
https://arxiv.org/abs/1605.06409
SNIPER: Efficient Multi-Scale Training
https://arxiv.org/pdf/1805.09300.pdf
SAN: Learning Relationship between Convolutional Features for Multi-Scale Object Detection
https://arxiv.org/pdf/1808.04974.pdf
ScratchDet: Training Single-Shot Object Detectors from Scratch
https://arxiv.org/pdf/1810.08425.pdf
FaceBoxes: A CPU Real-time Face Detector with High Accuracy
https://arxiv.org/abs/1708.05234
S3FD: Single Shot Scale-Invariant Face Detector
http://openaccess.thecvf.com/content_ICCV_2017/papers/Zhang_S3FD_Single_Shot_ICCV_2017_paper.pdf
Perceptual Generative Adversarial Networks for Small Object Detection
https://arxiv.org/abs/1706.05274
PyramidBox: A Context-assisted Single Shot Face Detector
https://arxiv.org/abs/1803.07737
Relation Networks for Object Detection
https://arxiv.org/abs/1711.11575交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~