
机器翻译是否能替代人工翻译?从前世今生说起
👆点击“博文视点Broadview”,获取更多书讯

广义上讲,“翻译”是指把一个事物转化为另一个事物的过程。
在人类语言的翻译中,一种语言文字通过人脑转化为另一种语言表达,这是一种自然语言的“翻译”。
如图1所示,可以通过计算机将一句汉语自动翻译为英语,汉语被称为源语言(Source Language),英语被称为目标语言(Target Language)。
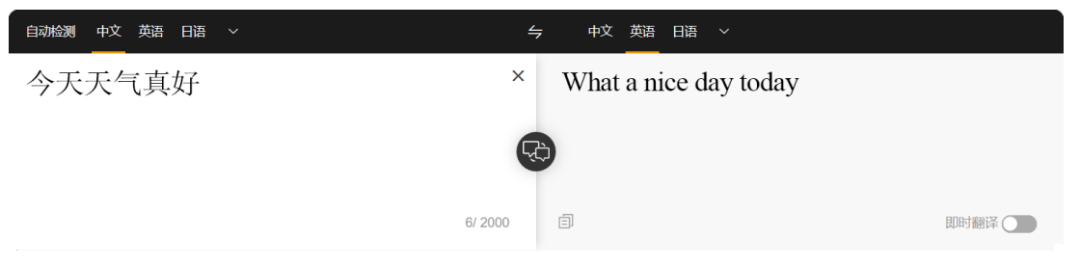
图 1 通过计算机将一句汉语自动翻译为英语
一直以来,文字的翻译往往是由人完成的。
时至今日,人工智能技术的发展已经大大超越了人类传统的认知,用计算机进行自动翻译不再是梦,它已经深入人们生活的很多方面,并发挥着重要作用。
这种由计算机进行自动翻译的过程也被称为机器翻译(Machine Translation)。
类似地,自动翻译、智能翻译、多语言自动转换等概念也是指同样的事情。
实现机器翻译往往需要多个学科知识的融合,如数学、语言学、计算机科学、心理学等,而最终呈现给使用者的是一套软件系统——机器翻译系统。
通俗地讲,机器翻译系统就是一个可以在计算机上运行的软件工具,与人们使用的其他软件一样,只不过机器翻译系统是由“不可见的 程序”组成的。
虽然这个系统非常复杂,但是呈现出来的形式很简单——输入是待翻译的句子或文本,输出是译文句子或文本。
从机器翻译系统的组成上看,通常可以将其抽象为两个部分,如图2 所示。
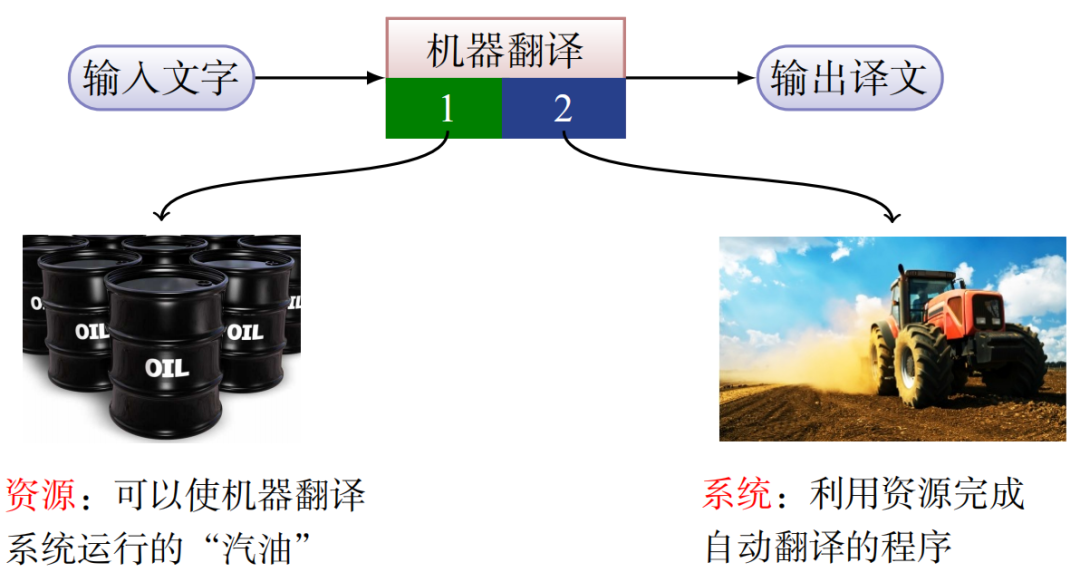
图2 机器翻译系统的组成
资源:如果把机器翻译系统比作一辆汽车,则资源就是可以使汽车运行的“汽油”,它包括翻译规则、双(单)语数据、知识库等翻译知识,且这些“知识”都是计算机可读的。值得 一提的是,如果没有翻译资源的支持,那么任何机器翻译系统都无法运行。
系统:机器翻译算法的程序实现被称作系统,也就是机器翻译研究人员开发的软件。无论是 翻译规则、翻译模板还是统计模型中的参数,都需要通过机器翻译系统进行读取和使用。
构建一个强大的机器翻译系统需要“资源”和“系统”两方面共同作用。
虽然翻译这个概念在人类历史中已经存在了上千年,但机器翻译发展至今只有 70 余年的历史。
机器翻译跌宕起伏的发展史可以分为萌芽期、受挫期、快速成长期和爆发期 4 个阶段。
纵观机器翻译的发展,历程曲折又耐人寻味,可以说,回顾机器翻译的历史对深入理解相关技术方法会有很好的启发,甚至对了解整个自然语言处理领域的发展也有启示作用。
早在17世纪,Descartes、Leibniz、Cave Beck、Athanasius Kircher 和 Johann Joachim Becher 等 很多学者就提出利用机器词典(电子词典)克服语言障碍的想法,这种想法在当时是很超前的。
随着语言学、计算机科学等学科的发展,在 19 世纪 30 年代,使用计算模型进行自动翻译的思想 开始萌芽。当时,法国科学家 Georges Artsrouni 提出了用机器进行翻译的想法。由于那时没有合 适的实现手段,这种想法的合理性无法被证实。
随着第二次世界大战的爆发,对文字进行加密和解密成了重要的军事需求,这也推动了数学和密码学的发展。在战争结束一年后,世界上第一台通用电子数字计算机于1946 年研制成功。至此,使用机器进行翻译有了真正实现的可能。
基于战时密码学领域与通信领域的研究,Claude Elwood Shannon 在 1948 年提出使用“噪声 信道”描述语言的传输过程,并借用热力学中的“熵”(Entropy)来刻画消息中的信息量。
次年, Shannon 与 Warren Weaver 合著了著名的 The Mathematical Theory of Communication[6],这些工作都为后期的统计机器翻译奠定了理论基础。
1949 年,Weaver 撰写了一篇名为 TRANSLATION 的备忘录。在这篇备忘录中,第一次提出了机器翻译,正式创造了机器翻译的概念,这个概念一直沿用至今。
随着电子计算机的发展,研究人员开始尝试使用计算机进行自动翻译。
1954 年,美国乔治敦大学在 IBM 公司的支持下,启动了第一次机器翻译实验。翻译的目标是将几个简单的俄语句子翻译成英语,翻译系统包含 6 条翻译规则和 250 个单词。这次翻译实验中测试了 50 个化学文本句子,取得了初步成功。
在某种意义上,这个实验显示了采用基于词典和翻译规则的方法可以实现 机器翻译过程。虽然只是取得了初步成功,却引发了苏联、英国和日本研究机构的机器翻译研究热,大大推动了早期机器翻译的研究进展。
1957 年,Noam Chomsky 在 Syntactic Structures 中描述了转换生成语法,并使用数学方法研 究自然语言,建立了包括上下文有关语法、上下文无关语法等 4 种类型的语法。这些工作为如今在计算机中广泛使用的“形式语言”奠定了基础,这种思想也深深地影响了同时期的语言学和自 然语言处理领域的学者。特别是在早期基于规则的机器翻译中也大量使用了这些思想。
虽然在这段时间,使用机器进行翻译的议题越加火热,但是事情并不总是一帆风顺,怀疑论者对机器翻译一直存有质疑,并很容易找出一些机器翻译无法解决的问题。自然地,人们也期望能够客观地评估机器翻译的可行性。当时,美国基金资助组织委任自动语言处理咨询会承担了这项任务。
经过近两年的调查与分析,该委员会于1966 年11月公布了一个题为 LANGUAGE AND MACHINES 的报告(如图4 所示),即 ALPAC 报告。该报告全面否定了机器翻译的可行性,为 机器翻译的研究泼了一盆冷水。

图3 ALPAC 报告
随后,美国政府终止了对机器翻译研究的支持,这导致整个产业界和学术界都在回避机器翻译。没有了政府的支持,企业也无法进行大规模资金投入,机器翻译的研究就此受挫。
从历史上看,包括机器翻译在内,很多人工智能的细分领域在那个年代并不受“待见”,其主要原因在于当时的技术水平还比较低,而大家又对机器翻译等技术的期望过高。
最后发现,当时的机器翻译水平无法满足实际需要,因此转而排斥它。也正是这一盆冷水,让研究人员可以更加 冷静地思考机器翻译的发展方向,为后来的爆发蓄力。
事物的发展都是螺旋式上升的,机器翻译也一样。
早期,基于规则的机器翻译方法需要人来书写规则,虽然对少部分句子具有较高的翻译精度,但是对翻译现象的覆盖度有限,而且对规则或者模板中的噪声非常敏感,系统健壮性差。
20 世纪 70 年代中后期,特别是 80 年代到 90 年代初,国家之间的往来日益密切,而不同语言之间形成的交流障碍却愈发严重,传统的人工作业方式远不能满足需求。
与此同时,语料库语言学的发展也为机器翻译提供了新的思路。
一方面,随着传统纸质文字资料不断电子化,计算机可读的语料越来越多,这使得人们可以用计算机对语言规律进行统计分析;另一方面,随着可用 数据越来越多,用数学模型描述这些数据中的规律并进行推理逐渐成为可能。这也衍生出了一类 数学建模方法——数据驱动(Data-driven)的方法。同时,这类方法也成了随后出现的统计机器翻译的基础。例如,IBM 的研究人员提出的基于噪声信道模型的 5 种统计翻译模型就使用了这 类方法。
基于数据驱动的方法不依赖人书写的规则,机器翻译的建模、训练和推断都可以自动地从数据中学习。这使得整个机器翻译的范式发生了翻天覆地的变化,例如,日本学者长尾真提出的基于实例的方法和统计机器翻译就是在此期间兴起的。此外,这样的方法使得机器翻译系统的开发代价大大降低。
从 20 世纪 90 年代到本世纪初,随着语料库的完善与高性能计算机的发展,统计机器翻译很快成了当时机器翻译研究与应用的代表性方法。一个标志性的事件是谷歌公司推出了一个在线的免费自动翻译服务,也就是大家熟知的谷歌翻译。这使得机器翻译这种“高大上”的技术快速进入人们的生活,而不再是束之高阁的科研想法。
随着机器翻译不断走向实用,机器翻译的应用也越来越多,这反过来促进了机器翻译的研究进程。例如,在 2005—2015 年,统计机器翻译这个主题几乎统治了 ACL 等自然语言处理领域的顶级会议,可见其在当时的影响力。
进入 21 世纪,统计机器翻译拉开了黄金发展期的序幕。在这一时期,基于统计机器翻译的模 型层出不穷,经典的基于短语的模型和基于句法的模型也先后被提出。
2013 年以后,机器学习的进步带来了机器翻译技术的进一步提升。特别是基于神经网络的深度学习方法在机器视觉、语音识别中被成功应用,带来性能的飞跃式提升。很快,深度学习方法也被用于机器翻译。
实际上,对于机器翻译任务来说,深度学习方法被广泛使用也是一种必然,原因如下:
(1)端到端学习不依赖于过多的先验假设。在统计机器翻译时代,模型设计或多或少会对翻 译的过程进行假设,称为隐藏结构假设。例如,基于短语的模型假设源语言和目标语言都会被切分成短语序列,这些短语之间存在某种对齐关系。这种假设既有优点也有缺点:一方面,该假设 有助于模型融入人类的先验知识,例如,统计机器翻译中一些规则的设计就借鉴了语言学的相关 概念;另一方面,假设越多,模型受到的限制也越多。如果假设是正确的,模型就可以很好地描 述问题;如果假设是错误的,那么模型对输入的处理就可能出现偏差。深度学习不依赖于先验知 识,也不需要手工设计特征,模型直接从输入和输出的映射上学习(端到端学习),这也在一定程 度上避免了隐藏结构假设造成的偏差。
(2)神经网络的连续空间模型有更强的表示能力。机器翻译中的一个基本问题是:如何表示 一个句子?统计机器翻译把句子的生成过程看作短语或者规则的推导,这本质上是一个离散空间 上的符号系统。深度学习把传统的基于离散化的表示变成连续空间的表示。例如,用实数空间的 分布式表示代替离散化的词语表示,而整个句子可以被描述为一个实数向量。这使得翻译问题可 以在连续空间上描述,进而大大缓解了传统离散空间模型里维度灾难等状况。更重要的是,连续 空间模型可以用梯度下降等方法进行优化,具有很好的数学性质并且易于实现。
(3)深度网络学习算法的发展和图形处理单元(Graphics Processing Unit,GPU)等并行计算 设备为训练神经网络提供了可能。早期的基于神经网络的方法一直没有在机器翻译甚至自然语言 处理领域得到大规模应用,其中一个重要原因是这类方法需要大量的浮点运算,但是以前计算机的计算能力无法达到这个要求。随着 GPU 等并行计算设备的进步,训练大规模神经网络也变为可能。如今,已经可以在几亿、几十亿,甚至上百亿句对上训练机器翻译系统,系统研发的周期越来越短,进展日新月异。
如今,神经机器翻译已经成为新的范式,与统计机器翻译一同推动了机器翻译技术与应用产 品的发展。从世界上著名的机器翻译比赛 WMT 和 CCMT 中就可以看出这个趋势。如图4所 示,图4(a) 所示为 WMT 19 国际机器翻译大赛的参赛队伍,这些参赛队伍基本上都在使用深度 学习完成机器翻译的建模。而夺得 WMT 19 比赛各项目冠军的团队,多采用神经机器翻译系统, 图4(b) 所示为 WMT 19 比赛各项目的最高分。
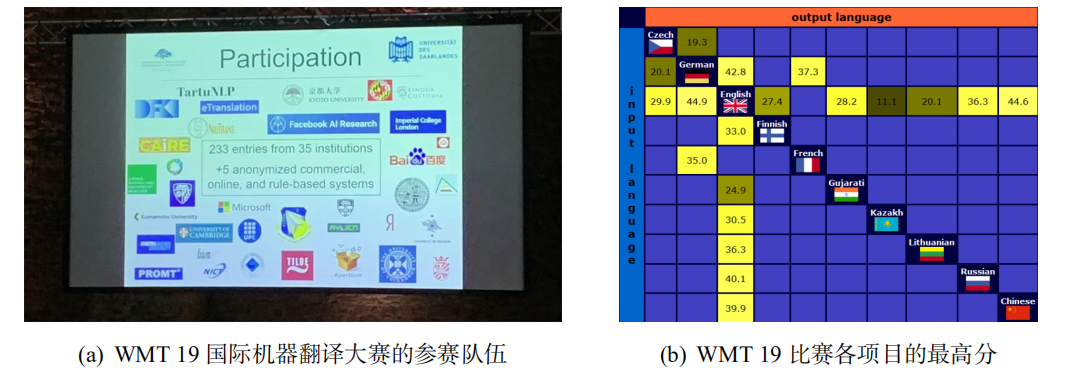
图4 WMT 19 国际机器翻译大赛
值得一提的是,近年,神经机器翻译的快速发展也得益于产业界的关注。各大互联网企业和 机器翻译技术研发机构都对神经机器翻译的模型和实践方法给予了很大贡献。很多企业凭借自身人才和基础设施方面的优势,先后推出了以神经机器翻译为内核的产品及服务,相关技术方法已经在大规模应用中得到验证,大大推动了机器翻译的产业化进程,而且这种趋势在不断加强,机器翻译的前景也更加宽广。
机器翻译技术发展到今天已经过无数次迭代,技术范式也经过若干次更替,机器翻译的应用也如雨后春笋相继浮现。
如今,机器翻译的质量究竟如何呢?
乐观地说,在很多特定的条件下,机器翻译的译文结果是非常不错的,甚至接近人工翻译的结果。然而,在开放式翻译任务中,机器 翻译的结果并不完美。
严格地说,机器翻译的质量远没达到人们所期望的程度。“机器翻译将代替人工翻译”并不是事实。例如,在高精度同声传译任务中,机器翻译仍需要打磨;针对小说的翻译,机器翻译还无法做到与人工翻译媲美;甚至有人尝试用机器翻译系统翻译中国古代诗词,这 种做法更多是娱乐。
毫无疑问的是,机器翻译可以帮助人类,甚至有朝一日可以代替一些低端的人工翻译工作。
图5展示了机器翻译与人工翻译质量的对比结果。在汉语到英语的新闻翻译任务中,如果对译文进行人工评价(五分制),那么机器翻译的译文得 3.9 分,人工译文得 4.7 分(人的翻译也不是完美的)。
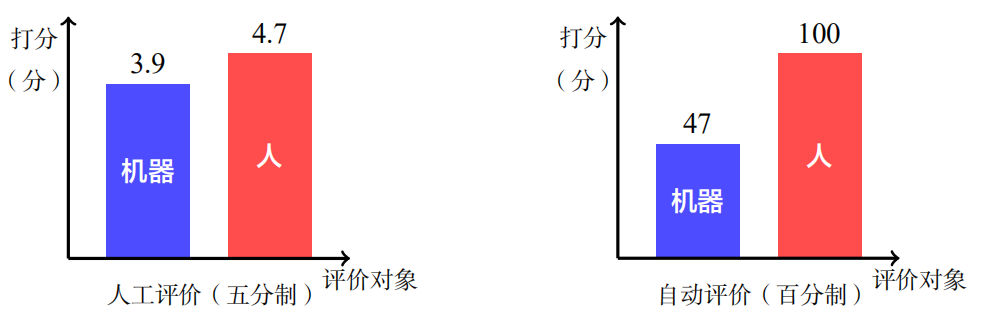
图5 机器翻译与人工翻译质量的对比结果(汉英新闻领域翻译)
可见,虽然在这个任务中机器翻译表现得不错,但是与人还有一定差距。如果换一 种方式评价,把人的译文作为参考答案,用机器翻译的译文与其进行比对(百分制),则会发现机器翻译的得分只有 47 分。
当然,这个结果并不是说机器翻译的译文质量很差,而是表明机器翻译系统可以生成一些与人工翻译不同的译文,机器翻译也具有一定的创造性。这类似于很多围棋选手都想向 AlphaGo 学习,因为它能走出人类棋手从未“走过”的妙招。
图6展示了一个汉译英的翻译实例。对比后可以发现,机器翻译与人工翻译还存在差距,特别是在翻译一些具有感情色彩的词语时,机器翻译的译文缺少一些“味道”。

图6 一个汉译英的翻译实例
那么,机器翻译一点用都没有吗?
显然不是。实际上,如果考虑翻译速度与翻译代价,则机器翻译的价值是无可比拟 的。还是同一个例子,如果人工翻译一篇短文需要 30 分钟甚至更长时间,那么机器翻译仅需要两 秒。换种情况思考,如果有 100 万篇这样的文档,那么其人工翻译的成本根本无法想象,消耗的 时间更是难以计算,而计算机集群仅仅需要一天就能完成,而且只有电力的消耗。
虽然机器翻译有上述优点,但仍然面临如下挑战:
自然语言翻译问题的复杂性极高。自然语言具有高度的概括性、灵活性和多样性,这些都很难用几个简单的模型和算法来描述。因此,翻译问题的数学建模和计算机程序的实现难度很大。
计算机的“理解”与人类的“理解”存在鸿沟。人类一直希望把自己翻译时所使用的知识描述出来,并用计算机程序进行实现,如早期基于规则的机器翻译方法就源自这个思想。但是,经过实践发现,人和计算机在“理解”自然语言上存在明显差异。
单一的方法无法解决多样的翻译问题。首先,语种的多样性会导致任意两种语言之间的翻译实际上都是不同的翻译任务。其次,不同的领域、 不同的应用场景对翻译有不同的需求。再次,对于机器翻译来说,充足的高质量数据是必要的,但是不同语种、不同领域、不同应 用场景所拥有的数据量有明显差异,很多语种甚至几乎没有可用的数据。这时,开发机器翻译系统的难度可想而知。
显然,实现机器翻译并不简单,甚至有人把机器翻译看作实现人工智能的终极目标。
幸运的是,如今的机器翻译无论是在技术方法上,还是在应用上都有了巨大的飞跃,很多问题在不断被解决。如果读者看到过十年前机器翻译的结果,再对比如今的结果,一定会感叹翻译质量的今非 昔比,很多译文已经非常准确且流畅。
从当今机器翻译的前沿技术看,近 30 年机器翻译的进步更多是得益于使用基于数据驱动的方法和统计建模方法。特别是近些年深度学习等基于表示学习的端到端方法使得机器翻译的水平达到了新高度。
因此,《机器翻译》一书将对基于统计建模和深度学习方法的机器翻译模型、方法和系统实现进行全面介绍和分析,希望这些论述可以为读者的学习和科研提供参考。


五折专享,快快扫码抢购吧!
如果喜欢本文 欢迎 在看丨留言丨分享至朋友圈 三连 热文推荐
▼点击阅读原文,查看本书详情~