
sync.Once 的前世今生
大家好,我是好久不见的薯条,上篇文章 编写一个配置化的Kafka Proxy,让你分钟级别接入Kafka 的阅读量很惨淡,搞得我那段时间有点丧,可能大家还是更喜欢Golang方面的文章,也可能是那篇写的有点搓... 这几天北京降温又下雨,我久违的感冒了,秋高气爽,读者朋友们要注意多加衣服啊,感冒还是很难受的。
这篇once的文章前前后后看了好多参考,改了好几遍,最终出来这么个鸟样子,个人感觉并发编程这块水很深,因为这块不仅涉及Golang源码,还涉及到汇编、操作系统、甚至是硬件的知识,真是学无止境,有兴趣的朋友可以查一下Read Acquire、Write Release和Golang官方的Memory Model一文。
以下是正文:




type Resource struct {
addr string
}
var Res *Resource
var once sync.Once
func GetResourceOnce(add string) *Resource {
once.Do(func() {
Res = &Resource{addr: add}
})
return Res
}
func main() {
fmt.Println(GetResource("beijing"))
}
// output:{beijing}



例子:
var Resp *Resource
var mut sync.Mutex
func GetResourceMutex(add string) *Resource {
mut.Lock()
defer mut.Unlock()
if Resp != nil {
return Resp
}
Resp = &Resource{addr: add}
return Resp
}


1. 为啥源码引入Mutex而不是CAS操作
3. 为啥要有fast path, slow path
4. 加锁之后为啥要有done==0,为啥有double check,为啥这里不是原子读
4.store为啥要加defer
5.为啥是atomic.store,不是直接赋值1


Once开始的地方
type Once struct {
m Mutex
done bool
}
func (o *Once) Do(f func()) {
o.m.Lock()
defer o.m.Unlock()
if !o.done {
o.done = true
f()
}
}
在这段2010年8月15日提交的代码中,作者借助Mutex实现Once语义,执行的时候先加一把互斥锁,保证只有一个协程可以操作done变量,等f函数执行完解锁。
这样的代码相当于mvp版本,管用,但是略显粗糙,一个最显而易见的缺点:每次都要执行Mutex加锁操作,对于Once这种语义有必要吗,是否可以先判断一下done的value是否为true,然后再进行加锁操作呢?
第一次进化

于是Once开始了第一次进化,这次优化改进了上面提到的问题:若Once已经初始化,那么Do内部将不会执行抢锁操作。做这份代码改动的哥们经过测试发现这样改在不同核的benchmark中有92%-99%的耗时提升。
type Once struct {
m Mutex
done int32
}
func (o *Once) Do(f func()) {
if atomic.AddInt32(&o.done, 0) == 1 {
return
}
// Slow-path.
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
f()
atomic.CompareAndSwapInt32(&o.done, 0, 1)
}
}
在这段代码中,在slow-path加锁后,要继续判断done值是否为0,确认done为0后才要执行f()函数,这是因为在多协程环境下仅仅通过一次atomic.AddInt32判断并不能保证原子性,比如俩协程g1、g2,g2在g1刚刚执行完atomic.CompareAndSwapInt32(&o.done, 0, 1)进入了slow path,如果不进行double check,那g2又会执行一次f()。
在这次改动中,作者用一个int32变量done表示once的对象是否已执行完,有两个地方使用到了atomic包里的方法对o.done进行判断,分别是,用AddInt32函数根据o.done的值是否为1判断once是否已执行过,若执行过直接返回;f()函数执行完后,对o.done通过cas操作进行赋值1。
这两处地方的存在有一定的争议性,在源码cr的过程中就被问到atomic.CompareAndSwapInt32(&o.done, 0, 1)可否被o.done == 1替换,
答案是不可以。
现在的CPU一般拥有多个核心,而CPU的处理速度快于从内存读取变量的速度,为了弥补这俩速度的差异,现在CPU每个核心都有自己的L1、L2、L3级高速缓存,CPU可以直接从高速缓存中读取数据,但是这样一来内存中的一份数据就在缓存中有多份副本,在同一时间下这些副本中的可能会不一样,为了保持缓存一致性,Intel CPU使用了MESI协议。
AddInt32方法和CompareAndSwapInt32方法(均为amd64平台 runtime/internal/atomic/atomic_amd64.s)底层都是在汇编层面调用了LOCK指令,LOCK指令通过总线锁或MESI协议保证原子性(具体措施与CPU的版本有关),提供了强一致性的缓存读写保证,保证LOCK之后的指令在带LOCK前缀的指令执行之后才执行,从而保证读到最新的o.done值。
第二次进化
至此Once的代码已经成型了,后面来列举一些小优化的集合:
小优化一
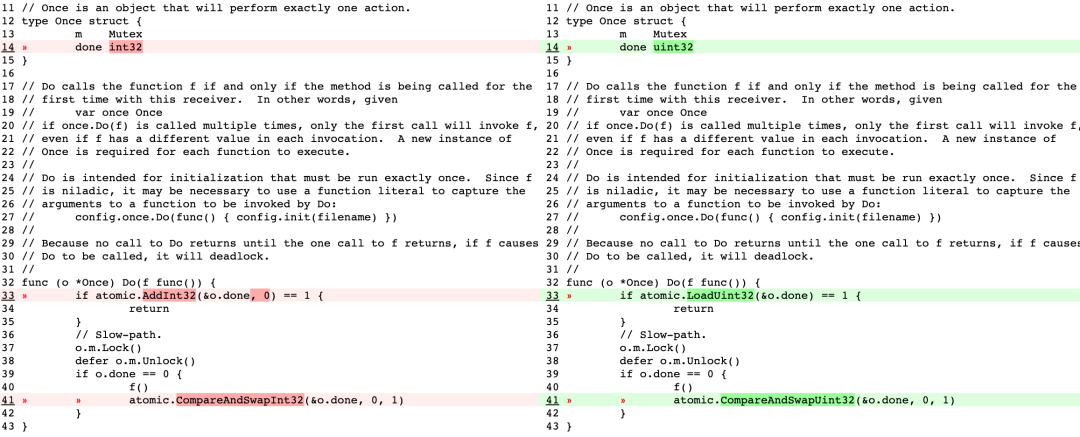
这个小优化把done的类型由int32替换为uint32,用CompareAndSwapUint32替换了CompareAndSwapInt32, 用LoadUint32替换了AddInt32方法,LoadUint32底层并没有LOCK指令用于加锁,我觉得能这么写的主要原因是进入slow path之后会继续用Mutex加锁并判断o.done的值,且后面的CAS操作是加锁的,所以可以这么改。这次优化经过benchmark测试性能在不同核心上有45%-94%的提升。
小优化二

这次小优化用StoreUint32替换了CompareAndSwapUint32操作,CAS操作在这里确实有点多余,因为这行代码最主要的功能是原子性的done = 1。
Store命令的底层是,其中关键的指令是XCHG,有的同学可能要问了,这源码里没有LOCK指令啊,怎么保证happen before呢,Intel手册有这样的描述: The LOCK prefix is automatically assumed for XCHG instruction.,这个指令默认带LOCK前缀,能保证Happen Before语义。
TEXT runtime∕internal∕atomic·Store(SB), NOSPLIT, $0-12
MOVQ ptr+0(FP), BX
MOVL val+8(FP), AX
XCHGL AX, 0(BX)
RET
小优化三
 这次的优化在
这次的优化在StoreUint32前增加defer前缀,增加defer是保证 即使f()在执行过程中出现panic,Once仍然保证f()只执行一次,这样符合严格的Once语义。
除了预防panic,defer还能解决指令重排的问题:现在CPU为了执行效率,源码在真正执行时的顺序和代码的顺序可能并不一样,比如这段代码中a不一定打印"hello, world",也可能打印空字符串。
var a string
var done bool
func setup() {
a = "hello, world"
done = true
}
func main() {
go setup()
for !done {
}
print(a)
}
而增加了defer前缀,能保证,即使出现指令重排,done变量也能在f()函数执行完后才进行store操作。
小优化四
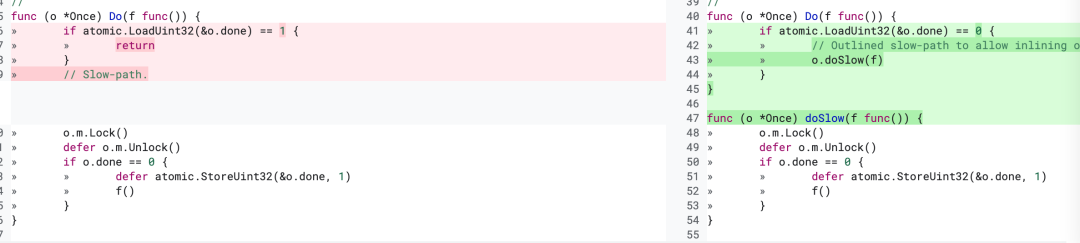
这次优化主要是用函数区分开了fast path和slow path,对fast path做了内联优化。这样进一步降低了使用Once的开销,因为fast path会被内联到使用once的函数调用中,每次调用的时候如果只走到fast path那么连函数调用的开销都省去了,这次优化在不同核的环境下又有54%-67%的提升。




type St struct {
ponce *sync.Once
}
func (st *St) Reset() {
st.ponce = new(sync.Once)
}
func main() {
s := &St{}
f1 := func() {
fmt.Println("hello, world")
}
s.Reset()
s.ponce.Do(f1)
s.Reset()
s.ponce.Do(f1)
}
