
觅食宝典
作为服务注册中心,Eureka与Zookeeper区别
著名的CAP理论指出,一个分布式系统不可能同时满足C(一致性)、A(可用性)和P(分区容错性)。由于分区容错性在是分布式系统中必须要保证的,因此我们只能在A和C之间进行权衡。在此Zookeeper保证的是CP, 而Eureka则是AP。
RDBMS==>(MySql,Oracle,SqlServer等关系型数据库)遵循的原则是:ACID原则(A:原子性。C:一致性。I:独立性。D:持久性。)。
NoSql==> (redis,Mogodb等非关系型数据库)遵循的原则是:CAP原则(C:强一致性。A:可用性。P:分区容错性)。
在分布式领域有一个很著名的CAP定理:C:数据一致性。A:服务可用性。P:分区容错性(服务对网络分区故障的容错性)。
Zookeeper保证CP
当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。但是zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因网络问题使得zk集群失去master节点是较大概率会发生的事,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。
zookeeper原理
ZooKeeper是以Fast Paxos算法为基础的,Paxos 算法存在活锁的问题,即当有多个proposer交错提交时,有可能互相排斥导致没有一个proposer能提交成功,而Fast Paxos作了一些优化,通过选举产生一个leader (领导者),只有leader才能提交proposer,具体算法可见Fast Paxos。因此,要想弄懂ZooKeeper首先得对Fast Paxos有所了解。 ZooKeeper的基本运转流程: 1、选举Leader。 2、同步数据。 3、选举Leader过程中算法有很多,但要达到的选举标准是一致的。 4、Leader要具有最高的执行ID,类似root权限。 5、集群中大多数的机器得到响应并接受选出的Leader。 其他 HBase和ZooKeeper HBase内置有ZooKeeper,也可以使用外部ZooKeeper。 让HBase使用一个已有的不被HBase托管的Zookeep集群,需要设置 conf/hbase env sh文件中的HBASE_MANAGES_ZK 属性为 false ... # Tell HBase whether it should manage it's own instance of Zookeeper or not. export HBASE_MANAGES_ZK=false 接下来,指明Zookeeper的host和端口。可以在 hbase-site.xml中设置, 也可以在HBase的CLASSPATH下面加一个zoo.cfg配置文件。HBase 会优先加载 zoo.cfg 里面的配置,把hbase-site.xml里面的覆盖掉. 当HBase托管ZooKeeper的时候,Zookeeper集群的启动是HBase启动脚本的一部分。但你需要自己去运行。你可以这样做 ${HBASE_HOME}/bin/hbase-daemons sh {start,stop} zookeeper 你可以用这条命令启动ZooKeeper而不启动HBase. HBASE_MANAGES_ZK 的值是 false, 如果你想在HBase重启的时候不重启ZooKeeper,你可以这样做 对于独立Zoopkeeper的问题,你可以在 Zookeeper启动得到帮助 列如: zookeeper也可以作为注册中心,用于服务治理(zookeeper还有其他用途,例如:分布式事务锁等) 每启动一个微服务,就会去zk中注册一个临时子节点, 例如:5台订单服务,4台商品服务 (5台订单服务在zk中的订单目录下创建的5个临时节点) (4台商品服务在zk中的商品目录下创建的4个临时接点) 每当有一个服务down机,由于是临时接点,此节点会立即被删除,并通知订阅该服务的微服务更新服务列表 (zk上有watch,每当有节点更新,都会通知订阅该服务的微服务更新服务列表) 每当有一个新的微服务注册进来,就会在对应的目录下创建临时子节点,并通知订阅该服务的微服务更新服务列表 (zk上有watch,每当有节点更新,都会通知订阅该服务的微服务更新服务列表) 每个微服务30s向zk获取新的服务列表 |
Eureka保证AP
Eureka看明白了这一点,因此在设计时就优先保证可用性。Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:1. Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务 2. Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用) 3. 当网络稳定时,当前实例新的注册信息会被同步到其它节点中
因此, Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使整个注册服务瘫痪。
eureka的核心角色
eureka server
存储服务注册列表
eureka client
eureka的客户端
拉取server的注册列表
周期性与server保持一个心跳机制(默认周期30秒)
服务状态
服务续约
eureka客户端每隔30秒,发送一个心跳给eureka server,证明此服务是存活,进行续约的操作行为
服务下线
当application server应用停止,向eureka server,发送cancel请求,server接受到此请求指令,就会从服务列表删除此服务
服务剔除
eureka server启动后在后台启动一个任务,此任务对在一定时间内没有续约的服务进行剔除
保护模式

触发了eureka server的自我保护机制
条件:Eureka Server 在运行期间会去统计心跳失败比例在 15 分钟之内是否低于 85%,如果低于 85%,Eureka Server 会将这些实例保护起来
哲学道理:宁可先保护此服务实例,都不会盲目的删除此服务
eureka原理
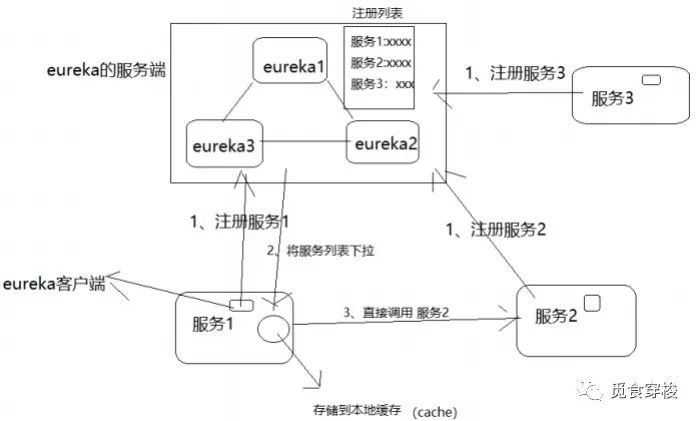
| 每一个微服务中都有eureka client,用于服务的注册于发现 (服务的注册:把自己注册到eureka server) (服务的发现:从eureka server获取自己需要的服务列表) 每一个微服务启动的时候,都需要去eureka server注册 当A服务需要调用B服务时,需要从eureka服务端获取B服务的服务列表,然后把列表缓存到本地,然后根据ribbon的客户端负载均衡规则,从服务列表中取到一个B服务,然后去调用此B服务 当A服务下次再此调用B服务时,如果发现本地已经存储了B的服务列表,就不需要再从eureka服务端获取B服务列表,直接根据ribbon的客户端负载均衡规则,从服务列表中取到一个B服务,然后去调用B服务 微服务,默认每30秒,就会从eureka服务端获取一次最新的服务列表 如果某台微服务down机,或者添加了几台机器, 此时eureka server会通知订阅他的客户端,并让客户端更新服务列表, 而且还会通知其他eureka server更新此信息 心跳检测,微服务每30秒向eureka server发送心跳, eureka server若90s之内都没有收到某个客户端的心跳,则认为此服务出了问题, 会从注册的服务列表中将其删除,并通知订阅它的客户端更新服务列表, 而且还会通知其他eureka server更新此信息 eureka server保护机制,通过打卡开关,可以让eureka server处于保护状态,主要是用于某eureka server由于网络或其他原因,导致接收不到其他微服务的心跳,此时不能盲目的将其他微服务从服务列表中删除。具体规则:如果一段时间内,85%的服务都没有发送心跳,则此server进入保护状态,此状态下,可以正常接受注册,可以正常提供查询服务,但是不与其他server同步信息,也不会通知订阅它的客户端,这样就不会误杀其他微服务 |