
Kaggle入坑宝典

「背景前情提要」
💘背景
"哈哈,我和妹子成了,她准备带我打kaggle比赛了!"
"皇天不负苦心我,终于我感觉我解脱了!两位大佬带带我呀!"
"大佬谦虚了,不过我和女朋友两个人做这个,时间上可能会稍微有点紧张,要不我们仨一起做这个吧?😼"
"好呀好呀!😁"
"对了,你先把比赛的情况介绍下,顺便写个文档,我们后续可以讨论下,再看看比赛参赛人员开源的一些code,看看哪里可以借鉴的,嗯,差不多,这工作量不大😯"
"(你......说......这......工......作......量......不......大?)有点多吧?!要不我们两先把这块工作做掉?"
"要是勉强的话,也行吧,我和妹子完成咯!"
"别别别,我来我来(毕竟有她妹子这个大佬,前期我就辛苦点),不勉强不勉强!🐶"
"好嘞,我先和他去涮🔥锅了,你弄完一起来哈!"
"我争取...早点过去"

比赛简介
名称
Coleridge Initiative - Show US the Data
Discover how data is used for the public good
目的
「确定科学出版物中提到的数据集。」
参赛者的初始预测结果将是摘自一些出版物的简短摘录,这些预测结果通过简单的文本函数处理能够获得最终的数据集的名称。
该竞赛的目标不仅是匹配已知的数据集字符串,而且是将其推广到使用NLP和统计技术之前从未见过的数据集。一定比例的公开测试集出版物是从训练集中提取的,但并非所有数据集名称都已在训练集中出现,因此这些未识别的数据集已被用作公开测试(public test)标签的一部分。
数据
官方给了三类数据:
训练相关数据,
测试相关数据,
提交样例文件,
总共4个文件(夹)(不包含私有测试(private test)):
train(文件夹):
JSON格式的文本文件,当中的每个文件是一个出版物的部分章节(section)内容,因为一个出版物可能将划分为多个这样的文本文件。

test(文件夹):
测试集,包含用于预测的出版物文本。
train.csv(文件):
相当于是给出Label。该文件标示出不同的出版物中含有的数据集的名称。

除此之外,官方给出了数据文件中不同列名的具体含义:
id:出版物的标识 pub_title:出版物的标题 dataset_title:在出版物中,提及到的数据集的标题 dataset_label:能够表明数据集的文本片段 cleaned_label:通过给定的文本处理函数“clean_text”获取的最终Label

评价方式
「Jaccard-based FBeta」
这个评价方式的名字看起来吓人,其实也就是micro F1 score的一种变种。我们先看看micro F1 score、FBeta和Jaccard score的计算方式,最后很容易理解Jaccard-based FBeta。
micro F1 score
假设一个多分类问题,有三个类,分别记为1、2、3,
TPi是指分类i的True Positive;
FPi是指分类i的False Positive;
TNi是指分类i的True Negative;
FNi是指分类i的False Negative。
接下来,我们来算micro精度(precision):
precision_mi=(TP1+TP2+TP3)/(TP1+FP1+TP2+FP2+TP3+FP3)
以及micro召回(recall):
recall_mi=(TP1+TP2+TP3)/(TP1+FN1+TP2+FN2+TP3+FN3)
最后micro-F1的计算公式为:
F1=2*(recall_mi×precision_mi)/(recall_mi+precision_mi)
FBeta
计算时,多了一个系数Beta(本次比赛Bete=0.5):
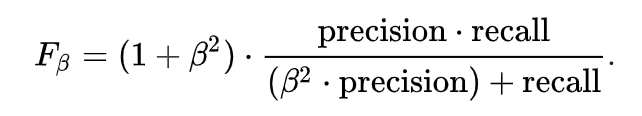
Jaccard score
计算方式如下:

Jaccard-based FBet
通过上面的拆解,很容易明白当前的评价方式,就是F1score上每个计算部分(步骤)拓展获得的最终结果。当有多个预测结果(即一个出版物有多个数据集)时,官方给了如下计算TP,FP,FN的方式:
计算所有可能的预测值和真实label组成pair的Jaccard score 当Jaccard score大于0.5时,当前的预测值记为TP,剩余的记为FP 任何没有匹配到的预测值记为FP 任何不能匹配到最接近预测值(即对某个ground truth来说Jaccard score全为0)的ground truths记为FN
后续计算就简单了。
奖励
真是几万几万刀,我酸了🍋🍋

时间线
2021年3月23日-开始日期。
2021年6月15日-报名截止日期。必须在此日期之前接受比赛规则才能参加比赛。
2021年6月15日-团队合并截止日期。这是参与者可以加入或合并团队的最后一天。
2021年6月22日-最终提交截止日期。
Baseline
 截止本文发出时,当前分数最高的基线是一个16岁的印度高中生开源。
截止本文发出时,当前分数最高的基线是一个16岁的印度高中生开源。
该基线的特点就是一个字:「简单🍳」
一句话总结下他的思路:
在常用的文本预处理后,判断训练的出版物数据中是否存在已有数据集名称,有就直接作为预测标签🏷️。
最后还能占个奖牌位(只是暂时):

就这么简单!(其实我jio得这更像是数据挖掘相关的工作......)
后续工作
1.提升数据预处理的效果
2.通过NER和QA的方式,结合预训练模型获取数据集对应的Span
3.多模型融合
4.数据增强/AT
5.对抗文本「尝试」
强烈推荐关注 「NLP情报局」 获取比赛的相关内容和最新的进展!
「原创不易,看在忍着🔥锅肝文章的份上,各位看官动动小手,一键三连,幸福连连🥰!」

推 荐 阅 读
原创不易,有收获的话请帮忙点击分享、点赞、在看🙏