
2019文字识别方法总结
共 2039字,需浏览 5分钟
·
2022-02-09 17:36
总结文字识别领域三大方法:
1. CTC
2. Attention
3. ACE(后起之秀,出自华南理工大学,速度更快,存储更小,数量级的提升)

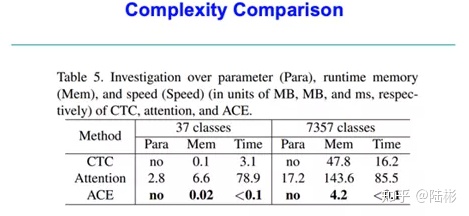
主要从三方面比较了这三种文字识别算法
l 参数量(Para)
l 运行内存(Mem)
l 推理速度(Speed)
基于文本内容的不同,可以分为长文本识别和短文本识别;
基于语言符号个数的不同,又可以少类别(比如英文+数字36个字符)和多类别(中文>5000个字符);
注意:ACE其实更像是CTC的优化版,变种;这两者可以说都是不需要额外的参数的(相比较Attention而言)
从Para来说, Attention需要额外的计算参数; CTC和ACE都是不需要的
从Mem来说,CTC和ACE计算需要的内存很少,这里指的都是推理的时候;CTC和ACE都需要做解码操作,而解码的复杂度和序列长度、字符个数呈正相关。那为何ACE需要的内存更少,而且几乎是少了一个数量级(5~10倍)留待看了论文之后,再做分析; 总之,ACE > CTC > Attention.
从Time来说,CTC和ACE的运行时间明显少很多。官方说法,Attention比CTC慢5~20倍;而ACE比CTC快了约30倍;为何ACE会这么快, 后面再分析. 而ACE的推理时间,几乎可以忽略不计,这个就是质的飞跃了。
同时横向比较下: 推理时的文本长度没法确定,可以认为都是一样的。当然各个语种,其实文本的平均长度是不一样的。字符数量,从37类(其实就是英文+数字, 26+10+1), 到7357,其实就是中文。说白了,做中文识别和做英文识别,会有些许差异。
CTC,随着字符集的扩大,所需内存和推理时间,都随着增大,约为o(n)的关系;如果你只考虑greedy decoding的方法,就可以轻易得到这个结论。推理时间约为o(logn)的关系。
CTC典型的操作,1. 取概率最大;2.去重,去fi; 求最大可以采用归并,所以是o(logn)复杂度。
Attention呢; 是端到端的方法,直接从网络输出结果;所以是可以完全再GPU上执行的。由于每个字符的输出依赖于前一个字符作为输入,所以 1. 推理的时候没办法并行;2. 如果有一个错了,那么后面也会错得比较离谱;随着字符集的增大, 显存占用会明显提升,但推理时间并没有什么变化? 我觉得可能是因为GPU的并行计算, 虽然要算的输出量增大了,权重矩阵也变大了,但GPU高度并行化,并没有带来太多的时间消耗。 另外一点,attention一定要把上一次的输出,作为下一个字符预测的输入吗??答案是不一定(就和CTC一样,如果你加入了这个机制,相当于引入了一个语言模型。理论上效果会有一定提升。
综合来看,ACE简直是大杀器,各方面全面碾压,那么他是如何做的呢?!


看了全文,非常不错的工作。提出了一个新的loss计算方法: Aggregation cross-entropy. 更多像是针对CTC Loss计算的一个优化方案。 CTC loss计算非常麻烦,耗内存,消耗时间;ACE就是把每一个时间片t预测的概率,进行聚合(其实就是累加), 然后归一化(除以序列长度T). 与 truth中每个元素出现的次数归一化值,做交叉熵。
实验证明,交叉熵比L2效果好不止一星半点!
这是一个通用的序列识别loss函数,所以用在很多上面,常见的文本识别,手写汉字识别,物体个数,语音识别可以吗?理论上我觉得也可以。
启发:
1. 在大量样本的情况下,最后比较一些简单的统计指标是可行的。因为方程多了,约束多了之后,就可以计算出每个未知量的值。举例:
当你知道 x+y=2; 2 *x + y= 3之后,你就可以得到x =1,y=1; 如果再给你两个方程,即使没有真解,你也可以得到使得方程基本正确(MSE loss最小)的近似最佳值。
2. 貌似只能用在分类(多物体,多类别),或者个数统计上。能做回归吗? 能,但貌似时间和内存消耗的优势不明显。
3. 还有哪些简单的统计指标: 数个数实在是太秒了! 启发,分段统计? 比如将图片切分成上下或者左右两部分,分别求出统计值,会不会使得监督更强,效果更好呢??!!
Aggregation Cross-EntropyPS: OCR由于应用价值及商业变现的原因,一直以来开源的repo比较少。2020年以来,开源建设这块逐渐有了起色,其中PaddleOCR以国产框架paddle为基础、开源发布了多种文字检测(EAST, DB)、文字识别算法(CRNN、RARE), 包括百度自研的性能极佳的文字检测算法SAST 和文字识别算法SRN, 辅以用户友好、易于上手的文档说明,而深受开发者青睐,目前star数已经突破8000,直逼10000 star. 对OCR感兴趣的小伙伴、OCR研究人员、从业人员不容错过
https://github.com/PaddlePaddle/PaddleOCR