
全面超越Swin Transformer | Facebook用ResNet思想升级MViT


在本文中研究了多尺度Vision Transformer(MViT)作为图像和视频分类以及目标检测的统一架构。作者提出了一个MViT的改进版本,它结合了分解的相对位置嵌入和池化残差连接。
作者以五种大小实例化了这种架构,并在ImageNet分类,COCO检测和动力学视频识别方面进行评估,它们优于之前的工作。作者还进一步比较了MViT的pooling attention和window attention,前者在准确性/计算方面优于后者。
MViT在3个领域具有最先进的性能:ImageNet分类准确率为88.8%,COCO目标检测准确率为56.1AP%,Kinetics-400视频分类准确率为86.1%。
1简介
为不同的视觉识别任务设计架构一直以来都很困难,而采用最广泛的架构是那些结合了简单和高效的架构,例如VGGNet和ResNet。最近,Vision Transformers(ViT)已经展现出了有前途的性能,并可以与卷积神经网络竞争,最近也有很多研究提出了很多的改进工作,将它们应用到不同的视觉任务。
虽然ViT在图像分类中很受欢迎,但其用于高分辨率目标检测和时空视频理解任务仍然具有挑战性。视觉信号的密度对计算和内存需求提出了严峻的挑战,因为在基于Vision Transformer的模型的Self-Attention Block中,这些信号的复杂性呈二次型。
采用了两种不同的策略来解决这个问题:
- Window Attention:在 Window 中进行局部注意力计算用于目标检测;
- Pooling Attention:在 Self-Attention 之前将局部注意聚合在一起。
而Pooling Attention为多尺度ViT带来了很多的启发,可以以一种简单的方式扩展ViT的架构:它不是在整个网络中具有固定的分辨率,而是具有从高分辨率到低分辨率的多个阶段的特性层次结构。MViT是为视频任务设计的,它具有最先进的性能。
在本文中,作者做了两个简单的改进以进一步提高其性能,并研究了MViT作为一个单一的模型用于跨越3个任务的视觉识别:图像分类、目标检测和视频分类,以了解它是否可以作为空间和时空识别任务的一般视觉Backbone(见图1)。
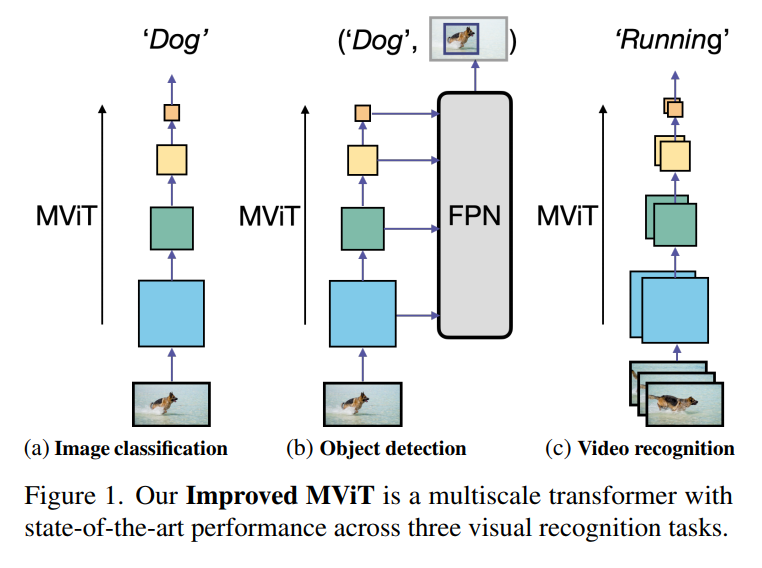 图1 改进版MViT
图1 改进版MViT本文改进MViT体系结构主要包含以下内容:
创建了强大的Baseline,沿着2个轴提高pooling attention:使用分解的位置距离将位置信息注入Transformer块;通过池化残差连接来补偿池化步长在注意力计算中的影响。上述简单而有效的改进带来了更好的结果;
将改进的MViT结构应用到一个带有特征金字塔网络(FPN)的Mask R-CNN,并将其应用于目标检测和实例分割;
作者研究MViT是否可以通过pooling attention来处理高分辨率的视觉输入,以克服计算和内存成本。
实验表明,pooling attention比 local window attention(如Swin)更有效。
作者进一步开发了一个简单而有效的Hybrid window attention方案,可以补充pooling attention以获得更好的准确性和计算折衷。
- 在5个尺寸的增加复杂性(宽度,深度,分辨率)上实例化了架构,并报告了一个大型多尺度ViT的实践训练方案。该MViT变体以最小的改进,使其可以直接应用于图像分类、目标检测和视频分类。
实验表明,Improved MViT在ImageNet-21K上进行预处理后,准确率达到了88.8%(不进行预处理的准确率为86.3%);仅使用Cascade Mask R-CNN在COCO目标检测AP可以达到56.1%。对于视频分类任务,MViT达到了前所未有的86.1%的准确率;对于Kinetics-400和Kinetics-600分别达到了86.1%和87.9%,并在Kinetics-700和Something-Something-v2上也分别达到了79.4%和73.7%的精度。
2回顾一下多尺度ViT
MViT的关键思想是为low-level和high-level可视化建模构建不同的阶段,而不是ViT中的单尺度块。如图2所示MViT从输入到输出的各个阶段缓慢地扩展通道D,同时降低分辨率L(即序列长度)。
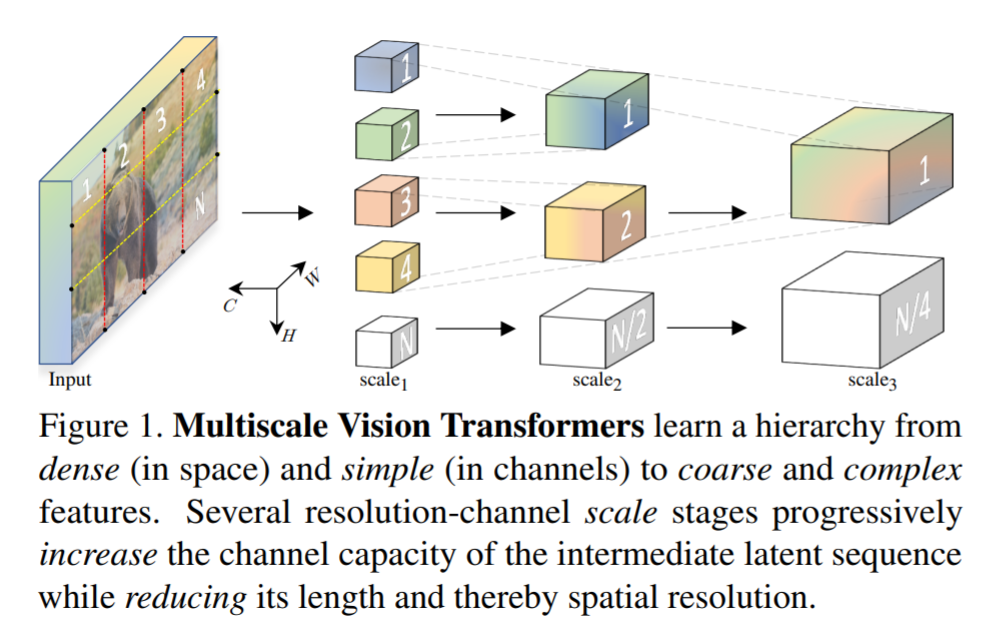 图2 MViT
图2 MViT为了在Transformer Block内进行降采样,MViT引入了Pooling Attention。
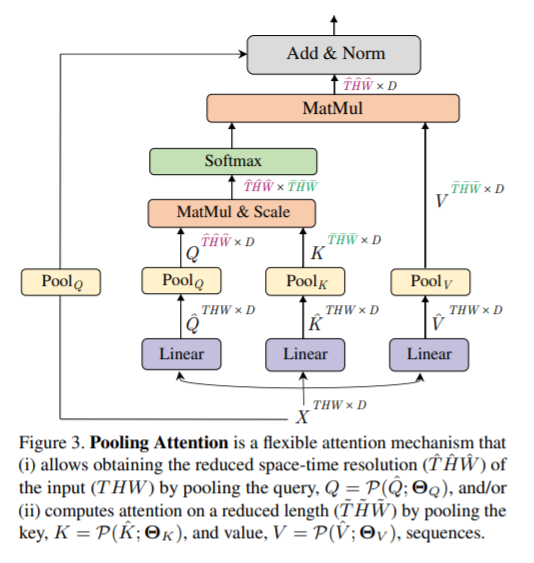 图3 Pooling Attention
图3 Pooling Attention具体来说,对于一个输入序列,对它应用线性投影,,然后是Pool运算(P),分别用于query、key和value张量:
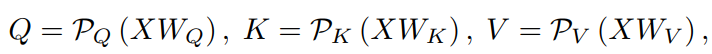
其中,的长度可以通过来降低,K和V的长度可以通过和来降低。
随后,pooled self-attention可以表达为:
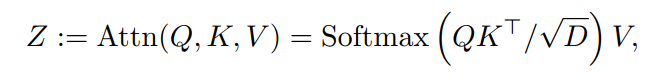
计算长度灵活的输出序列。注意,key和value的下采样因子和可能与应用于query序列的下采样因子不同。
Pooling attention可以通过Pooling query Q来降低MViT不同阶段之间的分辨率,并通过Pooling key K和value V来显著降低计算和内存复杂度。
Pooling Attention的Pytorch实现如下:
# pool通常是MaxPool3d或AvgPool3d
def attention_pool(tensor, pool, thw_shape, has_cls_embed=True, norm=None):
if pool is None:
return tensor, thw_shape
tensor_dim = tensor.ndim
if tensor_dim == 4:
pass
elif tensor_dim == 3:
tensor = tensor.unsqueeze(1)
else:
raise NotImplementedError(f"Unsupported input dimension {tensor.shape}")
if has_cls_embed:
cls_tok, tensor = tensor[:, :, :1, :], tensor[:, :, 1:, :]
B, N, L, C = tensor.shape
T, H, W = thw_shape
tensor = (tensor.reshape(B * N, T, H, W, C).permute(0, 4, 1, 2, 3).contiguous())
# 执行pooling操作
tensor = pool(tensor)
thw_shape = [tensor.shape[2], tensor.shape[3], tensor.shape[4]]
L_pooled = tensor.shape[2] * tensor.shape[3] * tensor.shape[4]
tensor = tensor.reshape(B, N, C, L_pooled).transpose(2, 3)
if has_cls_embed:
tensor = torch.cat((cls_tok, tensor), dim=2)
if norm is not None:
tensor = norm(tensor)
# Assert tensor_dim in [3, 4]
if tensor_dim == 4:
pass
else: # tensor_dim == 3:
tensor = tensor.squeeze(1)
return tensor, thw_shape
3Improved MViT
3.1 改进Pooling Attention
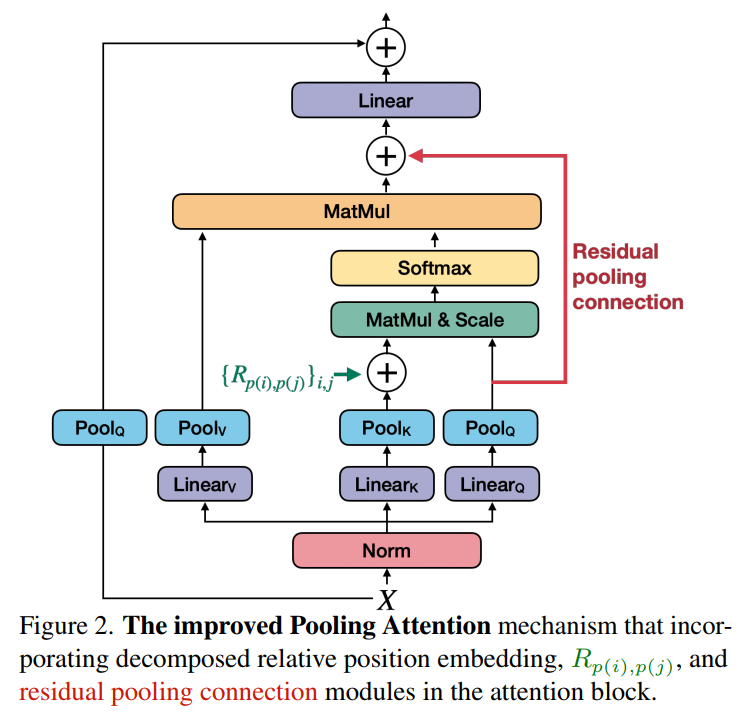 图4 改进版Pooling Attention
图4 改进版Pooling Attention1、分解相对位置嵌入
虽然MViT在建模Token之间的交互方面已经显示出了潜力,但它们关注的是内容,而不是结构。时空结构建模仅依靠绝对位置嵌入来提供位置信息。这忽略了视觉的平移不变性的基本原则。也就是说,即使相对位置不变,MViT建模两个patch之间交互的方式也会随着它们在图像中的绝对位置而改变。为了解决这个问题,作者将相对位置嵌入(相对位置嵌入只依赖于Token之间的相对位置距离)纳入到Pooled Self-Attention 计算中。
这里将2个输入元素和之间的相对位置编码为位置嵌入,其中和表示元素和的空间(或时空)位置,然后将两两编码嵌入到Self-Attention模块中:
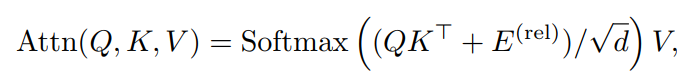
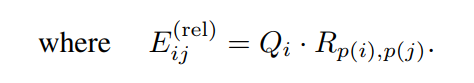
然而,在O(TWH)中possible embeddings的数量规模,计算起来比较复杂。为了降低复杂度,作者将元素和之间的距离计算沿时空轴分解为:
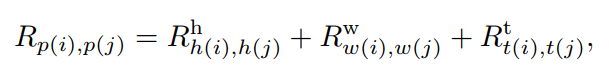
其中、、为沿高度、宽度和时间轴的位置嵌入,、和分别表示Token 的垂直、水平和时间位置。注意,这里的是可选的,仅在视频情况下需要支持时间维度。相比之下,分解嵌入将学习嵌入的数量减少到O(T+W+H),这对早期的高分辨率特征图有很大的影响。
2、池化残差连接
pooled attention对于减少注意力块中的计算复杂度和内存需求是非常有效的。MViT在K和V张量上的步长比Q张量的步长大,而Q张量的步长只有在输出序列的分辨率跨阶段变化时才下采样。这促使将残差池化连接添加到Q(pooled后)张量增加信息流动,促进MViT中pooled attention Block的训练和收敛。
在注意力块内部引入一个新的池化残差连接,如图4所示。具体地说,将pooled query张量添加到输出序列z中,因此将式(2)重新表述为:
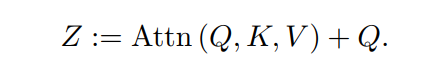
注意,输出序列Z与pooled query张量的长度相同。
消融实验表明,对于池化残差连接,query的pool运算符和残差路径都是必需的。由于上式中添加池化的query序列成本较低,因此在key和value pooling中仍然具有大跨步的低复杂度注意力计算。
3.2 MViT用于目标检测
1、改进版MViT融合FPN
MViT的层次结构分4个阶段生成多尺度特征图可以很自然地集成到特征金字塔网络中(FPN)为目标检测任务,如图5所示。在FPN中,带有横向连接的自顶向下金字塔为MViT在所有尺度上构建了语义的特征映射。通过使用FPN与MViT Backbone将其应用于不同的检测架构(例如Mask R-CNN)。
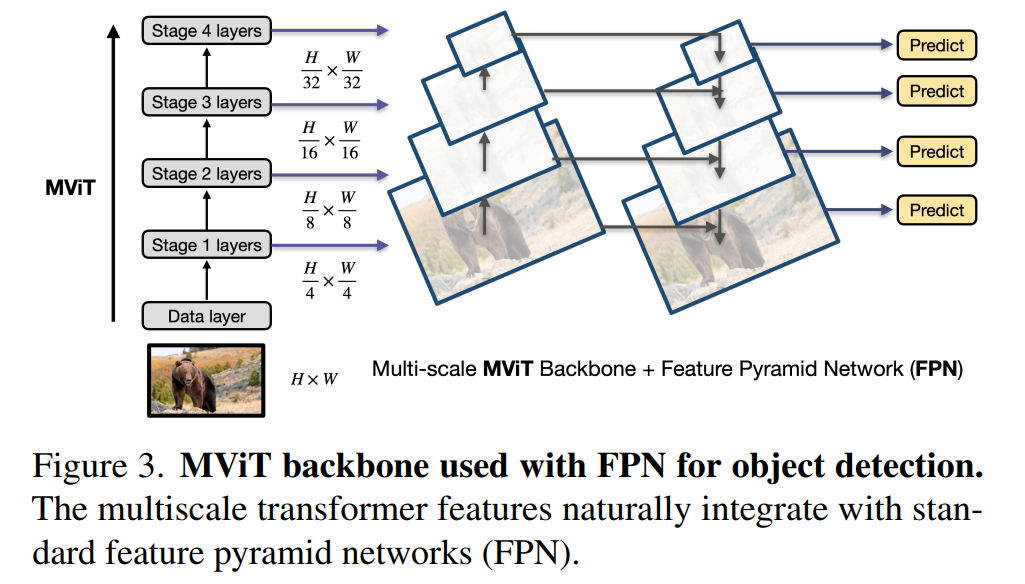 图5 融合FPN结构
图5 融合FPN结构2、Hybrid window attention
Transformers中的self-attention具有与token数量的二次复杂度。这个问题对于目标检测来说更加严重,因为它通常需要高分辨率的输入和特征图。在本文中研究了两种显著降低这种计算和内存复杂度的方法:
- 引入Pooling Attention
- 引入Window Attention
Pooling Attention和Window Attention都通过减少计算Self-Attention时query、key和value的大小来控制Self-Attention的复杂性。
但它们的本质是不同的:Pooling Attention通过局部聚合的向下采样汇集注意力池化特征,但保持了全局的Self-Attention计算,而Window Attention虽然保持了分辨率,但通过将输入划分为不重叠的window,然后只在每个window中计算局部的Self-Attention。
这两种方法的内在差异促使研究它们是否能够在目标检测任务中结合。
默认Window Attention只在Window内执行局部Self-Attention,因此缺乏跨window的连接。与Swin使用移动window来缓解这个问题不同,作者提出了一个简单的Hybrid window attention(Hwin)来增加跨window的连接。
Hwin在一个window内计算所有的局部注意力,除了最后3个阶段的最后块,这些阶段都馈入FPN。通过这种方式,输入特征映射到FPN包含全局信息。
消融实验显示,这个简单的Hwin在图像分类和目标检测任务上一贯优于Swin。进一步,将证明合并pooling attention和Hwin在目标检测方面实现了最好的性能。
3.3 MViT用于视频识别
1、从预训练的MViT初始化
与基于图像的MViT相比,基于视频的MViT只有3个不同之处:
- patchification stem中的投影层需要将输入的数据投影到时空立方体中,而不是二维的patch;
- 现在,pool运算符对时空特征图进行池化;
- 相对位置嵌入参考时空位置。
由于1和2中的投影层和池化操作符默认由卷积层实例化,对CNN的空洞率初始化为[8,25]。具体地说,作者用来自预训练模型中的2D conv层的权重初始化中心帧的conv kernel,并将其他权重初始化为0。
对于3利用在Eq.4中分解的相对位置嵌入,并简单地从预训练的权重初始化空间嵌入和时间嵌入为0。
4.4 MViT架构变体
本文构建了几个具有不同数量参数和FLOPs的MViT变体,如表1所示,以便与其他vision transformer进行公平的比较。具体来说,通过改变基本通道尺寸、每个阶段的块数以及块中的head数,为MViT设计了5种变体(Tiny、Small、Base、Large和Huge)。
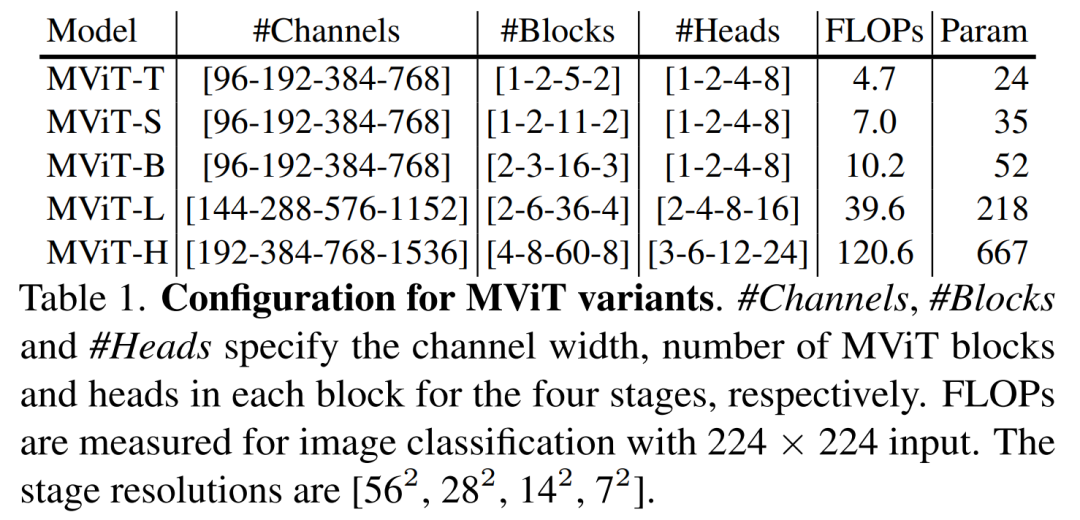
遵循MViT中的pooling attention设计,本文在所有pooling attention块中默认采用Key和Value pooling,pooling attention blocks步长在第一阶段设置为4,并在各个阶段自适应地衰减stride。
4实验
4.1 消融实验
1、不同的注意力机制
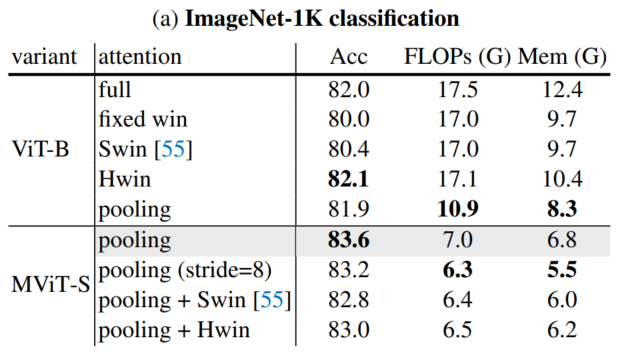
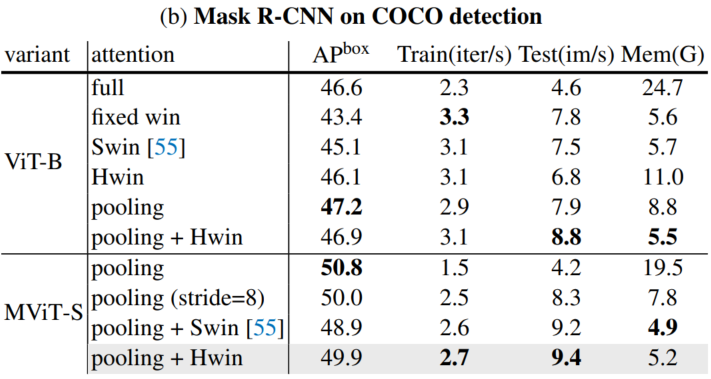
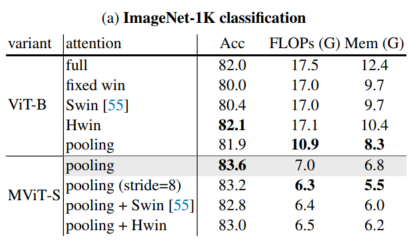
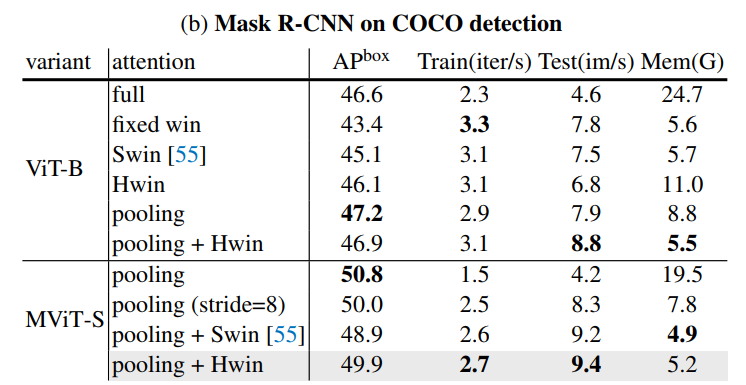
通过上表关于ImageNet分类和COCO目标检测的实验可以看出,本文提出的HSwin注意力与Pooling可以得到最好性能的结果。
2、位置嵌入
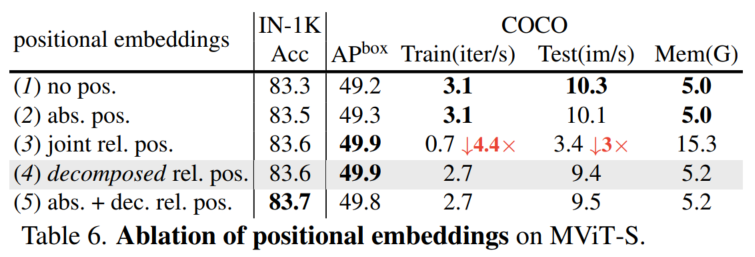
上表比较了不同位置嵌入。可以观察到:
- 比较(2)与(1),绝对位置仅比无位置略有提高。这是因为pool操作符已经建模了位置信息。
- (2)比较(3,4)和(1,2),相对位置通过引入转移不变性先验来Pooling Attention,从而带来收益。
- 最后,在COCO上分解的相对位置嵌入序列比joint相对位置快3.9倍。
3、池化残差连接
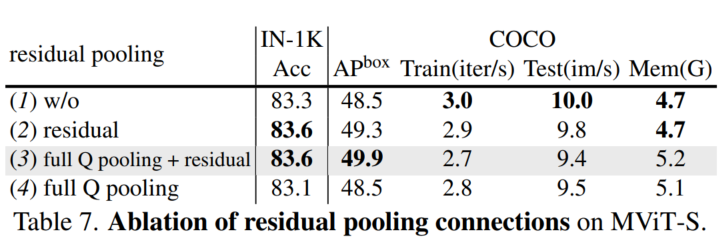
上表研究了池化残差连接的重要性。可以看到:
(2)简单地添加残差路径可以改善这两种情况的结果IN-1K(+0.3%)和COCO(+0.8 APbox)的成本可以忽略不计。
(3)使用池化残差连接,并在所有其他层中添加Q pooled(stride=1),性能得到显著的提升,特别是在COCO(+1.4 APbox)上。这表明在MViT中,Q pooled块和残差路径都是必要的。
(4)仅仅添加(没有残差)更多的Q pooled层stride=1没有帮助。
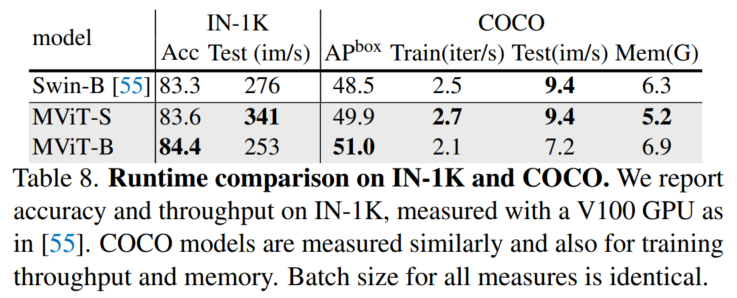
4、运行时间比较
5、FPN消融
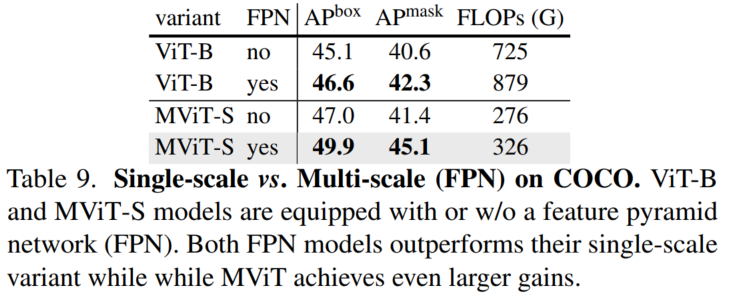
如表所示,FPN显著提高了两种Backbone的性能,而MViT-S始终优于ViT-B。MViT-S的FPN增益(+2.9)比ViT-B(+1.5 APbox)大得多,这表明了分层多尺度设计对于密集目标检测任务的有效性。
4.2 ImageNet-1K
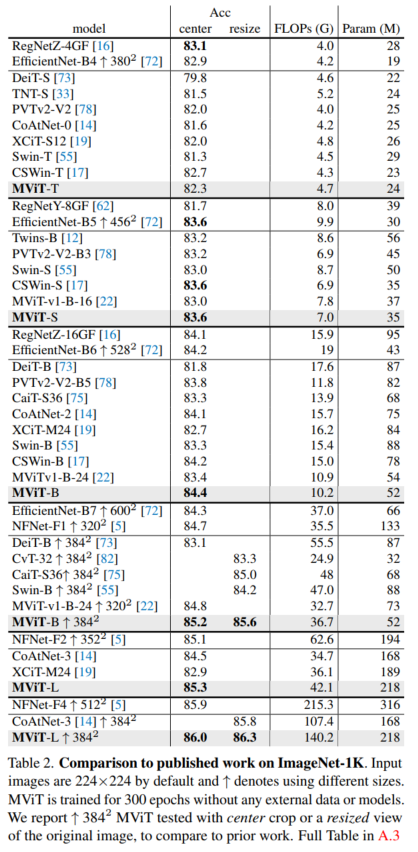
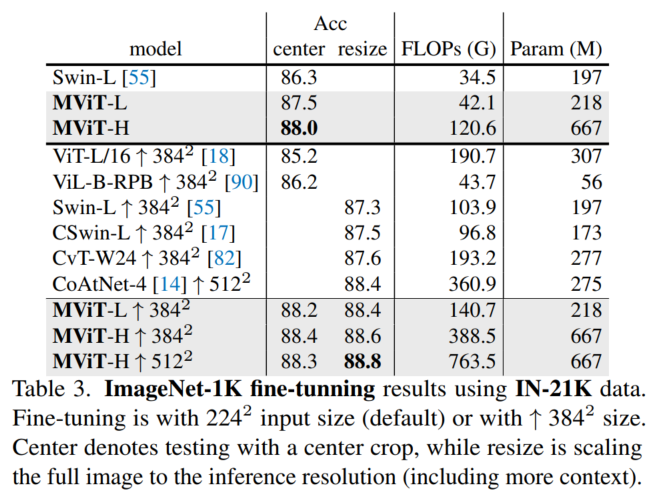
4.3 COCO目标检测
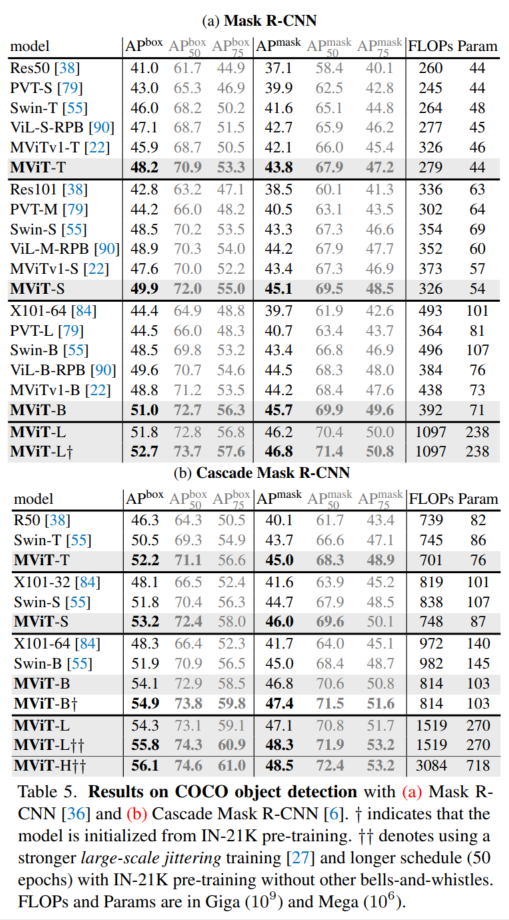
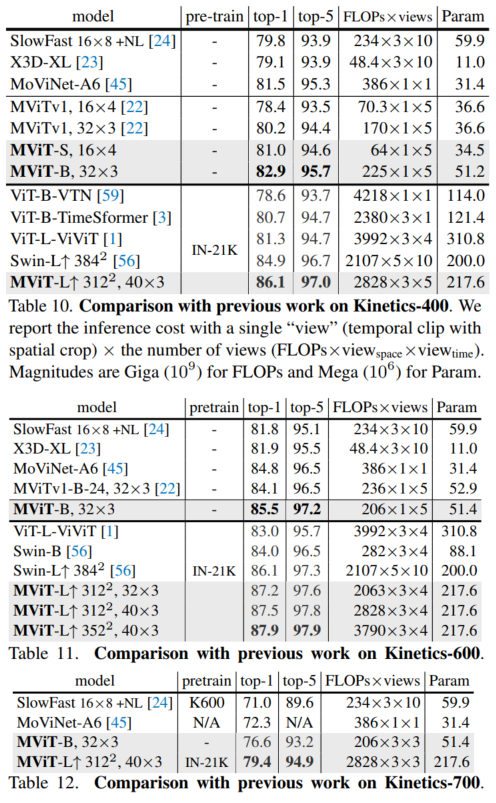
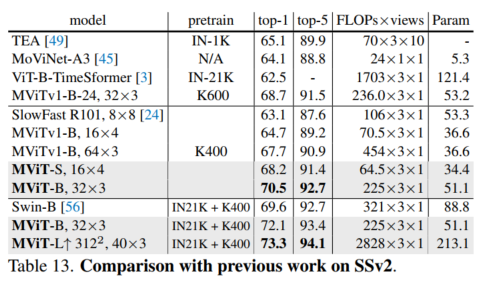
4.4 视频识别
5参考
[1].Improved Multiscale Vision Transformers for Classification and Detection
6推荐阅读

清华大学提出ACmix | 这才是Self-Attention与CNN正确的融合范式,性能速度全面提升

即插即用 | 5行代码实现NAM注意力机制让ResNet、MobileNet轻松涨点(超越CBAM)

卷爆了 | 看SPViT把Transformer结构剪成ResNet结构!!!
长按扫描下方二维码添加小助手并加入交流群,群里博士大佬云集,每日讨论话题有目标检测、语义分割、超分辨率、模型部署、数学基础知识、算法面试题分享的等等内容,当然也少不了搬砖人的扯犊子
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
