
某音 App protobuf 协议还原逆向分析
这是「进击的Coder」的第 703 篇技术分享作者:TheWeiJun来源:逆向与爬虫的故事
“
阅读本文大概需要 5 分钟。
趣味模块
小红是一名爬虫开发工程师,自从上次小红解决了字体反爬、websocket 协议、B 站 protobuf 协议后,小红一直所向披靡,过五关斩六将,在一个多月的时间里一直没有遇到过有难度的问题。但是今天,小红遇到了某音 App 端的 protobuf 协议加密,不再是 js 端一样去找定义的类型 id 了。那么今天我们去分析下小红同学遇到的新问题吧,如何通过无结构定义 proto 文件还原某音的 protobuf 协议!
一、什么是 protobuf 协议?
前言:Protobuf (Protocol Buffers) 是谷歌开发的一款无关平台,无关语言,可扩展,轻量级高效的序列化结构的数据格式,用于将自定义数据结构序列化成字节流,和将字节流反序列化为数据结构。所以很适合做数据存储和为不同语言,不同应用之间互相通信的数据交换格式,只要实现相同的协议格式,即后缀为 proto 文件被编译成不同的语言版本,加入各自的项目中,这样不同的语言可以解析其它语言通过 Protobuf 序列化的数据。目前官方提供 c++,java,go 等语言支持。
二、protobuf 堆栈输出
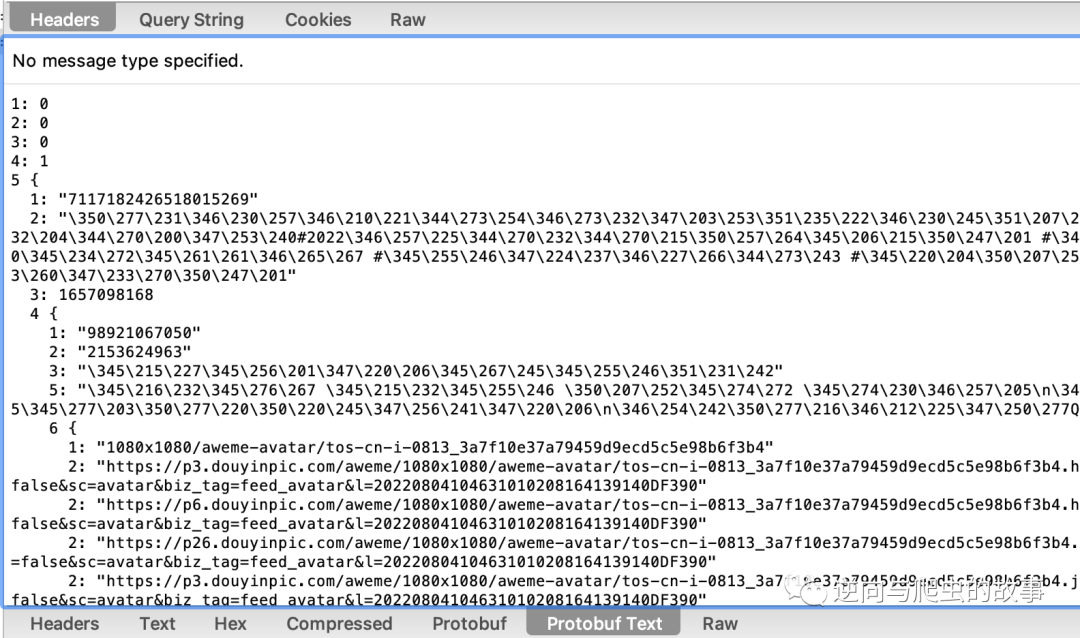
1、首先从 charles 应用中保存我们抓到的某音数据包,截图如下所示:
2、访问协议接口,将 response 响应内容保存为 .bin 格式文件,截图如下所示:
3、使用 protobuf_inspector python 第三方包打印 protobuf 文件堆栈信息,截图如下所示:
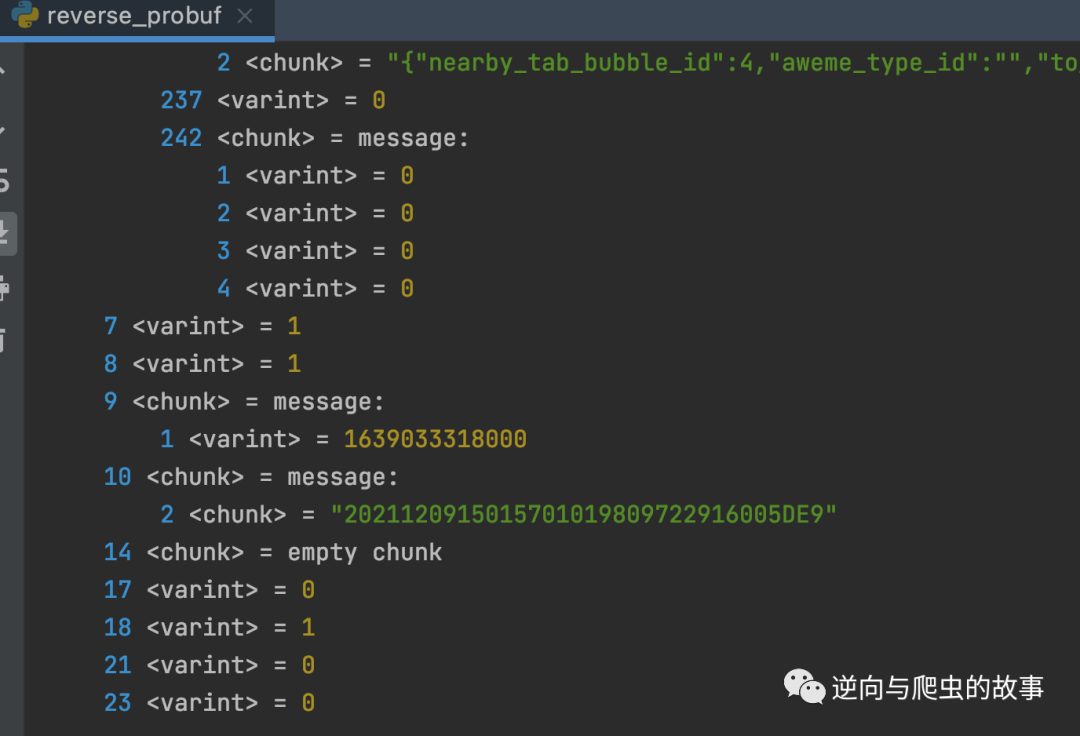
总结:打印 protobuf 数据堆栈信息后,接下来我们只需要根据打印的堆栈信息定义 proto id 类型文件并编译为 python 可执行文件即可完成对某音 protobuf 协议还原。
三、proto 文件定义及编译
1、通过分析打印的堆栈信息,确定我们本次要提取的文字内容,截图如下所示:
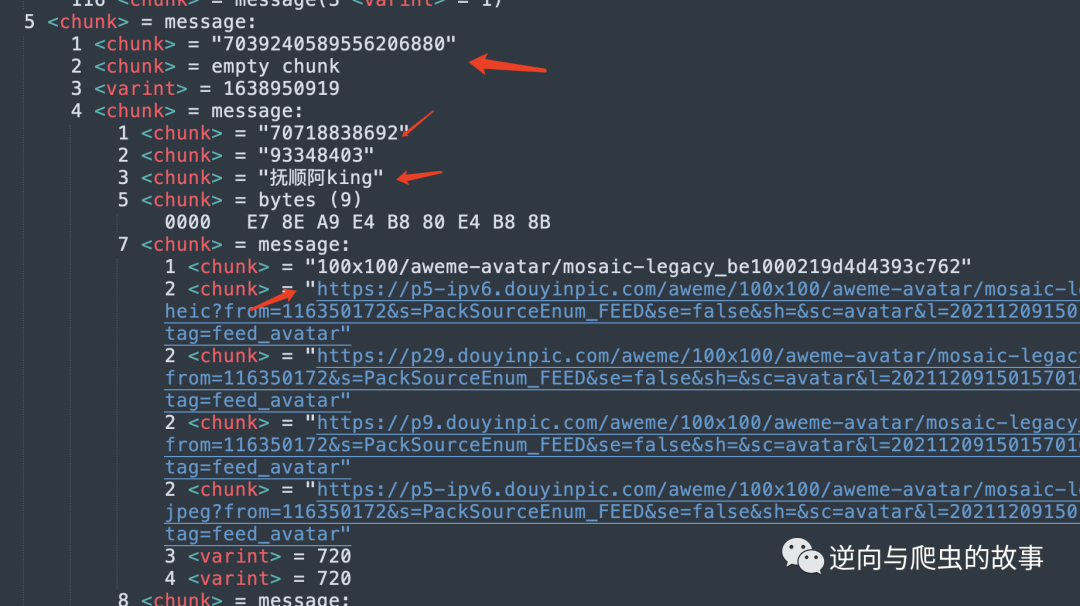
2、确定我们要提取的文字内容后,定义 proto 文件格式,定义后的结构体如下所示:
syntax = 'proto3';message FeedData {message Message{string url = 2;}message Info{string user_id = 1;string user_name = 3;repeated Message data = 7;}message FeedView{string item_id = 1;repeated Info info = 4;}repeated FeedView message = 5;}
3、执行如下命令,编译为 python protobuf 可执行文件:
protoc --python_out=. *.proto4、运行命令后,生成 python protobuf py 文件,截图如下所示:
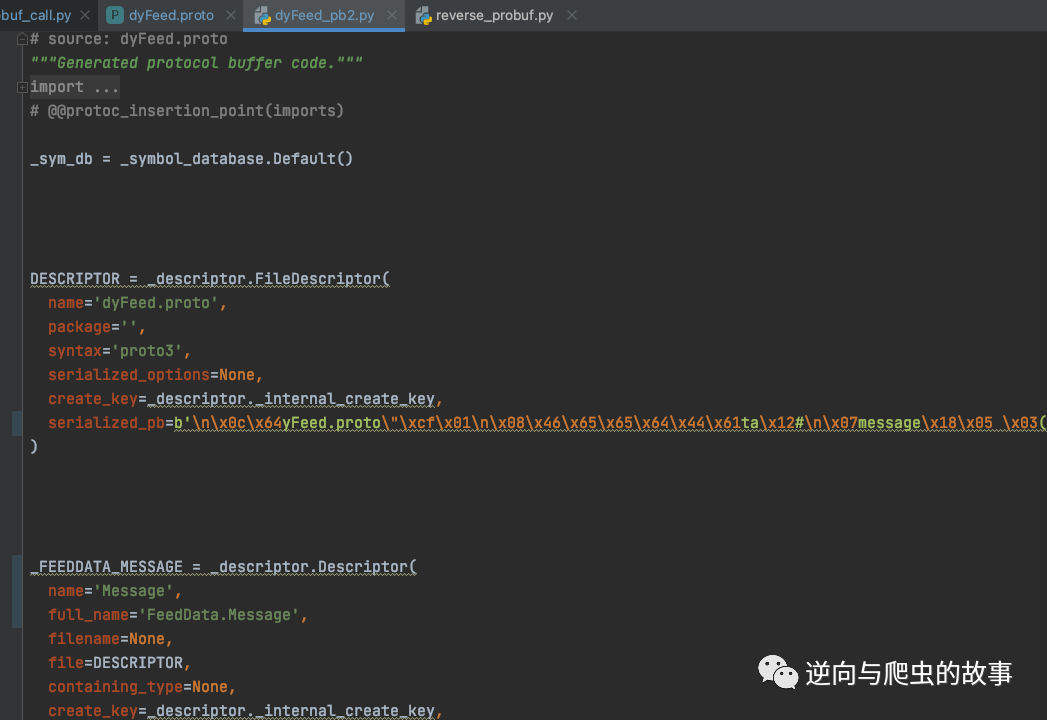
总结:走到这里 protobuf 协议就完全还原了,接下来让我们进入完整代码实现环节吧。
四、完整代码实现
1、整个项目完整代码实现如下:
from dyFeed_pb2 import FeedDatafrom google.protobuf.json_format import MessageToDictdef main():with open('feed2.bin', 'rb') as f:_info = FeedData()_info.ParseFromString(f.read())_data = MessageToDict(_info, preserving_proto_field_name=True)items = _data.get("message", [])for item in items:item_id = item.get("item_id")info = item.get("info")[0]user_id = info.get("user_id")user_name = info.get("user_name")icon = info.get("data")[0].get("url")print(item_id, user_id, user_name, icon)if __name__ == '__main__':main()
2、代码编写完成后,我们运行代码,代码输出截图如下所示:

五、心得总结分享
通过本次案例分享,我发现有些技术不是难,而是没有找到好的方案去解决;有的问题需要思考 3 个小时甚至更久,但是解决只需要 10 分钟。今天分享到这里就结束了,欢迎大家关注下期文章,我们不见不散⛽️

End
崔庆才的新书《Python3网络爬虫开发实战(第二版)》已经正式上市了!书中详细介绍了零基础用 Python 开发爬虫的各方面知识,同时相比第一版新增了 JavaScript 逆向、Android 逆向、异步爬虫、深度学习、Kubernetes 相关内容,同时本书已经获得 Python 之父 Guido 的推荐,目前本书正在七折促销中!
内容介绍:《Python3网络爬虫开发实战(第二版)》内容介绍

扫码购买
点个在看你最好看
