
Python 爬虫进阶必备 | 由某知识平台延伸的 Protobuf 协议分析学习
第一时间关注Python技术干货!
 图源:极简壁纸
图源:极简壁纸今日网站
aHR0cHM6Ly9zLndhbmZhbmdkYXRhLmNvbS5jbi9wYXBlcj9xPSVFNyU4OCVBQyVFOCU5OSVBQg==
Protobuf 协议的学习都没有搞过,今天写一个实例学习一下
什么是 ProtoBuf
先看 wiki 定义
Protocol Buffers(简称:ProtoBuf)是一种开源跨平台的序列化数据结构的协议。其对于存储资料或在网络上进行通信的程序是很有用的。这个方法包含一个接口描述语言,描述一些数据结构,并提供程序工具根据这些描述产生代码,这些代码将用来生成或解析代表这些数据结构的字节流。
ProtoBuf 目前有两个版本,主要是对支持的语言做了升级
版本间有哪些不同?
proto2提供一个程序产生器,支持 C++、Java 和 Python,第三方实现支持 JavaScript
proto3提供一个程序产生器,支持C++、Java(包含JavaNano)、Python、Go、Ruby、Objective-C 和 C# ,从 3.0.0 Beta 2 版开始支持 JavaScript。第三方实现支持Perl、PHP、Dart、Scala 和 Julia
proto3 支持语言更多,语法更简洁
简单来讲,protobuf 就是一种序列化数据结构的方法,支持多重编程语言使用模块包,对数据进行跨平台序列化传输
从开发角度学习 ProtoBuf
对于已经使用 protobuf 的逆向,用肉丝姐的话说,开发的高度决定逆向的高度,所以我们先看看这个 ProtoBuf 在开发中应该怎么用
先看下面的例子
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
repeated PhoneNumber phone = 4;
}
一个Message是一个包含一组类型字段的集合。包括bool,int32,float,double和string或者自己定义的结构来定义一个Message。
每一个类型字段前面必须要有一个修饰符包括:required、optional、repeated。
“1)required字段的初值是必须要提供的,否则该字段会被认为“未初始化的”,在序列化和反序列化的时候会报错!所以,对于修饰符为required的字段,务必进行初始化赋值。
2)对于optional的字段而言,如果未进行初始化,那么会有默认值赋值该字段
3)对于repeated的字段而言,该字段可以重复多个,在proto定义文件中可以使用repeated来修饰的字段类型,类似于一个数组,他可以包含多个数值。
同时要注意,如果使用proto3语法需要在开头使用syntax = "proto3";指定使用的版本
其他关于Protobuf开发更多的内容可以参考下面的两个资料
https://juejin.cn/post/6844903687089831944
https://developers.google.com/protocol-buffers/docs/proto3
理论讲完了,现在开始动手试试
环境配置
先下载一个protoc编译器
https://github.com/protocolbuffers/protobuf/releases
windows 下这个(按照版本自行选择)

下载解压后,可以在bin目录下找到protoc.exe这个文件
通过这个编译器我们可以完成以下操作
写入一个 protobuf,并生成对应的结构文件
按照上面的例子,我们写入一个 protobuf 结构,并命名为demo.proto
syntax = "proto3";
message Person {
string name = 1;
int32 id = 2;
string email = 3;
int32 phone = 4;
}
然后借助protoc.exe去生成对应的 python 结构文件
# 命令为 .\protoc.exe --python_out=[python path] [proto path]
.\protoc.exe --python_out=. ./demo.proto

生成的文件为demo_pb2.py
通过结构文件输出指定 protobuf 内容
打开编辑器,新建一个python文件,导入刚刚生成的demo_pb2这个文件
写入以下代码
import demo_pb2
person = demo_pb2.Person()
person.name = "xianyuplus"
person.id = 9527
person.email = "xxxx@qq.com"
person.phone = 1841234
print(person.SerializeToString())
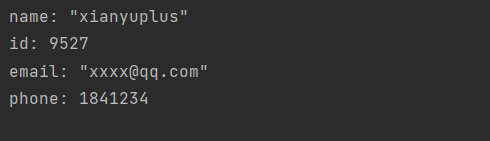
输出结果如下

这样我们就按照 protobuf 模版写入了自定义内容的数据
读取 protobuf 文件输出内容
在上一步操作中我们可以将输出的内容保存为xianyu.bin文件
# 写入 protobuf 文件
with open('xianyu.bin','wb') as f:
f.write(person.SerializeToString())
print(person)
之后再读取出来
# 读取 protobuf 文件
with open('xianyu.bin','rb') as f:
person.ParseFromString(f.read())
print(person)
结果如下
这样我们就完成了protobuf文件的读取
到这里,我们就完成了protobuf开发部分的学习,接下来进入逆向的部分
用开发的知识辅助逆向
打开今天的网站,我们需要分析的请求如下
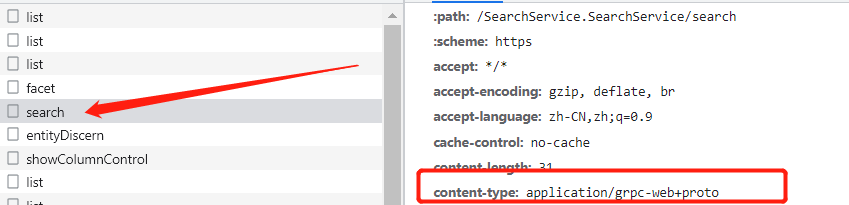
可以看到content-type指定了application/grpc-web+proto
提交的内容如下

我们想要得出这样的结果,首先应该找到提交这个参数的位置,通过网站的代码复写出提交参数的protobuf的结构文件
定位参数大家应该都很熟了
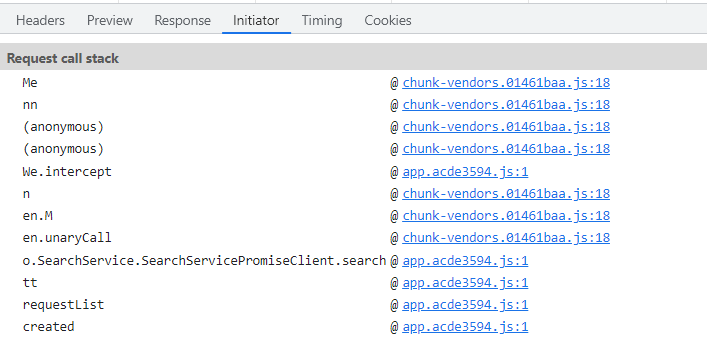
通过分析js调用栈,我们定位到下面的位置
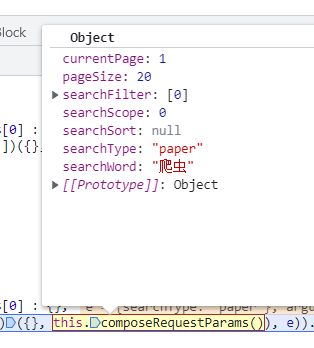
这里就是提交的参数
而下面返回的e就是请求返回的数据


现在找到了请求和返回的位置,现在开始构建参数的protobuf结构文件的构建
请求参数的 protobuf 结构构建
通过上面这张图可以得出现有的文件结构
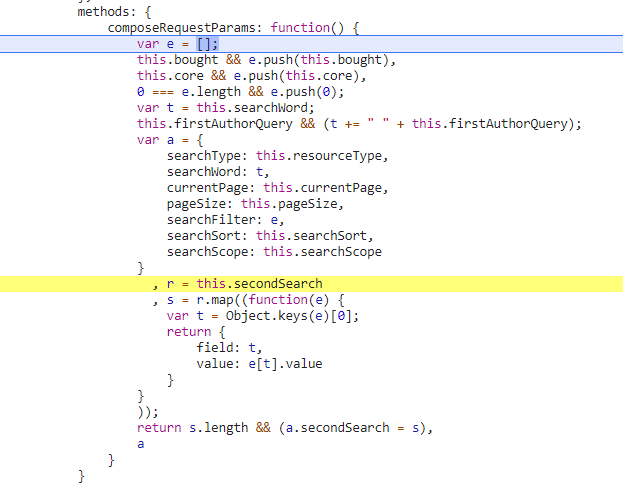
这个参数整体是一个 object,其中searchFilter是一个列表,其他的就是常用的数据类型
由上可以得出下面的 protobuf 文件
syntax = "proto3";
message SearchParams {
enum SearchFilter {
frist = 0;
}
message Params {
string searchType = 1;
string searchWord = 2;
int32 currentPage = 3;
int32 pageSize = 4;
int32 searchScope = 5;
// 对于repeated的字段而言,该字段可以重复多个,在proto定义文件中可以使用repeated来修饰的字段类型,类似于一个数组,他可以包含多个数值。
repeated SearchFilter searchFilter = 6;
}
message SearchRequest {
Params params = 1;
}
}
通过.\protoc.exe --python_out=. ./demo_wanfang_protobuf.proto生成 python 文件
新建一个 python 文件,通过 protobuf 传入指定的参数
import requests
import demo_wanfang_protobuf_pb2 as pb
search = pb.SearchParams.SearchRequest()
search.params.searchType = "paper"
search.params.searchWord = '爬虫'
search.params.searchScope = 0
search.params.currentPage = 1
search.params.pageSize = 20
search.params.searchFilter.append(0)
data = search.SerializeToString()
再带入 request 就可以获取到请求的结果了
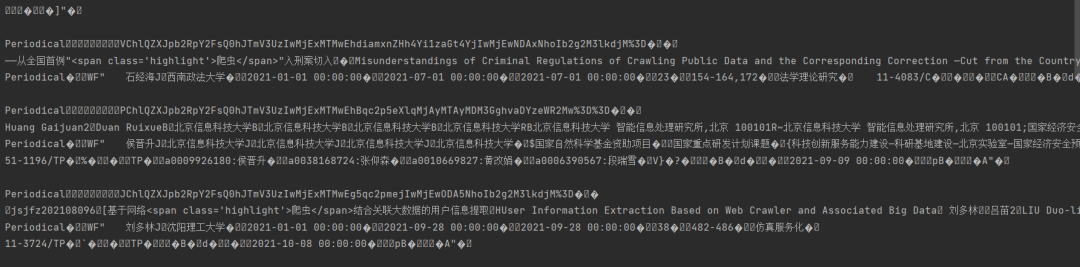
这个时候就有个问题,我们应该如何解析请求返回的数据呢?
可以看到返回的数据的字段可比提交的参数字段多得多
这个时候就要推荐一个库blackboxprotobuf
关于他的使用,就比上面我们直接使用编译器编译结构文件再构建数据结构要轻松的多
blackboxprotobuf 的安装
pip install blackboxprotobuf
坑点
大家安装blackboxprotobuf的时候记得切换到虚拟环境中安装
在文章开始的地方,我们使用的编译器对应的protobuf版本是3.19,但是blackboxprotobuf最后一版都更新是在2020年,支持的protobuf版本为3.10

安装blackboxprotobuf会将protobuf降级为3.10,如果在同一环境中安装会导致原有生成得 python proto 结构文件无法使用且会报错。
blackboxprotobuf 的简单使用
上面说了坑点,但是使用blackboxprotobuf真的方便,比如在文章开始的部分我们写入了一个protobuf文件,使用blackboxprotobuf直接读取出来
那我们请求出来的数据不也。。
import blackboxprotobuf
with open(r"./xianyu.bin", "rb") as fp:
data = fp.read()
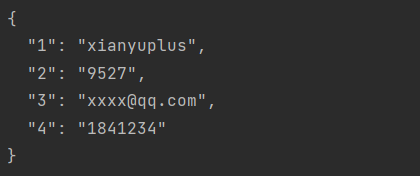
message, typedef = blackboxprotobuf.protobuf_to_json(data)
print(message)
除了上面的使用外,还有更多的使用网上的资料非常的多,大家自行搜索就好
通过 blackboxprotobuf 可以很方便把返回的数据解析出来,唯一需要注意的就是上面说的安装问题
更多 protobuf 以及 blackboxprotobuf 参考资料:
https://blog.csdn.net/weixin_43411585/article/details/121301297
https://www.cnblogs.com/silence-cho/p/14544004.html
好了,以上就是今天的全部内容了。
我是没有更新就在摸鱼的咸鱼
收到请回复~
我们下次再见。
 对了,看完记得一键四连,这个对我真的很重要。
对了,看完记得一键四连,这个对我真的很重要。