
每个人都能听懂你的话:Google 为语言障碍者开发专属ASR模型,错误率下降76%

新智元报道
新智元报道
来源:Google AI
编辑:LRS
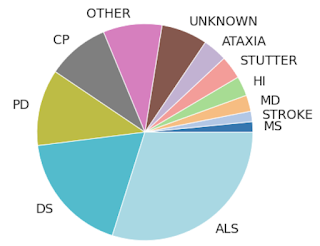
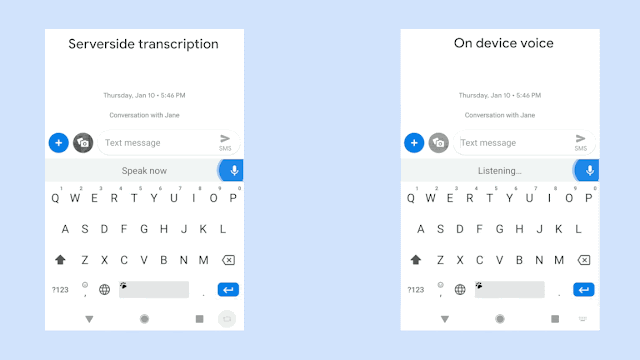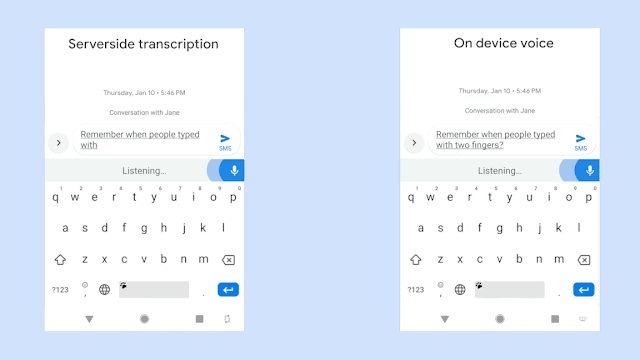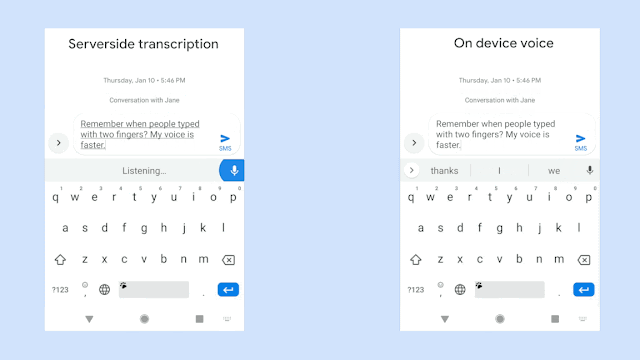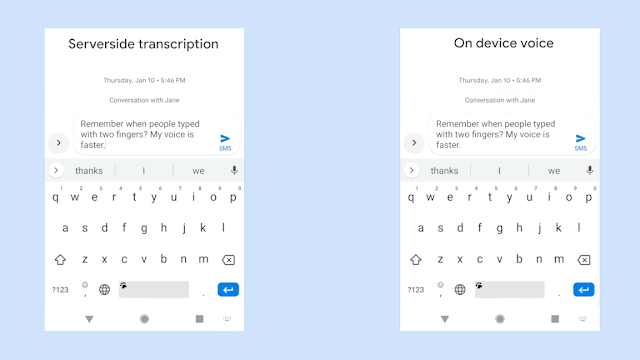
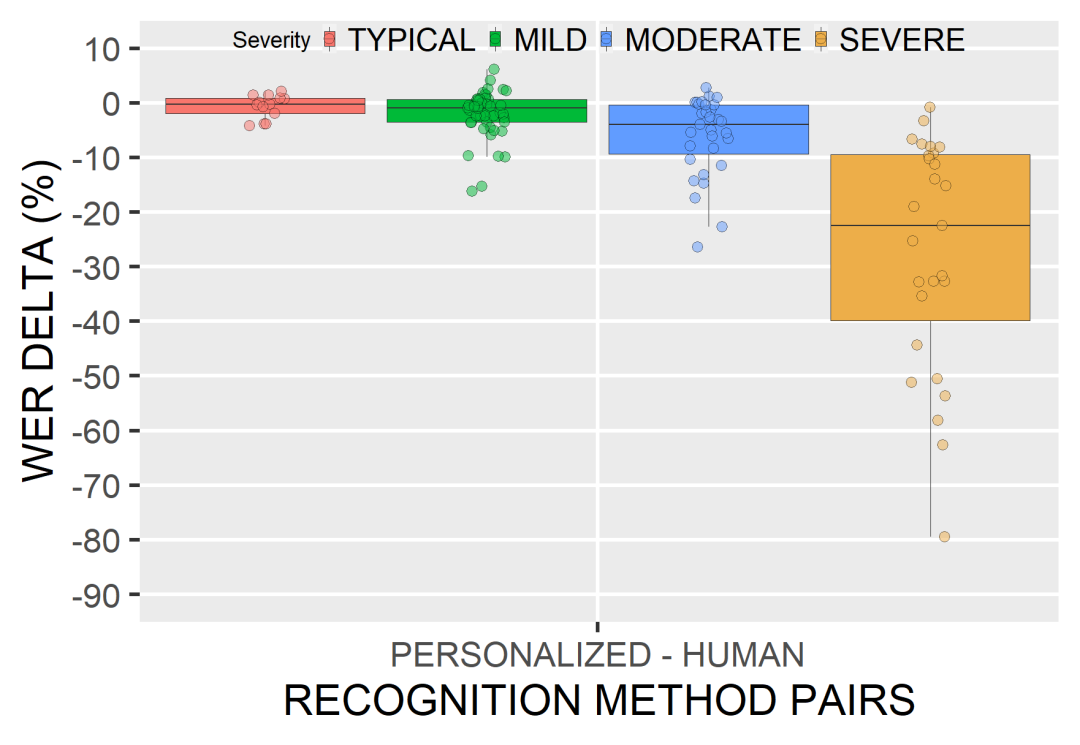
【新智元导读】在AI时代,残障人士也受到了更多来自技术上的关怀,例如专属的聊天训练机器人、手语翻译机器、自闭症患者VR训练等等,最近Google针对语言障碍人士开发了专属的语音识别模型,让你说的话可以被更多人听懂!





参考资料:
https://ai.googleblog.com/2021/09/personalized-asr-models-from-large-and.html

评论