
用随机森林预测“美版拼多多”商品销量

作者:Andrew Udell
翻译:王闯(Chuck)、校对:廖倩颖
基于Kaggle上的Wish数据集,这篇文章用Python演示了随机森林回归预测商品销量的方法,对于读者分析和解决此类问题是很好的借鉴。
数据集
数据导入和清理
import pandas aspdimport numpy as np# import the data saved as a csvdf = pd.read_csv("Summer_Sales_08.2020.csv")
df["has_urgency_banner"] = df["has_urgency_banner"].fillna(0)df["discount"] = (df["retail_price"] - df["price"])/df["retail_price"]
df [“ rating_five_percent”] = df [“ rating_five_count”] / df [“ rating_count”]df [“ rating_four_percent”] = df [“ rating_four_count”] / df [“ rating_count”]df [“ rating_three_percent”] = df [“ rating_three_count“] / df [” rating_count“]df [” rating_two_percent“] = df [” rating_two_count“] / df [” rating_count“]df [” rating_one_percent“] = df [” rating_one_count“] / df [” rating_count“]
ratings = ["rating_five_percent","rating_four_percent","rating_three_percent","rating_two_percent","rating_one_percent"]for rating in ratings:df[rating] = df[rating].apply(lambda x: x if x>= 0 and x<= 1 else 0)
数据探索
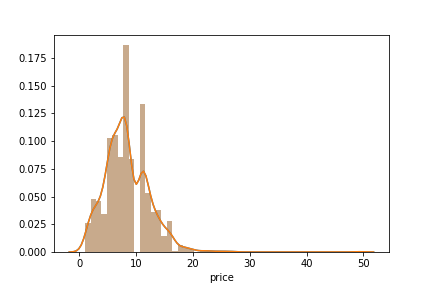
import seaborn as sns# Distribution plot on pricesns.distplot(df['price'])
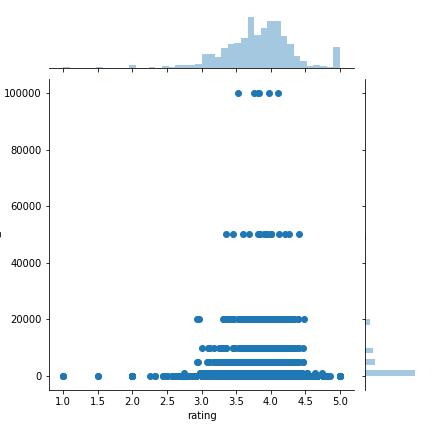
sns.jointplot(x =“ rating”,y =“ units_sold”,data = df,kind =“ scatter”)
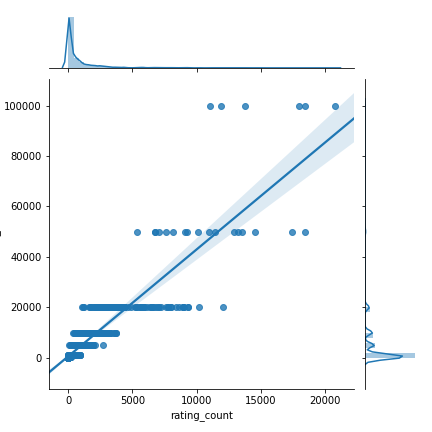
sns.jointplot(x =“ rating_count”,y =“ units_sold”,data = df,kind =“ reg”)
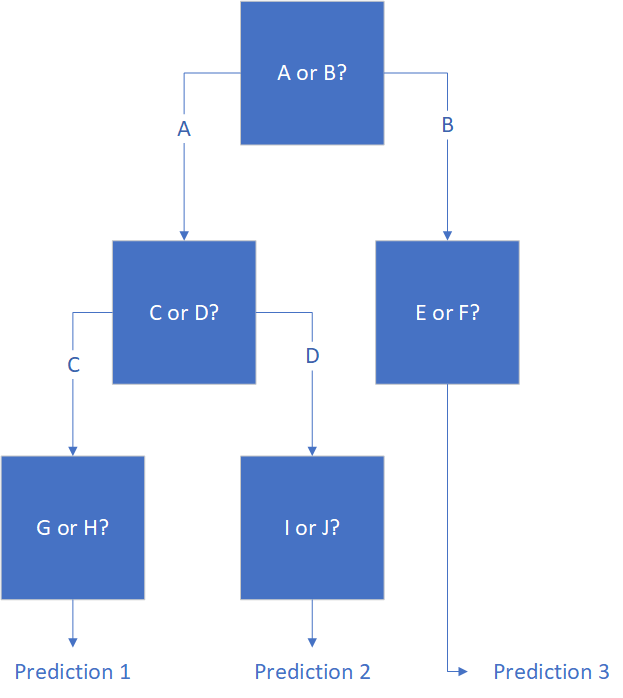
什么是随机森林回归?
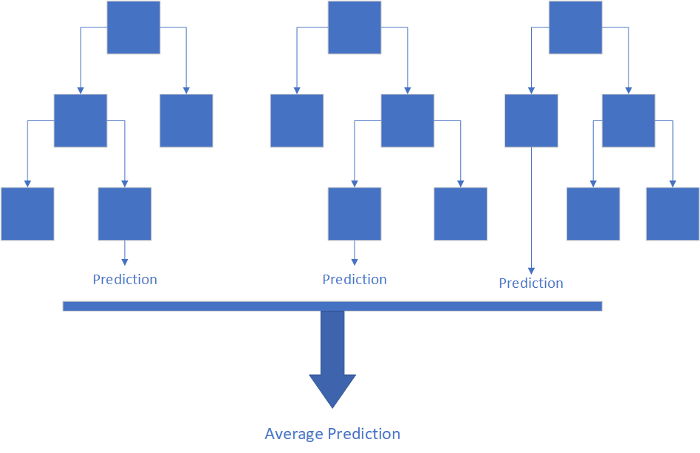
随机森林回归的实现
from sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestRegressor# Divide the data between units sold and influencing factorsX = df.filter(["price","discount","uses_ad_boosts","rating","rating_count","rating_five_percent","rating_four_percent","rating_three_percent","rating_two_percent","rating_one_percent","has_urgency_banner","merchant_rating","merchant_rating_count","merchant_has_profile_picture"])Y = df["units_sold"]# Split the data into training and testing setsX_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.33, random_state = 42)
# Set up and run the modelRFRegressor = RandomForestRegressor(n_estimators = 20)RFRegressor.fit(X_train, Y_train)
# Set up and run the modelRFRegressor = RandomForestRegressor(n_estimators = 20)RFRegressor.fit(X_train, Y_train)
总结
原文链接:
https://towardsdatascience.com/predicting-e-commerce-sales-with-a-random-forest-regression-3f3c8783e49b
评论